Do you think IIT Guwahati certified course can help you in your career?
Introduction
Gradient Descent is the most helpful optimization technique used in Machine Learning and Deep Learning. Gradient means the slope of the surface,i.e., rate of change of a variable concerning another variable.
So basically, Gradient Descent is an algorithm that starts from a random point of the curve and descends the slope until it reaches the optimal minimum value. When the slope is far from zero, the algorithm takes significant steps, taking baby steps closer to zero.
Gradient descent refers to an optimization algorithm that follows the negative of the gradient declining of the target function to locate the optimal minimum of the function. Thus gradient descent helps us find the optimal weights of a neural network.
The main issue with gradient descent is that the weight update depends on the learning rate and gradient at that moment. It doesn't consider the past steps taken while traversing the cost space.
Issue With Gradient Descent
The cost function gradient at saddle points( plateau) is negligible, leading to small or insignificant weight updates. Hence, the network becomes stagnant, and the learning stops.
The path followed by Gradient Descent is too stressed even when operating with mini-batch mode.
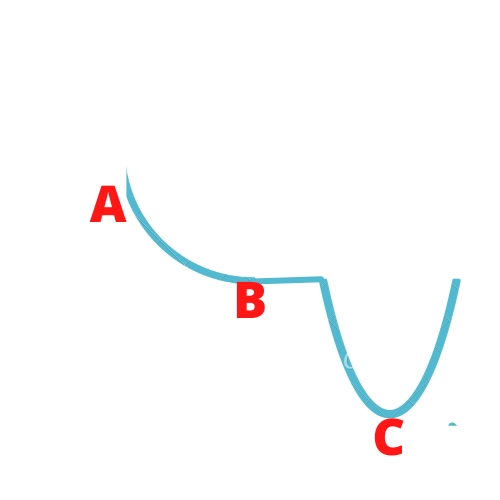
Let's take an example. Let's assume the weights of the network correspond to point A. The loss function decreases rapidly along with the slope AB as it has a steep slope with gradient descent. But soon as it reaches point B, the slope becomes negligible. The weight changes around B are not significant. As the region next to the point is flat, even after many iterations, the cost moves negligibly, getting stuck at a point where the gradient eventually becomes zero.
In this case, ideally, the cost function should have moved to the global minima at point C, but because the slope disappears at point B, we are stuck with a sub-optimal solution.
The main issue with the gradient descent is that it takes a lot of time to traverse around a gentle slope because the gradient at this point is too small or negligible.
Solution: How can momentum solve this issue??
Suppose we release a ball from point A, rolling down, before reaching point B. It will gather some inertia or momentum, enough to cross the flat region post B and finally roll down along slope BC to achieve the optimal minima. We can apply the same momentum concept on gradient descent to overcome earlier issues.
Before applying momentum on gradient descent, let us have a look at what is momentum?
Momentum
Let us suppose, if we are repeatedly being asked to move in the same direction, then we should probably gain some confidence and start taking more significant steps in that direction, just as in the case where a ball gains momentum while rolling down a slope as explained above.
Thus, in the case of gradient descent, momentum is an extension of the gradient descent optimization algorithm, which is generally referred to as gradient descent with momentum. Momentum is designed to boost the optimization process,i.e., decreasing the number of iterations to reach the optimal minima or increasing the algorithm's capability to provide a much better result.
The issue with the gradient descent, as explained above, can slow down the process of the search, especially for those optimization problems where the broader trend or shape of the search space is more valuable than specific gradients along the way.
How can we apply momentum to Gradient Descent?
We can use a statistical concept to describe momentum,i.e., moving average over the past gradients. In regions where the slope is high, like AB, weight updates will be significant. Thus, in a way, we are gaining momentum by taking a moving average over these gradients. But the major problem with this method, that it considers all the gradients over iterations with equal weightage. The gradient at any iteration has equal weightage as the current one. So to fix this, we need to use some weighted average of the past gradients to give more weightage to the recent gradients.
We can resolve this issue using an Exponential Moving Average(EMA). An exponential moving average is a statistical concept to calculate the moving average that assigns a greater weight to the most recent values.
Vt = the new weight update at iteration t or the value of EMA at time t.
𝝱 = Momentum constant represents the degree of increase in weightage, and the value lies between 0 to1.
St = gradient at any time t.
