Get a skill gap analysis, personalised roadmap, and AI-powered resume optimisation.
Introduction
In our digital age, the explosion of data has led to groundbreaking innovations in how we store, process, and analyze vast amounts of information. One such technological marvel is Hadoop, a framework that revolutionizes data handling, offering robust solutions for managing big data. In this article, we'll explore the intricate architecture of Hadoop, including its core components: MapReduce, HDFS, YARN, and Common Utilities.
By the end of this exploration, you'll have a comprehensive understanding of Hadoop's architecture and how each component plays a pivotal role in efficient data management.
History of Hadoop
Hadoop, an open-source framework developed by the Apache Software Foundation, has a rich history rooted in the evolution of distributed computing:
Early Beginnings: Hadoop's origins trace back to Google's paper on the Google File System (GFS) and MapReduce, which outlined scalable data processing across large clusters of computers.
Creation: Hadoop was created by Doug Cutting and Mike Cafarella in 2005. Doug Cutting named it after his son's toy elephant, symbolizing the project's goal to handle large-scale data processing.
Apache Incubation: In 2006, Hadoop became an Apache project, receiving broad community support and contributions that helped refine its capabilities.
Growth and Adoption: Over the years, Hadoop evolved to include additional components and features, gaining widespread adoption in the industry for its ability to process large volumes of data efficiently.
Current Status: Today, Hadoop is a crucial part of the big data ecosystem, used by many organizations for managing and analyzing massive datasets.
What is Hadoop?
Hadoop is an open-source framework designed for distributed storage and processing of large datasets across clusters of computers. It is built to scale up from a single server to thousands of machines, each offering local computation and storage.
Distributed File System: Hadoop provides a distributed file system called Hadoop Distributed File System (HDFS), which allows it to store data across multiple machines.
Scalability: It is designed to handle petabytes of data by scaling horizontally, adding more machines to increase storage and processing power.
Fault Tolerance: Hadoop is built to be fault-tolerant, meaning it can continue to operate even if some of its components fail.
Open-Source: Hadoop is free to use and is supported by a large community of developers and users who contribute to its ongoing improvement.
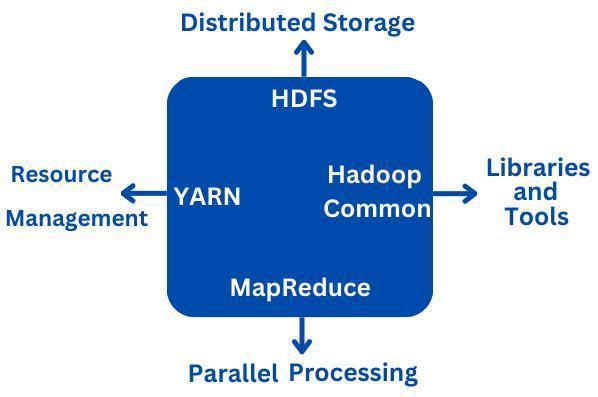
Components of Hadoop
Hadoop consists of several key components that work together to handle large-scale data processing:
1. Hadoop Distributed File System (HDFS):
Storage Layer: HDFS is the storage layer of Hadoop that distributes and replicates data across multiple nodes in a cluster.
Block Storage: Data is split into blocks and stored redundantly to ensure fault tolerance and high availability.
2. MapReduce:
Processing Framework: MapReduce is the processing framework that allows parallel computation on large datasets.
Map Phase: Data is processed in parallel by mapping functions to extract and transform data.
Reduce Phase: The results from the map phase are aggregated and reduced to produce the final output.
3. YARN (Yet Another Resource Negotiator):
Resource Management: YARN is responsible for managing and scheduling resources across the Hadoop cluster.
Job Scheduling: It handles job scheduling and resource allocation to ensure efficient processing.
4. Hadoop Common:
Utility Libraries: Hadoop Common provides a set of shared utilities, libraries, and APIs required by other Hadoop modules.
Support Functions: It includes components like configuration, serialization, and file system abstractions used across the Hadoop ecosystem.
These components work in harmony to provide a robust and scalable framework for processing and analyzing large volumes of data efficiently.
Architecture of Hadoop
Hadoop, a foundation in the world of big data, is not just a single tool but a suite of technologies that offers a unique approach to data storage and processing. Its architecture is ingeniously designed to handle vast amounts of data in a distributed fashion. At its core, Hadoop leverages clusters of computers to analyze and store data, making it highly scalable and fault-tolerant. The architecture of Hadoop is composed of several key components, each serving a specific purpose in the data handling process.
