What is the Hadoop Distributed File system(HDFS)?
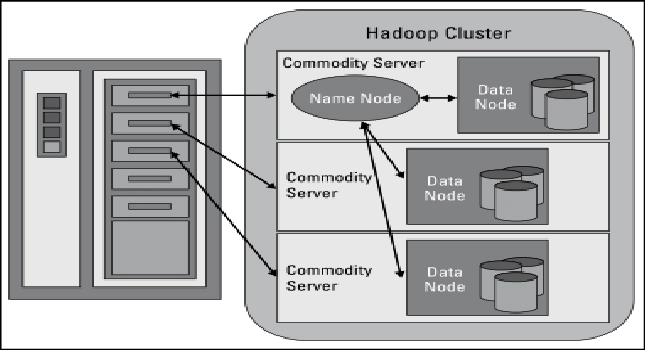
The Hadoop Distributed File System provides a flexible, resilient, clustered solution to handling files in a large data set. For files, HDFS is not the final destination. It's a data service that provides a unique set of required characteristics when data quantities and velocity are high. HDFS is ideal for supporting extensive data analysis since the data is written once and then read numerous times, rather than the frequent read-writes of conventional file systems. The service, which consists of a "NameNode" and multiple "data nodes" running on commodity hardware, performs best when the entire cluster is housed in the same physical rack in the data center.
Source: Link
Data Nodes
Data nodes are not intelligent, but they are tenacious. Data blocks are duplicated over many data nodes in the HDFS cluster, and the NameNode manages access. The replication process is designed for maximum efficiency when all of the cluster's nodes are gathered into a rack. HDFS has several features aimed at ensuring data integrity. Any difference in the operation of any element could impair data integrity when files are divided into blocks and distributed across different computers in the cluster. To ensure cluster integrity, HDFS uses transaction logs and checksum checking. For persistence, data nodes use local drives in the commodity server. For performance purposes, all of the data blocks are stored locally. Data blocks are replicated across several data nodes, so the failure of one server may not necessarily corrupt a file.
Name Nodes
Large files are broken down into smaller parts called blocks in HDFS. The blocks are stored on data nodes, and the NameNode is responsible for determining which blocks on which data nodes make up the entire file. The NameNode is more brilliant than the data nodes. The data nodes keep asking the NameNode whether there is anything they can do. This ongoing behavior also informs the NameNode about the availability of data nodes and how busy they are. The data nodes also interact with one another to work together during file system activities. Because blocks for a single file are likely to be stored on numerous data nodes, this is required. Because the NameNode is so important to the cluster's proper operation, it can and should be replicated to avoid a single point of failure.
What is Hadoop Mapreduce?
To completely comprehend Hadoop MapReduce's capabilities, we must distinguish between MapReduce (the algorithm) and a MapReduce implementation. Hadoop MapReduce implements the Apache Hadoop project's created and maintained algorithm. It's helpful to think of this as a MapReduce engine because that's precisely how it works. You provide input (fuel), the engine swiftly and efficiently turns the information into output, and you get the answers you need. Because you're utilizing Hadoop to solve business challenges, you'll need to know how and why it works. So let's take a closer look at Hadoop's MapReduce implementation. Hadoop MapReduce comprises numerous stages, each with its own set of operations that help you extract the answers you need from massive data. The procedure begins with a user request to run a MapReduce program and ends with the results being written back to the HDFS. HDFS and MapReduce run on nodes in a cluster housed in racks of commodity servers. The diagram shows two nodes to keep things simple.
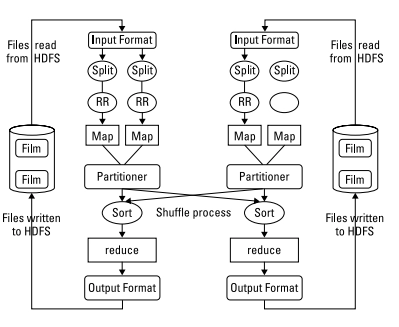
Data in Hadoop Mapreduce
When a client requests that a MapReduce program be started, the initial step is to find and read the raw data input file. Although the file format is entirely random, the contents must be transformed into a form that the application can understand. This is what InputFormat and RecordReader are for (RR).
InputFormat determines how the file will be split into smaller pieces for processing using the InputSplit function. The map is then given a RecordReader to transform the raw data for processing.
Hadoop includes several types of RecordReaders, each with a different set of conversion options. This feature is one of Hadoop's methods for dealing with the wide range of data types encountered in big data situations.
Mapping in Hadoop Mapreduce
Your data is now in a format that can be mapped. A separate map instance is called for each input pair to process the data. But what happens to the processed output, and how do you keep track of it? To answer the questions, Map contains two more features. The program must collect the result from the independent mappers and transmit it to the reducers because the Map and reduce must operate together to process your data. An OutputCollector is responsible for this task. A Reporter function collects data from map jobs and lets you know when or if they're finished.
All of this work is being done simultaneously on multiple nodes in the Hadoop cluster. The results will be delivered to a particular partition as inputs to the reduced tasks via the map tasks. After all of the map, jobs are completed, the intermediate results are pooled in the chamber, and the output is shuffled, sorting it for optimal reduced processing.
Reduce and Combine in Hadoop Mapreduce
Reduce is called for each output pair to complete its duty. Reduce gathers its output in the same way the map does while all the tasks are running.
Reduce cannot begin until all mapping has been completed, and it cannot end until all instances have been completed. Reduce's output is both a key and a value. While this is required to reduce function, it may not be the project's most efficient output format. OutputFormat is a Hadoop functionality that functions similarly to InputFormat. OutputFormat organizes the output for writing to HDFS using the key-value pair. The final step is to upload the data to HDFS. RecordWriter does this, and it works identically to RecordReader except in reverse. It accepts the data from OutputFormat and publishes it to HDFS in the format required by the application program.
Must Read Apache Server
Frequently Asked Questions
Why does Hadoop use MapReduce?
Hadoop's MapReduce architecture is used to create applications that can process enormous amounts of data on large clusters.
How does Hadoop execute a MapReduce job?
It works with HDFS' massive amounts of organized and unstructured data. By separating the job into a group of independent tasks, MapReduce processes data in parallel.
What are the phases of Mapreduce?
The MapReduce program is broken down into three stages: map, shuffle and reduce.
Is Hadoop a database?
Hadoop is an open-source software framework designed to manage massive structured and semi-structured data volumes. It is not a database.
Conclusion
In this article, we have extensively discussed the topic of Hadoop MapReduce. We hope that this blog has helped you enhance your knowledge regarding the subject of Hadoop MapReduce and if you would like to learn more, check out our articles on Big Data. We hope this article has helped you in understanding the Hadoop MapReduce. Still, the knowledge never stops, have a look at more related articles: Data mining, Data Warehouse, MongoDB, AWS, and many more. Do upvote our blog to help other ninjas grow.
Happy coding!
A ninja never stops learning, so to feed your quest to learn and become more advanced and skilled, head over to our practice platform Coding Ninjas Studio to practice advanced-level problems. Attempt 100 SQL problems, read interview experiences, and much more!
Thank you for reading.






























 9+ registered
9+ registered 