Let us expand the equation of EMA to deduce some results:
Thus from the above final equation, it is clear that the new weight update depends upon the past values one to t of original sequence S. As we know, the value of beta lies between 0 to 1. Hence, the past values of S have less influence over the current weight update, as any positive number raised to the power of beta will be less than the current beta, so the weightage of past values of S keeps on decreasing. It is more clear from the above equation. We can also approximate the importance of weight update, like when the weight value is less than 1/e, we can neglect the rest of the terms, as the value less than 1/e is too negligible to consider. Thus, that's EMA for you.
The ideal value of 𝜷
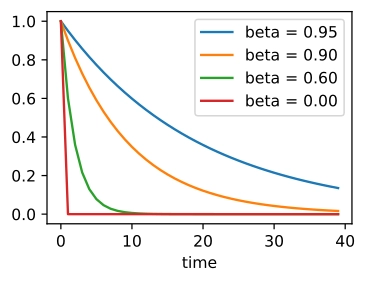
As we saw above, the value of a gradient depends on the power factor of beta (𝝱*S(t)). So, if we choose the smaller beta value, the gradient will vanish more rapidly, so fewer gradients would influence the gradient update. In contrast, in the case of a significant value of beta-like 0.9, the gradients won't vanish rapidly, so more gradients would influence the weight update, which is the ideal case. Let us take an example for more clear understanding,
Case 1: β=0.1
At n=3, the gradient value at t =3 will donate 100% of its value, the gradient at t=2 will donate 10% of its value, and the gradient at t=1 will only contribute 1% of its value.
Here contribution from earlier gradients decreases rapidly.
Case 2: β=0.9
At n=3; the gradient value at t =3 will donate 100% of its value, t=2 will donate 90% of its value, and gradient at t=1 will donate 81% of its value.
So we can see, a significant value of 𝝱 provides more weightage to the past values of gradients.
The following graphs show how fast weights get smaller with past values of S if we keep the threshold close to 0.3; after 0.3, we forget all the importance of the gradients.
Why Momentum Works??
Momentum solves the issues faced by the gradient descent:
Firstly, if all the past gradients are positive, like in the case of curve AB, the summation of past weights will be large enough to provide enough acceleration to cross the curve BC, even if the learning rate is low. We will take significant steps for weights updating. This solves our first issue where the gradient vanishes post B in the flat area.
Secondly, suppose that some of the past gradients are negative. The weight update will have a smaller value. If the learning rate is high enough, it will oscillate around C. The gradient will have positive and negative gradients. After a few oscillations, the sum of past gradients will become smaller, thus making minor updates on weights and ultimately converging at point C.
In conclusion, gradient descent with momentum takes significant steps when the gradient vanishes around the flat areas and takes smaller steps in the direction where gradients oscillate, i.e., it minimizes exploding gradient descent.
Frequently Asked Question
What is the purpose of the momentum term in gradient descent? The momentum term improves the speed of convergence of gradient descent by bringing some eigen components of the system closer to critical damping.
What is good momentum from gradient descent? Beta is another hyper-parameter that takes values from 0 to one. It is generally preferred to use beta 0.9 above. It is a good value and is most often used in SGD with momentum.
How does the momentum affect the neural network? Momentum helps neural networks to get out of local minima so that a more optimal global minimum is found. Too much momentum may create issues as they oscillate and grow in magnitude.
Key Takeaways
Let’s brief the article.
Firstly, we saw the issues faced by the gradient descent and how applying momentum overcomes the problems. Then, we saw how we could apply momentum with gradient descent and the ideal value of the hyperparameter 𝝱.
Even though gradient descent converges better and faster, it still doesn’t resolve all the problems. First, the learning rate has to be tuned manually. Second, in some cases where even if the learning rate is low, the momentum term and the current gradient can cause oscillations.
Firstly, the Learning rate issue can be resolved by using other variations of Gradient Descent like AdaptiveGradient and RMSprop. Secondly, a significant momentum problem can be further determined by using a variation of momentum-based gradient descent called Nesterov Accelerated Gradient Descent.
That’s the end of the article. I hope you like it. Stay tuned for more exciting articles.



























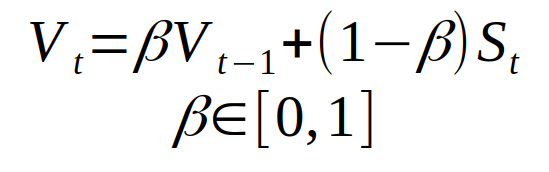



 8+ registered
8+ registered 