MapReduce
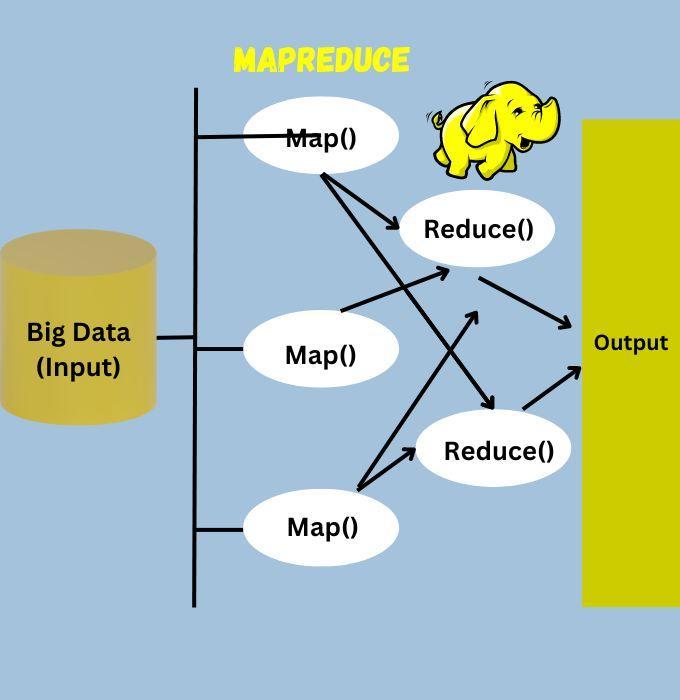
MapReduce is a pivotal component of the Hadoop ecosystem, a programming model that is essential for processing large data sets. Its genius lies in its simplicity and efficiency, enabling massive scalability and parallel processing of vast amounts of data. Let's break down how MapReduce works and why it's so effective in the Hadoop environment.
At its core, MapReduce involves two key processes: the Map process and the Reduce process. The Map function takes a set of data, processes it, and produces key-value pairs as output. This process is done in parallel across different nodes in a Hadoop cluster, making the task incredibly efficient. Each node processes a small portion of the data, ensuring that the workload is distributed evenly across the cluster.
After the mapping phase, the Reduce function comes into play. In this step, the key-value pairs produced by the Map function are taken and combined into smaller sets of tuples. The Reduce function then processes these tuples, which often involves summarizing the data, like counting the number of occurrences of a word in a text file or aggregating sales data.
The beauty of MapReduce lies in its ability to handle large-scale data processing tasks with remarkable speed and efficiency. By dividing and conquering, MapReduce makes it feasible to analyze and process large datasets that would be impossible to handle on a single machine.
Furthermore, MapReduce is fault-tolerant. If a node fails during the process, the task is automatically reassigned to another node, ensuring that the process completes successfully. This resilience is a key feature of Hadoop, making it a reliable tool for big data processing.
In summary, MapReduce is an elegant solution to the complex problem of big data processing. Its ability to break down large tasks into smaller, manageable ones and then aggregate the results efficiently makes it an indispensable part of the Hadoop architecture.
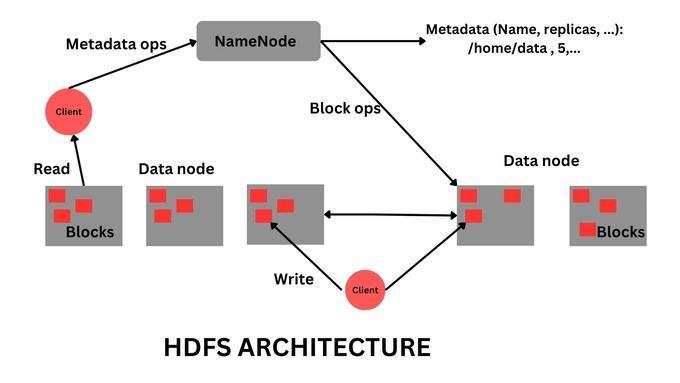
HDFS (Hadoop Distributed File System)
HDFS stands as the backbone of the Hadoop framework, representing a file system designed for storing very large files with streaming data access patterns, running on clusters of commodity hardware. It's ingeniously crafted to handle high volumes of data and provide easy access.
