


























Introduction
Having a faster computer isn't enough to assure adequate performance when dealing with large amounts of data. You'll need to be able to spread your big data service's components over several nodes.
- A node is an element housed inside a cluster of systems or within a rack in distributed computing.
- A node usually consists of a CPU, memory, and a disc. On the other hand, a node can be a blade CPU and memory that is dependent on adjacent storage within a rack.
Source
- These nodes are frequently grouped in a big data environment to offer scale. For instance, you may begin with an extensive data analysis and gradually add more data sources.
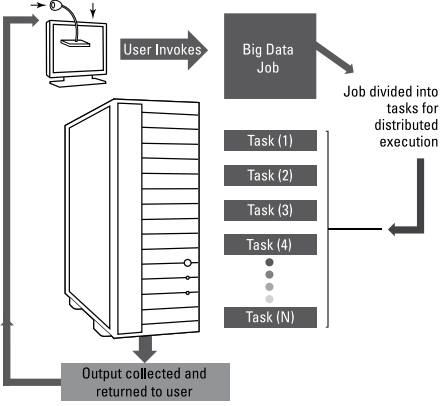
- An organization simply adds additional nodes to a cluster to accommodate the expansion, allowing it to scale out to meet new demands. However, increasing the number of nodes in the cluster isn't enough. Instead, the ability to transfer parts of the extensive data analysis to diverse physical contexts is critical. Where you assign these tasks and how you handle them determines whether they are successful or not.
Distributed Computing
There is no one distributed computing model today, and computer resources can be dispersed in a number of ways. You can, for example, distribute a group of programs on the same physical server and use messaging services to allow them to communicate and transmit data amongst each other. To solve the same problem, numerous different systems or servers can be combined, each with its own memory.
Scalability
To reach the speed of analysis necessary in some complicated circumstances, you may need to run many algorithms in parallel, even inside the same cluster. Why would you use the same rack to run several big data algorithms simultaneously? The closer the function distributions are, the faster they can run. Although you may deploy big data analysis across networks to use available capacity, you must do it depending on performance needs. Processing speed takes a back place in some cases. In other cases, though, immediate findings are required. You'll want to make sure that the networking functions are close to one other in this instance. The big data environment should be suited for this sort of analytics activity.
- As a result, scalability is critical to successfully implementing big data.
- Although it is theoretically conceivable to run a big data environment within a single large environment, this is not feasible. Look at cloud scalability and grasp both the criteria and the technique to understand the demands for scalability in big data.
- Big data, like cloud computing, need fast networks and low-cost hardware clusters that can be stacked in racks to boost performance.
- Software automation allows for dynamic scaling and load balancing in these clusters.
MapReduce's concept and implementations illustrate how distributed computing can make massive data operationally transparent while also improving performance. In essence, we are at one of computing's rare turning points, where technical concepts collide at the right time to tackle precisely the right challenges. Data management is evolving dramatically due to the combination of distributed computing, enhanced hardware systems, and practical solutions like MapReduce and Hadoop.


 6+ registered
6+ registered 

