Get a skill gap analysis, personalised roadmap, and AI-powered resume optimisation.
Introduction
Our digital world is producing more data than ever before. This includes social media posts, sensor readings, and financial transactions. The amount and complexity of information is staggering. Understanding this vast ocean of data requires powerful tools and technologies. This is where the HadoopEcosystem comes into play. In this article, we will explore about Hadoop Ecosystem in Big Data.
Hadoop Ecosystem in Big Data
The Hadoop Ecosystem and Big data go hand in hand. Hadoop provides the tools and technologies to process large datasets effectively.
Hadoop Ecosystem
The Hadoop Ecosystem is a group of software tools and frameworks. It is based on the core components of Apache Hadoop. It enables storing, processing, and analyzing large amounts of data. It provides the infrastructure needed to process large datasets. Hadoop distributes data and processes tasks across clusters of computers.
Big Data
Big data is too large and complex to be processed and analyzed by traditional methods. This data comes from various sources, such as social media, sensors, and online transactions. It contains valuable insights that help businesses make informed decisions and gain a competitive advantage.
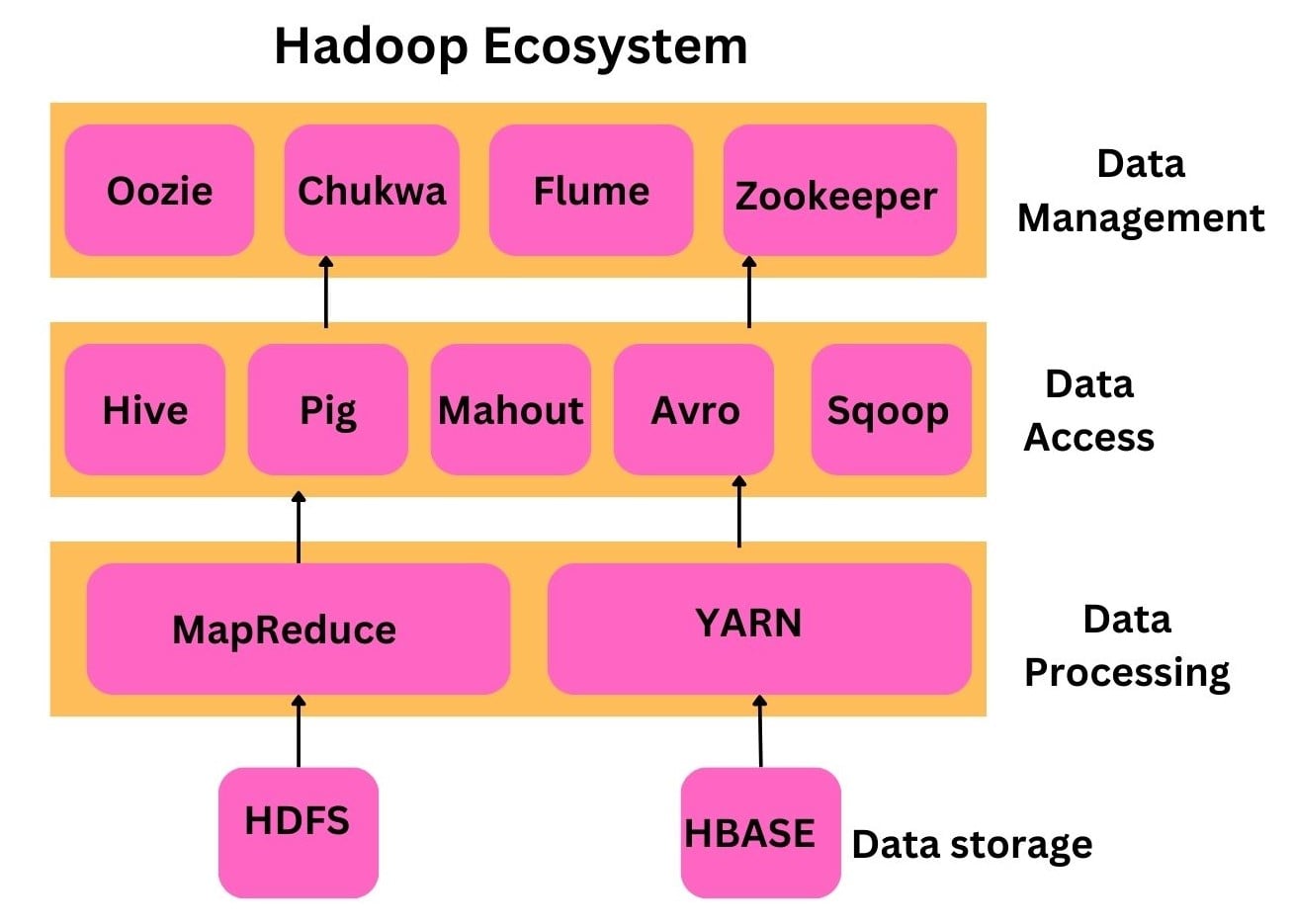
Hadoop Ecosystem Components
The Hadoop Ecosystem is composed of several components. Each component works together to enable the storage and analysis of data.
