



























Introduction
Apache HADOOP is a framework for creating data processing applications on a distributed computing system. Like how data is stored on a local file system of a personal computer, Hadoop data is stored in a distributed file system known as the HDFS( Hadoop Distributed File System).
HADOOP is a software framework that is free and open source. Large data sets are distributed across clusters of commodity computers, and applications built with HADOOP run on them.
Computers that are sold as commodities are inexpensive and widely available. These are primarily used to increase computational power at a low cost.
source:image
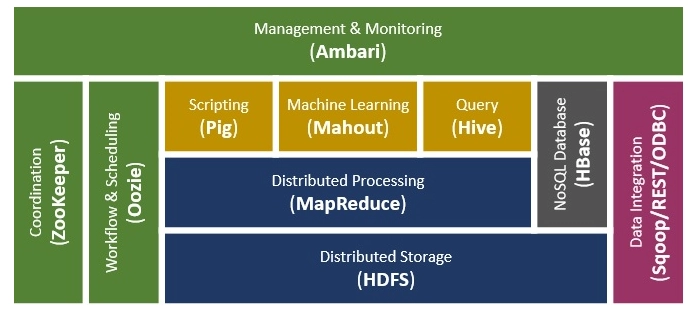
Hadoop Ecosystem Components
Hadoop Distributed File System
The Hadoop Ecosystem's most crucial component is Hadoop. Hadoop's primary storage system is HDFS. Hadoop distributed file system (HDFS) is a java-based file system for Big data storage that is scalable, fault-tolerant, reliable, and cost-effective.
Components of HDFS: NameNode and DataNode are the two main components of Hadoop HDFS.
YARN
One of the essential components of the Hadoop Ecosystem is Hadoop YARN (Yet Another Resource Negotiator). YARN is Hadoop's operating system, and it is in charge of managing and monitoring workloads. It enables multiple data processing engines to handle data stored on a single platform, such as real-time streaming and batch processing.
The following are the main characteristics of YARN:
→ Flexibility
→ Efficiency
→ Shared
MapReduce
Hadoop MapReduce is the data processing component of the Hadoop ecosystem. MapReduce is a programming framework that makes it simple to create applications that process the massive amounts of unstructured and structured data stored in the Hadoop Distributed File System. This parallel processing improves the speed and reliability of the cluster.
'MapReduce,' a Hadoop Ecosystem component, divides processing into two stages:
- The phase of the map
- Reduce the number of phases
Pig
It is a high-level language platform for querying and analyzing massive HDFS datasets. Pig is a Hadoop Ecosystem component that uses the PigLatin language. It has a lot in common with SQL. It loads the data, applies the necessary filters, and dumps the data in the specified format. Pig requires a Java runtime environment to execute programs. Apache Pig has the following features:
- Extensibility
- Opportunities for optimization
-
Handles a wide range of data
Hive
The Hadoop ecosystem component, Apache Hive, is an open-source data warehouse system for querying and analyzing large datasets stored in Hadoop files. Hive does three main functions: data summarization, query, and analysis.
Hive uses HQL (HiveQL), a SQL-like language. HiveQL converts SQL-like queries into MapReduce jobs, which are then executed on Hadoop.
The following are the main components of Hive:
- Metastore – This is where the metadata is kept.
- Driver – Manages the HQL (HiveQL) statement's lifecycle.
- Query Compiler - Compiles HiveQL into a Directed Acyclic Graph (DAG) (DAG).
- Hive server: Provides a user-friendly interface as well as a JDBC/ODBC server.
HCatalog
It's a Hadoop table and storage management layer. HCatalog supports various Hadoop ecosystem components such as MapReduce, Hive, and Pig to read and write data from the cluster. Hive's HCatalog component allows users to store data in any format and structure.RCFile, JSON, CSV sequenceFile, and ORC file formats are supported by default in HCatalog.
HCatalog's Advantages:
- Allows for data availability notifications.
- HCatalog frees the user from data storage overhead with the table abstraction.
