Get a skill gap analysis, personalised roadmap, and AI-powered resume optimisation.
Introduction
Unsurprisingly, the amount of data produced is increasing. However, you might be surprised at how much it costs. Google is reported to process 63,000 search requests every second, equating to 5.6 billion daily searches and nearly 2 trillion global searches per year.
Every 1.2 years, the industry's amount of data captured and kept doubles.
We could stack all of the data created in a single day onto DVDs and go to the moon twice.
Big Data management is the organisation, administration, and control of enormous volumes of structured and unstructured data. Hadoop is a Java-based open-source platform for storing and analysing large amounts of data. HDFS is where Hadoop reads and writes data.
In this article, we will explore the world of Hadoop and understand what HDFS is.
Hadoop Ecosystem
The Apache Hadoop ecosystem refers to all software components that make up the Apache Hadoop software library. It comprises both open-source projects and a wide range of additional technologies. Some of the most popular Hadoop ecosystem tools include HDFS, Hive, Pig, YARN, MapReduce, Spark, HBase, Zookeeper, etc.
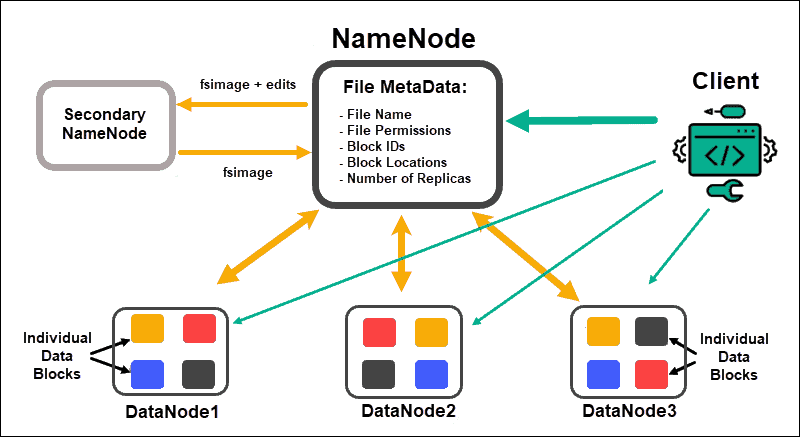
HDFS is one of the most popular components of the Hadoop ecosystem. HDFS stands for Hadoop Distributed File System. It is one of the most important Apache projects and Hadoop's principal storage system. A NameNode and DataNode architecture are used in HDFS. It's a large-file-storage distributed file system that runs on commodity hardware in a cluster.
The Hadoop Distributed File System
The Hadoop Distributed File System is a data storage cluster that simplifies the management of related files across servers and is reliable, high-bandwidth, and low-cost.
For files, HDFS is not the final destination. It's a data service that provides a unique set of required characteristics when data quantities and velocity are high.
HDFS is ideal for supporting extensive data analysis since the data is written once and then read numerous times, rather than the frequent read-writes of conventional file systems.
HDFS cluster consists of:
A “Name Node.”
Multiple “Data Nodes.”
The NameNode is in charge of keeping track of where data is stored physically.
HDFS works by breaking extensive data into abstract data blocks. The file metadata for these blocks is saved in a Fsimage on the NameNode local memory and includes the file name, file permissions, IDs, locations, and the number of replicas.
HDFS would be unable to locate any of the data sets dispersed among the Data Nodes if a Name Node failed. As a result, the Name Node becomes the cluster's single point of failure. We can use the Secondary Name Node or a Standby Name Node to address this problem.
Data Node
Data nodes are not intelligent, but they are flexible. Every data block is stored three times on independent Data Nodes within the HDFS cluster. The Name Node uses a rack-aware placement policy to track data nodes.
A Data Node talks with the Name Node and accepts its instructions almost twenty timesevery minute. It also sends an hourly report on the condition and health of the data blocks on that node. The Name Node can ask the Data Node to generate more replicas, remove them, or reduce the number of data blocks on the node based on the information provided.
Rack Aware Placement Policy
High availability and replication are two of the primary goals of a distributed storage system like HDFS. As a result, data blocks must be dispersed among different Data Nodes and across server racks.