In the above diagram, we can see the components that collectively form a Hadoop Ecosystem.
Components
Description
HDFS
Hadoop Distributed File System
YARN
Yet Another Resource Negotiator
MapReduce
Programming-based Data Processing
Spark
InMemory Data Processing
PIG, HIVE
Processing of data services on query-based.
HBase
NoSQL Database
Mahout, Spark MLLib
Machine Learning algorithm libraries
Zookeeper
Managing cluster
Oozie
Job Scheduling
Now we will learn about each of the components in detail.
Hadoop Distributed File System
HDFS is the primary storage system in the Hadoop Ecosystem.
It is a distributed file system that provides reliable and scalable storage of large datasets across multiple computers.
HDFS divides data into blocks and distributes them across the cluster for fault tolerance and high availability.
It consists of 2 basic components
Node Name
Data Node
Node name is a primary Node. It contains metadata, requiring comparatively free resources than Data Nodes that store the actual data.
It maintains all the coordination between clusters and hardware.
HDFS Architecture
The main purpose of HDFS is to ensure that data is preserved even in the event of failures such as NameNode failures, DataNode failures, and network partitions.
HDFS uses a master/slave architecture, where one device (master) controls one or more other devices (slaves).
Important points about HDFS architecture:
Files are split into fixed-size chunks and replicated across multiple DataNodes.
The NameNode contains file system metadata and coordinates data access.
Clients interact with HDFS through APIs to read, write, and delete files.
DataNodes send heartbeats to the NameNode to report status and block information.
HDFS is rack-aware and places replicas on different racks for fault tolerance. Checksums are used for data integrity to ensure the accuracy of stored data.
Yarn
YARN (Yet Another Resource Negotiator). YARN helps manage resources across the cluster.
It has 3 main components:
Resource Manager
Node Manager
Application Manager
Resource manager allocates resources for applications in the system.
Node manager allocates resources such as CPU, bandwidth per machine. After allocation, it is later acknowledged to the resource manager.
The application manager and node manager perform negotiations according to the requirements.
Yarn Architecture
Key points about YARN architecture are:
Distributed Resource managers have the privilege of allocating resources to applications in the system.
Node managers work on allocating resources such as CPU, memory, and bandwidth per machine, and later credit resource managers.
The Application Manager acts as an interface between the Resource Manager and the Node Manager, negotiating their needs.
MapReduce
MapReduce is a programming model and processing framework that enables parallel processing of large data sets.
MapReduce can work with big data. It splits tasks into smaller parts called mapping and reducing, which can be done simultaneously.
Map tasks process data and produce intermediate results.
The intermediate results are then combined by a reduction task to produce the final output.
MapReduce makes use of two functions Map() and Reduce()
Map() sorts and filters data, thereby organizing it into groups.
A Map produces results based on key-value pairs, which are later processed by the Reduce() method.
Reduce() performs summarization by aggregating related data.
Simply put, Reduce() takes the output produced by Map() as input and combines these tuples into a set of smaller tuples.
Apache Hive
Hive provides a data warehousing infrastructure based on Hadoop.
It provides a SQL-like query language called HiveQL. It allows users to query, analyze and manage large datasets stored in Hadoop.
Hive turns queries into MapReduce or other execution engines. Thus, enabling data summarization, ad-hoc queries, and data analysis.
Apache Pig
Pig is a high-level scripting language and platform for simplifying data processing tasks in Hadoop.
It provides a language called Pig Latin. It allows users to express data transformations and analytical operations.