Here’s how HDFS operates and why it's a game-changer in handling big data.
Storage Mechanism
HDFS stores data in a distributed manner. It breaks down large files into blocks, each of a fixed size (usually 128 MB or 256 MB). These blocks are then distributed across multiple nodes in a Hadoop cluster. This distribution not only ensures efficient use of storage but also enables parallel processing of data.
Fault Tolerance
One of HDFS's most impressive features is its resilience. It replicates each data block across multiple nodes in the cluster (typically three nodes). This replication strategy means that even if one or two nodes fail, the data is still accessible from another node, ensuring no data loss and high availability.
Scalability
HDFS can scale up to accommodate more data simply by adding more nodes to the cluster. This scalability is a critical aspect for businesses dealing with ever-increasing volumes of data.
Data Integrity
To ensure data integrity, HDFS performs check-summing on the data. Whenever data is read from or written to HDFS, it verifies this check-sum, ensuring that the data is not corrupted.
High Throughput
HDFS is designed for high throughput rather than low latency. This means it's more suited for applications with large data sets rather than interactive applications where response time is critical.
Write Once, Read Many Model
Typically, data in HDFS is written once and then read multiple times. This write-once-read-many approach is ideal for scenarios like big data analytics, where data is loaded and then analyzed multiple times.
In conclusion, HDFS is a robust, scalable, and reliable file system that forms the foundation of the Hadoop ecosystem. Its ability to store massive amounts of data across a distributed environment makes it an essential tool for big data processing and analytics.
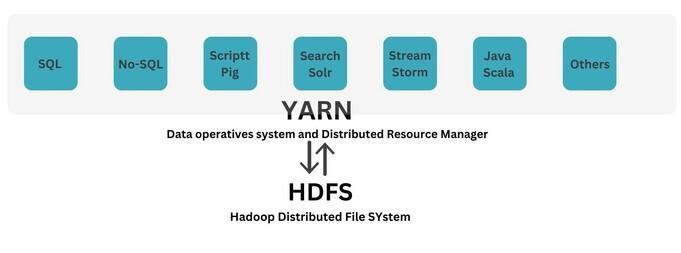
YARN (Yet Another Resource Negotiator)
YARN is a significant leap forward in the Hadoop ecosystem, revolutionizing resource management and job scheduling. Its introduction marked a new era in Hadoop’s capability, transforming it into a more efficient, multi-purpose, big data platform.
Let's unpack what YARN is and its role in Hadoop.
Resource Management
YARN’s primary role is to manage the computing resources in clusters and use them for scheduling users' applications. It allocates resources dynamically, ensuring optimal utilization and increased efficiency in processing.
Job Scheduling
YARN improves the MapReduce paradigm by separating the job scheduler from the job tracker. This separation allows for more flexibility in data processing operations, as it can support other processing approaches beyond MapReduce, like real-time processing and graph processing.
Scalability
YARN enhances the scalability of the Hadoop system. It can handle larger and more varied data processing tasks compared to the original MapReduce framework. This scalability makes Hadoop suitable for a broader range of applications.
Improved Cluster Utilization
YARN allows for better cluster utilization, as it can run multiple applications simultaneously. This multi-tenancy capability ensures that the cluster resources are used efficiently.
Flexibility
One of YARN’s greatest strengths is its flexibility. It can support various processing models, not just MapReduce. This flexibility allows developers to use Hadoop for a wide range of applications, from batch processing to interactive querying.
In summary, YARN is a powerful component that brings enhanced resource management, flexibility, and scalability to the Hadoop ecosystem. It represents a significant evolution in the way Hadoop manages and processes big data, making it a versatile tool for various big data applications.
Common Utilities or Hadoop Common
In the diverse and intricate world of Hadoop, the "Common Utilities" or "Hadoop Common" plays a foundational role. It consists of the essential utilities and libraries that support other Hadoop modules. Let's delve into the significance and functionalities of Hadoop Common in the Hadoop ecosystem.
Library of Utilities
Hadoop Common serves as a library of utilities that aid in the other Hadoop modules. These utilities include scripts to start Hadoop and scripts used for debugging, which are crucial for the smooth operation of the Hadoop cluster.
Abstraction and Interface
It provides the necessary abstraction and interfaces for the Hadoop modules. This includes the implementation of the Hadoop’s filesystem (HDFS) and interfaces for I/O operations, which are crucial for data storage and processing.