This prevents all data replicas from being terminated if an entire rack fails. The HDFS NameNode maintains a default rack-aware replica placement policy:
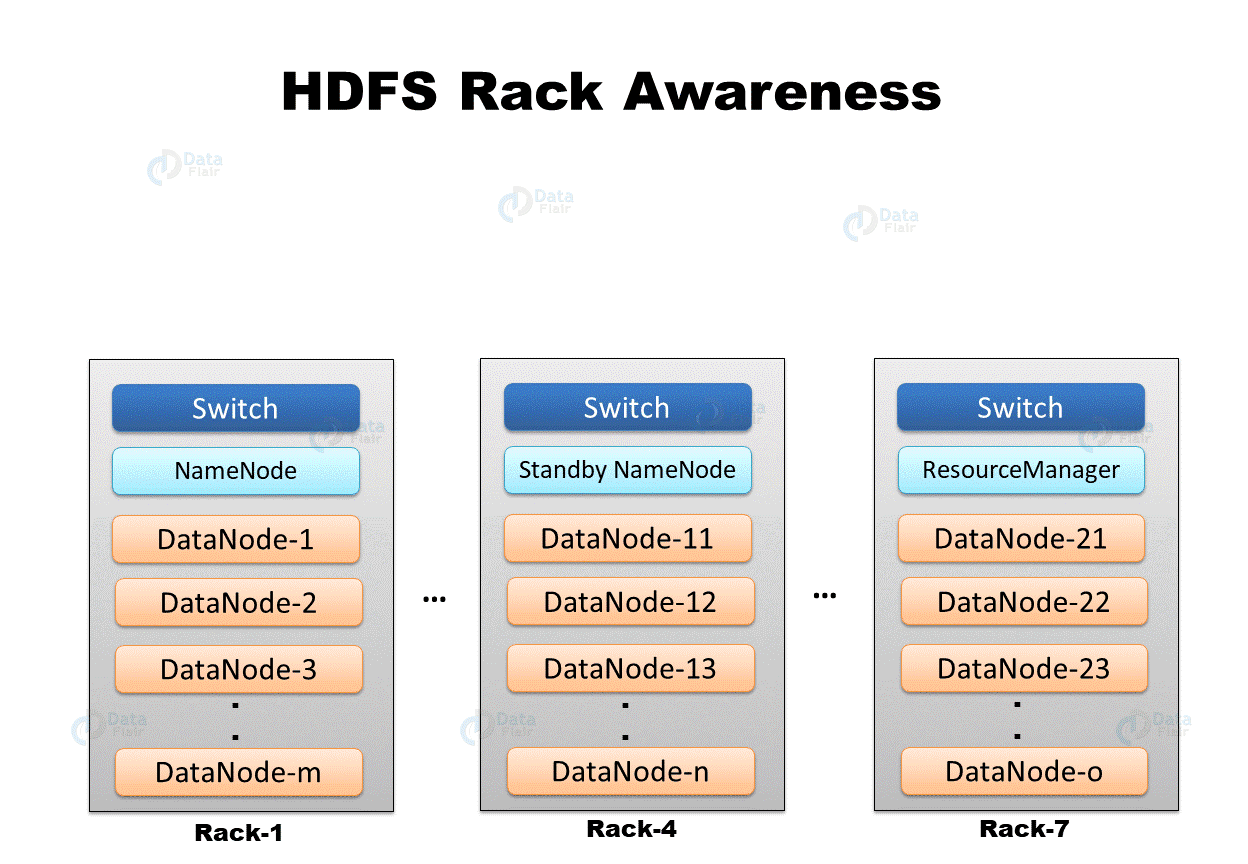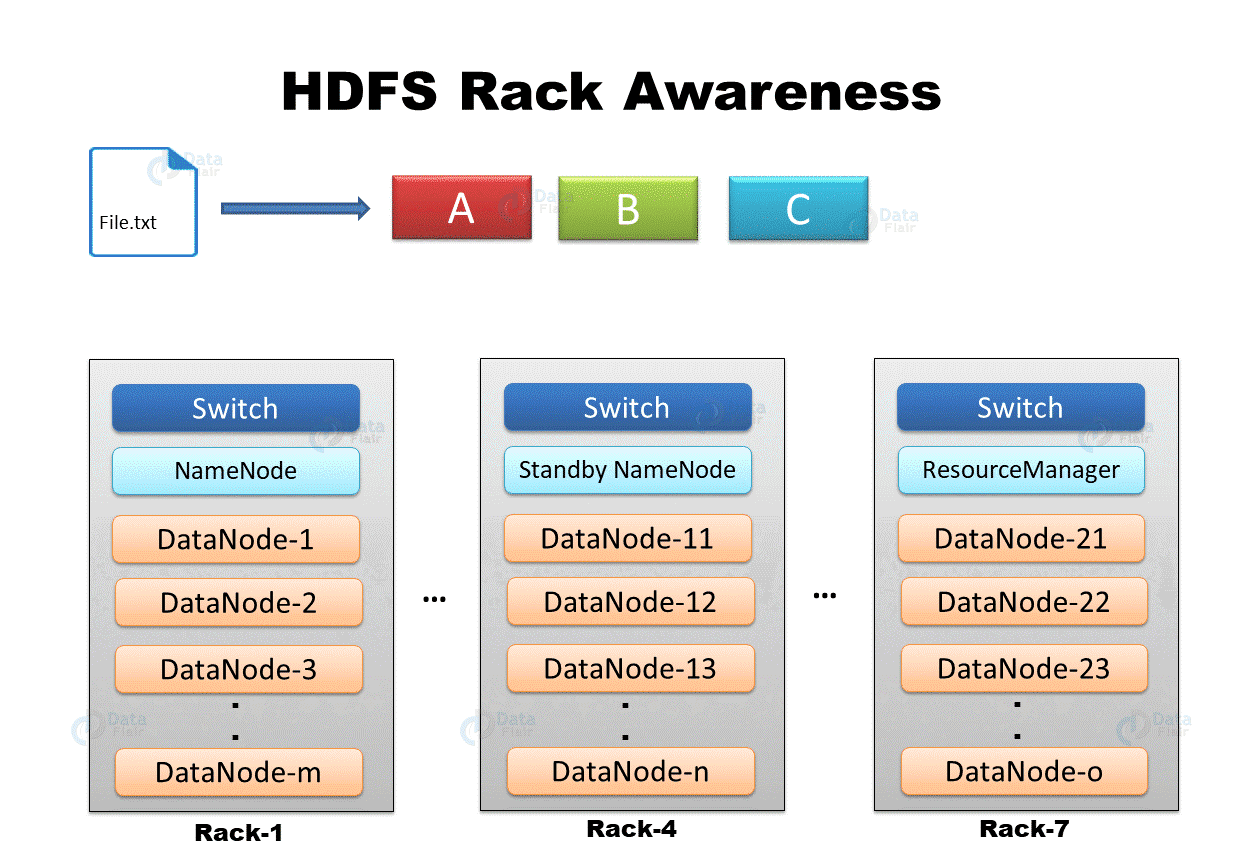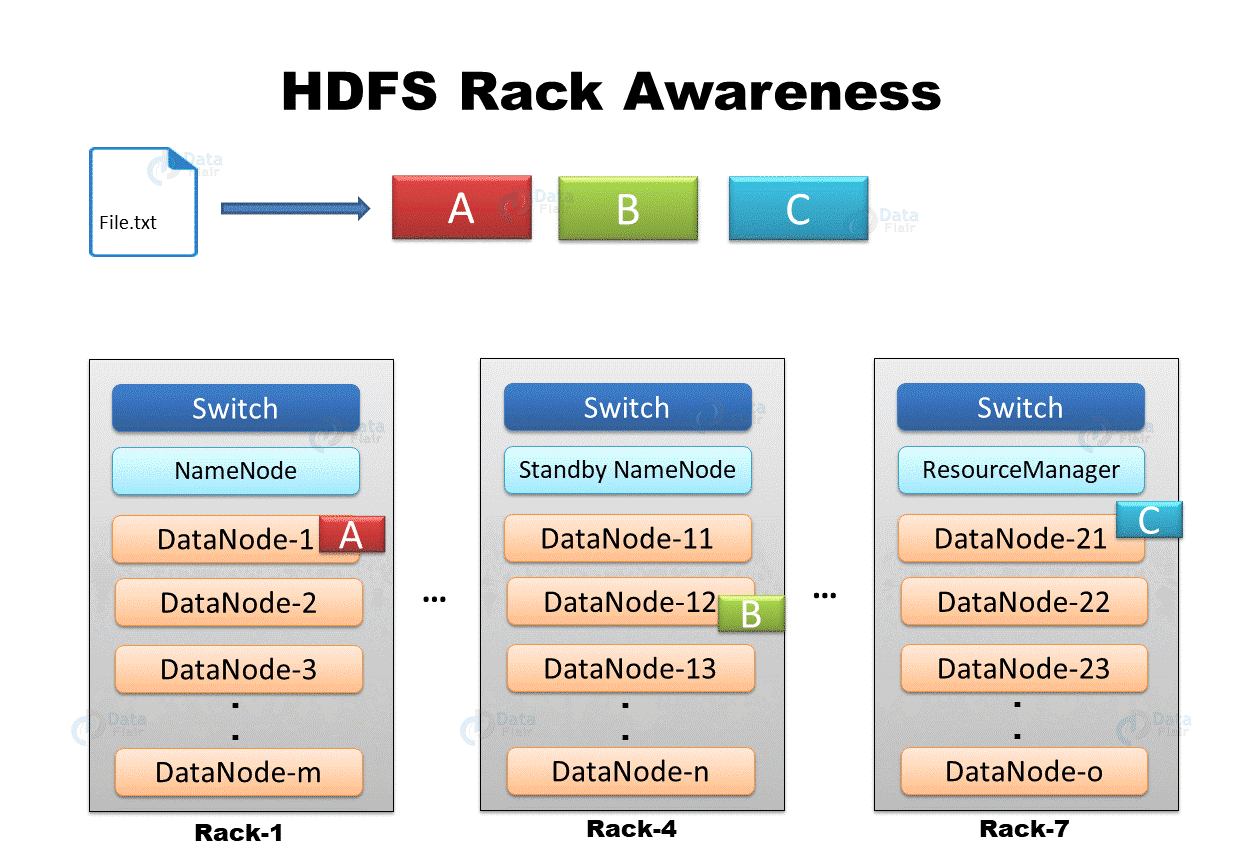