Pig optimizes these operations and transforms them into MapReduce jobs for execution.
HBase
HBase is a distributed columnar NoSQL database that runs on Hadoop.
It provides real-time random read/write access to large datasets.
HBase is suitable for applications that require low-latency access to data.
For example: real-time analytics, time-series data, and Online Transaction Processing Systems (OLTP).
HIVE
MetaStore: Stores metadata about tables (schemas, partitions) in databases like MySQL.
Driver: Coordinates execution of queries, manages sessions, and communicates with the Hive CLI or other interfaces.
Compiler: Translates HiveQL queries into MapReduce jobs or Tez tasks for execution.
Execution Engine: Executes jobs on Hadoop cluster via MapReduce, Tez, or other engines.
HDFS: Stores data files in Hadoop Distributed File System, managed by Hive.
Mahout
Core Components: Includes algorithms for clustering, classification, and recommendation.
Integration: Integrates with Apache Hadoop for distributed computing.
Math Libraries: Utilizes efficient linear algebra libraries like Apache Commons Math.
Scalability: Designed for scalable processing of large datasets using Hadoop's MapReduce.
Extensibility: Supports custom algorithms and integration with other big data frameworks like Spark.
Apache Spark
Spark is a fast and versatile cluster computing system that extends the capabilities of Hadoop.
It offers in-memory processing, enabling faster data processing and iterative analysis.
Spark supports batch processing, real-time stream processing, and interactive data analysis. Thus, making it a versatile tool in the Hadoop Ecosystem.
Apache Kafka
Kafka is a distributed streaming platform that enables the ingestion and processing of real-time data streams.
It provides a publish / subscribe model for streaming data. It allows applications to process the generated data.
Kafka is commonly used to build real-time data pipelines, event-driven architectures, and streaming analytics applications.
Apache Sqoop
Sqoop is a Hadoop tool that makes it easy to move data between Hadoop and structured databases.
This tool helps connect traditional databases with the Hadoop Ecosystem.
Apache Flume
Flume makes getting lots of live data easier and send it to Hadoop.
This helps add data from different places like log files, social media, and sensors.
Hadoop Performance Optimization
Here are some methods for optimizing Hadoop Ecosystem in Big Data
Take Advantage of HDFS Block Size Optimization
Configure the HDFS block size based on the typical size of your data files.
Larger block sizes improve performance for reading and writing large files, while smaller block sizes are beneficial for smaller files.
Optimize Data Replication Factor
Adjust the replication factor based on the required fault tolerance and cluster storage capacity.
A lower replication factor reduces storage overhead and improves performance but at the cost of lower fault tolerance.
Optimize Your Network Settings
Configure network settings such as network buffers and TCP settings. It helps to maximize data transfer speeds between nodes in your cluster.
Hadoop performance improves when network bandwidth increases and latency decreases.
Increase Concurrency
Split large computing tasks into smaller, parallelizable tasks to make optimal use of your cluster's compute resources.
This can be achieved by adjusting the number of mappers and reducers in your MapReduce job.
Optimize Task Scheduling
Configure the Hadoop scheduler. For e.g.: Fair Scheduler or Capacity Scheduler for efficient allocation.
Fine-tuning the scheduling parameters ensures fair resource allocation and maximizes cluster utilization.
Frequently Asked Questions
What are the four main components of Hadoop?
Hadoop consists of HDFS (storage), YARN (resource management), MapReduce (processing), and Common (utilities and libraries) for handling big data efficiently in a distributed environment.
What is sqoop in big data?
Sqoop is a tool in big data that transfers structured data between relational databases and Hadoop, enabling efficient import and export operations.
What are the 4 modules of Hadoop?
Hadoop has HDFS (storage), YARN (resource management), MapReduce (data processing), and Common (shared utilities) to support distributed big data processing.
Conclusion
The Hadoop Ecosystem has revolutionized how big data is stored, processed, and analyzed. Its distributed architecture, fault tolerance mechanisms, and scalable storage capabilities make it the perfect solution for organizations dealing with large amounts of data.
Components of the Hadoop Ecosystem in Big Data are HDFS, MapReduce, Hive, Pig, HBase, Spark, Kafka, Sqoop, and Flume.
































 9+ registered
9+ registered 

