Do you think IIT Guwahati certified course can help you in your career?
Introduction
Data points that deviate from the norm in data science can distort outcomes and guide analysis astray when not adequately managed. Data scientists must identify anomalous data points and determine if they should be excluded, included, or flagged for further investigation. A systematic approach to outlier detection and management can produce more accurate models and uncover hidden gems in data.
This article will discuss Handling Outliers In Data Science, how to identify them, the causes of outliers, strategies to handle those outliers, and when to use and remove them.
What Are Outliers and Why Do They Matter in Data Science?
Outliers are data points that stand out from the rest. They’re unusual values that don’t follow the overall pattern of your data. Identifying outliers in Data science is important because they can skew results and mislead analyses.
You can also consider our online coding courses such as the Data Science Course to give your career an edge over others.
Why Do Outliers Matter?
Outliers often indicate faulty data or experimental errors. They may be due to measurement errors, coding mistakes, or anomalies. If addressed, outliers can distort statistical analyses like means, correlations, and regression models.
Detecting outliers is an essential first step. Look for data points that are very high or low compared to the rest. You can spot outliers visually using box plots, histograms, or scatter plots. Mathematically, calculate the interquartile range (IQR) and consider points outside 1.5 to 3 IQRs(interquartile range) from the median as outliers.
Once found, you have a few options for handling outliers:
Transform the data - Apply log, square root, or other transformations to compress the range of values and reduce outlier impact.
Use robust statistics - Choose statistical methods less influenced by outliers like median, Mode, and interquartile range instead of mean and standard deviation.
Impute missing values - For outliers caused by missing or erroneous values, you can estimate replacements using the mean, median, or most frequent values.
Outliers often signify interesting data quirks that deserve further investigation. Handling them appropriately is key to sound data science and getting the most insight from your data.
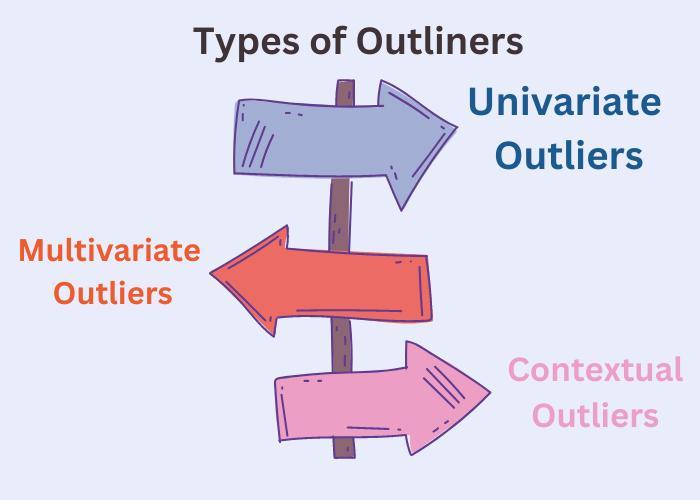
Types of Outliners
Outliers in data can be classified into three main types:
1. Univariate Outliers: These occur when a single variable's value significantly deviates from the rest of the data points in that variable. These can result from measurement errors or genuinely rare occurrences.
2. Multivariate Outliers: These involve multiple variables and represent unusual data points across several dimensions. Detecting these outliers helps identify relationships that might not be apparent with single-variable analysis.
3. Contextual Outliers: Also known as conditional outliers, these depend on specific conditions. A data point might be average under one context but an outlier under another. Understanding the context is crucial for accurate analysis.
Detecting and addressing outliers is crucial for maintaining data integrity and drawing accurate conclusions from analyses.
Common Causes of Outliers
Outliers in data can often be traced back to a few common causes. These unusual data points must be identified and handled properly to ensure accurate analysis and modeling.
Data Entry or Measurement Errors
Mistakes happen, and it’s easy for incorrect data to slip into a dataset. Outliers could be due to typos, incorrectly recorded values or faulty measuring equipment. Double-checking suspicious data points against the source can identify these errors. If confirmed as mistakes, the outliers should be corrected or removed.
Natural Variability
When working with human subjects or complex systems, some degree of randomness and unpredictability is expected. Outliers may reflect the natural diversity and variability in the data. These outliers should be retained as long as they are legitimate data points, not errors. However, the analysis may need to address them to not skew results.