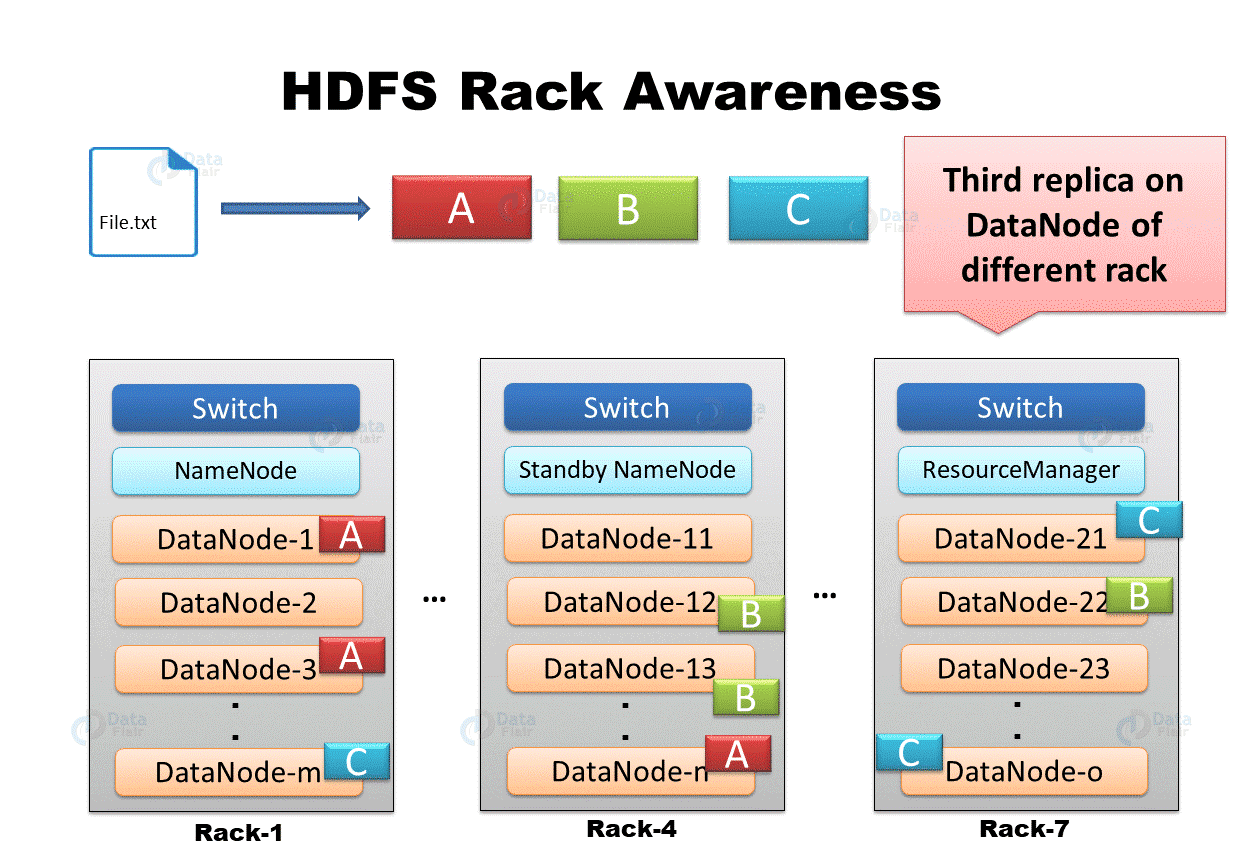
The first data block replica is created on the same node as the client.