Environment Standardization
Hadoop Common standardizes the environment in which the Hadoop system operates. By offering a common framework and set of standards, it ensures consistency across various Hadoop deployments and configurations.
Support for Multiple Programming Languages
An important aspect of Hadoop Common is its ability to support applications written in various programming languages. This makes Hadoop accessible to a wider community of developers who prefer different programming environments.
Configuration Management
It assists in the management of configuration settings and parameters for the Hadoop ecosystem. Proper configuration is essential for the optimized performance of Hadoop clusters.
Advantages of Hadoop Architecture
1. Scalability:
Horizontal Scaling: Hadoop can scale horizontally by adding more nodes to the cluster, allowing it to handle increasing amounts of data and processing requirements.
Flexibility: It can efficiently manage both structured and unstructured data across a growing number of nodes.
2. Cost-Effectiveness:
Open Source: Hadoop is an open-source framework, reducing software licensing costs.
Commodity Hardware: It runs on commodity hardware, which is less expensive compared to high-end servers, making it cost-effective for large-scale deployments.
3. Fault Tolerance:
Data Replication: HDFS replicates data blocks across multiple nodes to ensure that data is not lost if a node fails.
Automatic Recovery: The framework automatically detects failures and reassigns tasks to other nodes, maintaining continuous operation.
4. High Throughput:
Parallel Processing: The MapReduce framework processes data in parallel across multiple nodes, significantly improving processing speed and throughput.
Efficient Data Handling: Hadoop is designed to handle large-scale data processing efficiently, providing high throughput for data-intensive applications.
5. Flexibility in Data Storage:
Variety of Data Types: Hadoop can store and process a wide variety of data formats, including text, binary, and complex structured data.
Schema-on-Read: It allows for schema-on-read, meaning data does not need to be structured before it is ingested, offering flexibility in handling diverse data types.
Disadvantages of Hadoop Architecture
1. Complexity:
Setup and Configuration: Setting up and configuring a Hadoop cluster can be complex and requires expertise in distributed systems and cluster management.
Management Overhead: Managing a large Hadoop cluster involves significant overhead, including monitoring, tuning, and maintaining the system.
2. Performance Issues:
Latency: Hadoop’s MapReduce framework is optimized for throughput rather than latency, which can lead to higher processing times for certain types of queries.
Not Ideal for Real-Time Processing: Hadoop is not well-suited for real-time data processing and low-latency applications due to its batch-oriented processing model.
3. Resource Intensive:
Storage Requirements: Hadoop clusters require substantial storage resources, as data is replicated across multiple nodes to ensure fault tolerance.
Memory and CPU Usage: Large-scale data processing can be resource-intensive, requiring significant memory and CPU resources, especially for complex computations.
4. Security Concerns:
Data Security: Hadoop’s default configuration may not provide robust security features, and additional measures may be needed to secure sensitive data.
Access Control: Managing access control and user permissions can be challenging, especially in large and complex Hadoop environments.
5. Learning Curve:
Skill Requirements: Users need a deep understanding of Hadoop’s architecture and ecosystem to effectively develop and manage applications, which can be a barrier for new users.
Frequently Asked Questions
What makes Hadoop ideal for big data processing?
Hadoop is designed for scalable, efficient, and distributed data processing, making it ideal for handling large data sets characteristic of big data.
Can Hadoop be used for real-time data processing?
While Hadoop excels at batch processing, its ecosystem has evolved to include tools like Apache Storm and Apache Flink for real-time data processing.
Is Hadoop suitable for small data sets?
Hadoop is primarily designed for large data sets; for small data, traditional database systems might be more efficient.
What are the four modules of Hadoop?
Hadoop consists of four main modules: Hadoop Common, which provides standard utilities; Hadoop Distributed File System (HDFS) for data storage; Hadoop YARN for job scheduling; and Hadoop MapReduce for processing large data sets in parallel.
Conclusion
Hadoop has emerged as a foundation in the world of big data, thanks to its robust architecture that effectively manages and processes vast volumes of data. Understanding its architecture, including components like MapReduce, HDFS, YARN, and Common Utilities, is crucial for anyone delving into the world of big data and analytics. This deep dive into Hadoop's architecture not only illuminates its operational dynamics but also underscores its significance in today's data-driven landscape. Whether you're a student or a professional, grasping these concepts is a step towards mastering big data technologies.






























 6+ registered
6+ registered 