Extreme Values
Sometimes, outliers represent extremely high or low valid but rare values. For example, income data will include a few very high earners, and inheritance amounts may include a few substantial bequests. Actual data points should not be deleted but may need special consideration in analysis so as not to bias models or statistics. Detecting and scrutinizing outliers for their cause and validity is essential in data preprocessing and cleaning. Addressing or removing outliers improves the integrity and reliability of any analysis or models built on the data. However, deleting legitimate data points can also introduce bias. Data scientists must carefully consider each outlier to determine the appropriate action: correction, removal, or retention.
Strategies for Handling Outliers
Outliers are data points that lie outside the overall distribution of your data. They can negatively impact the accuracy of models and analyses. There are a few common strategies for handling outliers:
Removing outliers
The simplest approach is to remove outliers from your dataset. However, this should only be done with caution. Some outliers are due to errors or anomalies and can be safely removed. But others may be valid data points, and removing them can bias your results. It's best to check outliers case-by-case to determine if they should be kept or removed.
Imputation
Imputation involves replacing outlier values with substituted values, like the mean, median or mode. This allows you to keep the data point but substitute an "educated guess" value for the outlier. Imputation reduces the impact of outliers but still keeps the data point in the analysis.
Winsorization
Winsorization involves replacing outliers with the next most extreme value that isn't an outlier. For example, replacing values below the 5th percentile with the 5th percentile and above the 95th percentile with the 95th percentile value. This minimizes the influence of outliers without removing them from the data.
Using robust statistics
Outliers less influence robust statistical methods. For example, the median is more robust than the mean. Non-parametric tests are also more robust. Using robust methods allows you to include outliers in your analyses without significantly impacting the results.
When to Remove vs. Retain Outliers
When analyzing data, outliers can skew results and mask essential patterns. Data scientists must determine whether to remove or retain outliers in their datasets.
When to Remove Outliers
Outliers should be removed when:
They are due to errors or inconsistencies in data collection. It may be a mistake if a value seems impossibly large or small.
They strongly influence statistics like the mean, making the data seem misleading. Removing outliers can provide a more accurate picture of the overall dataset.
The data has a small sample size. Outliers have a more significant distorting effect and skew results more in smaller datasets.
The research goals focus on the mainstream, central trends in the data. Outliers need to reflect the primary patterns or relationships data scientists want to uncover.
When to Retain Outliers
However, outliers should be kept when:
They represent a small, engaging sub-population data scientists want to study. Some outliers can reveal meaningful diversity or subgroups.
Removing them reduces the variability and diversity in the data, giving an unrealistic sense of coherence. Most real-world data is messy, diverse, and complex.
They do not meet the definition of outliers but show the full range of possibilities. What appears to be an outlier is an extreme value within the overall data pattern.
Data comes from observational studies or samples. Removing outliers can bias the data and reduce its generalizability. The outliers may represent reality.
Ultimately, data scientists must weigh all these factors and determine if outliers make the data seem misleading or if they genuinely represent the diversity and complexity in the real world. The context of the research and goals should guide decisions around handling outliers.
Outliers are data points significantly different from most datasets, often due to data collection, measurement, or recording errors. They can represent rare or unusual events, skew results, and affect data interpretation. Identifying and handling outliers appropriately is crucial to prevent skewing results and affecting data interpretation.
Why is it essential to handle outliers in data analysis?
Outliers are crucial in data analysis as they can significantly impact results and conclusions. They distort statistical measures, leading to inaccurate interpretations and masking important patterns or relationships. Properly addressing outliers ensures more accurate and reliable analysis outcomes for data scientists.
How can I detect outliers in my data?
There are several methods to detect outliers in your data, including Visualizing your data, Calculating the interquartile range (IQR), and Using statistical methods like z-scores
Should I remove outliers from my data?
The decision to remove outliers from your data depends on various factors, including the Accuracy of the outliers, Impact on results, and Research goals.
Conclusion
This article is about Headlining Outliners in data science, How to identify those, and strategies to handle those outliers. We hope this blog has helped you enhance your knowledge of the outliers in data sciences. If you want to learn more, then check out our articles.































 8+ registered
8+ registered 