The second replica is placed on a DataNode on a different rack at random.
On the same rack as the second replica, the third replica is housed in a different DataNode.
Any other replicas are stored on DataNodes spread around the cluster at random.
"File.txt" is separated into three sections: A, B, and C. HDFS build block replicas to provide fault tolerance. The first replica of each block is placed on the nearest DataNode, the second replica on a different DataNode on the same rack, and the third replica on a separate rack.
Goals of HDFS
The Goals of the Hadoop Distributed File System are as follows:
Quick Recovery from Hardware Faults: Because HDFS uses a tremendous amount of commodity hardware, component failure is expected. Therefore HDFS was designed to detect and automatically recover from errors.
Huge Data Accommodation: HDFS is designed for applications with data sets ranging from gigabytes to terabytes in size. HDFS can scale to hundreds of nodes in a single cluster and provides high aggregate data bandwidth.
Hardware across Data: A specified task can be completed quickly when the calculation occurs close to the data. It minimises network traffic and boosts throughput, especially when large datasets are involved.
Portability: HDFS is meant to be portable across many hardware platforms and compatible with several underlying operating systems to help with adoption.
Pros and Cons
HDFS provides many features. Even though HDFS has much functionality, it falls short in a few instances. Here we will discuss some of the Pros and Cons of HDFS.
Pros
Support the storing of large amounts of data.
Detect and respond to hardware issues rapidly.
Data access in real-time.
The consistency model is simplified.
Exceptional fault tolerance.
Hardware that is available for purchase.
Cons
Low-latency data access is not possible.
It is not recommended for storing a vast number of tiny files.
Modification of files is not permitted (HDFS 2.x supports the appending of the files).
The block size utilised by HDFS is typically 128 MB. As a result, an HDFS file is divided into 128 MB chunks, with each chunk residing on a distinct Data Node if possible.
In HDFS, what is a heartbeat?
A heartbeat is a signal sent from a Data node to a Name node to indicate that the Data node is still alive. The absence of a heartbeat in HDFS implies a problem, and the Name node and Data node cannot execute any computations.
What's the best way to figure out how many blocks We have in HDFS?
The fsck Hadoop command can also check the number of data blocks for a file or a block location.
What happens if Name Node fails during the task execution?
If the Name node goes down, the Hadoop cluster becomes unreachable and is declared dead. The data node stores actual data and follows the Name node's instructions. There can be numerous data nodes in a Hadoop file system, but only one active Name node.
In HDFS, what is a checkpoint?
Checkpointing is a process that requires merging the fsimage with the most recent edit log and creating a new fsimage for the name node to have the most up-to-date HDFS namespace metadata.
Conclusion
This article extensively discussed HDFS, its architecture, goals, advantages, and disadvantages.
We hope this blog has helped you enhance your HDFS and Big Data knowledge. You can learn more about Big Data, Big Data vs. Data Science, and Big Data Engineers. If you liked this article, check out these fantastic articles also.





























 9+ registered
9+ registered 

