


























Introduction
Gradient boosting is a technique that is gaining popularity because of its speed and accuracy in predicting vast and complex data.
The Gradient Boosting algorithm, which operates on the boosting technique, will be discussed in this article. First of all, let’s have a brief idea about boosting.
Few essential words that you should know about.
Ensemble
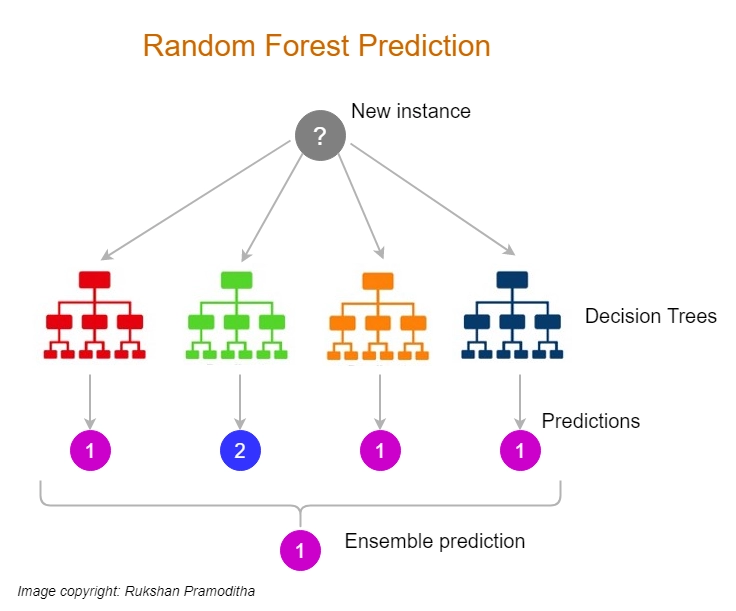
A machine learning ensemble is a model that integrates the predictions of two or more models. Ensemble members are models that contribute to the ensemble. They might be the same kind of different types, and they may or may not have been trained on the same training data.
Learning rate and n_estimators
Shrinkage is a gradient-boosting regularisation process that aids in modifying the update rule, which is supported by the learning rate parameter. The usage of learning rates below 0.1 results in considerable improvements in a model's generalization.
Hyperparameters are essential components of learning algorithms that influence a model's performance and accuracy. Two key hyperparameters for gradient boosting decision trees are learning rate and n estimators. The learning rate abbreviated as 𝞪 simply refers to how quickly the model learns. Each tree that is added to the model changes the overall model. The learning rate determines the magnitude of the change. The slower the model learns, the lower the learning rate.
Must Recommended Topic, Generalization in DBMS
Boosting
Boosting in machine learning is an ensemble learning strategy for minimizing training errors by merging a collection of weak learners into strong learners. A random sample of data is chosen, fitted with a model, and then trained progressively in boosting—that is, each model attempts to compensate for the shortcomings of its predecessor. Each iteration integrates the weak rules from each classifier to produce a single, strong prediction rule.
Types of Boosting
During the sequential process, different boosting algorithms can create and aggregate weak learners differently. There are three common types of boosting techniques:
- Adaptive boosting(Adaboost)-This approach works in stages, recognizing and changing the weights of misclassified data points to reduce the training error. The model is optimized stepwise until the most robust predictor is found.
- Gradient boosting: This approach works by adding predictors to an ensemble in a sequential manner, with each one correcting for the mistakes before it. Unlike AdaBoost, which adjusts data point weights, gradient boosting trains on the residual errors of the preceding predictor.
- Extreme gradient boosting(XGBoost): XGBoost is a gradient boosting system optimized for computing speed and scale. XGBoost takes advantage of the CPU's many cores, allowing concurrent learning during training.
So basically Gradient boosting machine is an approach where we use the previous errors, and each predictor is taught using the predecessor's residual mistakes as labels.
Let’s take the example of an ensemble of N trees. In this method for the first tree, we’ll train it using X feature matrix and y labels. Now for training tree 2, we’ll use X feature matrix and training set residual R1 as labels. Now, this process continues until we have trained the Nth tree.
So we can predict the final result,
y(pred)= y1+(𝞪*R1)+(𝞪*R2)+.......+(𝞪*RN)
GradientBoostingRegressor is the scikit-learn class for gradient boosting regression. GradientBoostingClassifier is a classification algorithm that uses a similar approach.
Implementation in Python
# Import utility functions
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error as MRSE
from sklearn import dataset
# Setting SEED to initialize the random number generator
SEED = 1
# Importing the dataset
vehicle = dataset.load_bike()
x, Y = vehicle.data, vehicle.target
# Splitting dataset in 0.25
tr_X, ts_X, tr_Y, ts_Y = train_test_split(x, Y, test_size = 0.25, random_state = SEED)
# Calling Gradient Boosting Regressor
grb = GradientBoostingRegressor(n_estimators = 200, max_depth = 1, random_state = SEED)
# Fit to training set
grb.fit(tr_X, tr_Y)
# Predict on test set
pred_y = gbr.predict(ts_X)
# test set Root mean square deviation
test_rmse = MRSE(ts_y, pred_y) ** (1 / 2)
# Print root mean square deviation
print('RMSE test set: {:.2f}'.format(test_rmse))
Output
RMSE test set: 4.01 Also Read, clustering in machine learning


 9+ registered
9+ registered 