- Make data cleaning and archiving tools more visible.
HBase
Apache HBase is a Hadoop ecosystem component that is a distributed database for storing structured data in tables with billions of rows and millions of columns. HBase is a distributed, scalable, NoSQL database built on top of HDFS. HBase allows you to read and write data in HDFS in real-time.
HBase's components are as follows:
- Master of HBase
- RegionServer
Thrift
It's a software framework for creating scalable cross-language services. Thrift is an RPC (Remote Procedure Call) communication interface definition language. Because Hadoop makes a lot of RPC calls, it's possible to use Apache Thrift, a Hadoop Ecosystem component, for performance or other reasons.
Avron
Acro is a popular data serialization system part of the Hadoop ecosystem. Avro, an open-source project, provides data serialization and data exchange services for Hadoop. These services can be used in conjunction or separately. Avro allows Big Data to exchange programs written in various languages.
Avro provides the following features:
- Data structures that are rich.
- Call for a remote procedure.
- The binary data format is small and fast.
- To store persistent data, use a container file.
Apache Mahout
Mahout is a free and open-source framework for developing scalable machine learning algorithms and data mining libraries. After data is stored in Hadoop HDFS, mahout automatically provides data science tools to find meaningful patterns in large data sets.
Mahout's algorithms are as follows:
- Clustering
- Filtering by consensus
- Classifications
- Pattern mining is a common occurrence.
Apache Drill
The Hadoop Ecosystem Component's primary goal is to process large amounts of structured and semi-structured data on a large scale. It's a distributed query engine with low latency that can scale to tens of thousands of nodes and query petabytes of data. The drill is the world's first schema-free distributed SQL query engine.
Apache Drill has the following features:
- Extensibility
- Flexibility
- Schema discovery in real-time
- Experiment with decentralized metadata
Apache Flumes
Flume collects, aggregates, and moves a large amount of data from its source to HDFS efficiently. It's a fault-tolerant and dependable system. This component of the Hadoop Ecosystem allows data to flow from a seed into the Hadoop environment. It uses a simple and extensible data model that enables online analytics. We can quickly get data from multiple servers into Hadoop using Flume.
Apache Sqoop
Sqoop is a Hadoop ecosystem component that imports data from external sources into HDFS, HBase, and Hive. It also exports Hadoop data to other outside sources. Sqoop is a relational database management system that works with Teradata, Netezza, Oracle, and MySQL.
Apache Sqoop has the following features:
- Import mainframe sequential datasets
- Direct import to ORC files
- Data transfer in parallel
- Data analysis that is quick and efficient
- Data copies in a hurry
Zookeeper
Apache Zookeeper is a Hadoop Ecosystem component that manages configuration information, names objects, provides distributed synchronization, and provides group services. A large cluster of machines is managed and coordinated by Zookeeper.
Zookeeper's characteristics include:
- Fast
- Ordered
Ambari
Ambari is a management platform for provisioning, managing, monitoring, and securing Apache Hadoop clusters, part of the Hadoop ecosystem. Ambari provides a secure platform for operational control, consistent, making Hadoop management easier
Ambari's characteristics include:
- Installation, configuration, and management are all made easier.
- Setup of centralized security
- Highly customizable and extensible
- Complete visibility into the health of the cluster
Oozie
Oozie combines multiple jobs in a logical order into a single work unit. Oozie supports Hadoop jobs for Apache MapReduce, Pig, Hive, and Sqoop and is fully integrated with the Apache Hadoop stack, using YARN as an architecture center. Oozie is also highly adaptable. Jobs can be quickly started, stopped, suspended, and rerun. It's even possible to skip or rerun a specific failed node in Oozie.
Oozie jobs are divided into two categories:
→ Oozie workflow – It is used to store and run Hadoop-based workflows.
→ Oozie Coordinator – This program runs workflow jobs according to predefined schedules and data availability.
Related Article Apache Server
Must Recommended Topic, procedure call in compiler design



 8+ registered
8+ registered 

