


























Introduction
In DBMS(Database management system), to retrieve a particular data, it is not recommended to search through all the data to get the desired data, and this method is inefficient also. Thus, in this situation, the concept of hashing comes into the picture. Hashing is an efficient method to search the location of the desired data on the memory disk without searching through all the data using an indexed structure. In this, data is stored in the memory blocks, and the hash function generates the addresses of these blocks.

Recommended Topic, Schema in DBMS and Data Structure, Multiple Granularity in DBMS
What is Hash File Organization in DBMS?
Now coming to the Hash file organization, a hash function is used to calculate the addresses of the memory blocks used to store the records. The hash function can be any mathematical function that is either simple or complex. The hash function is applied to some attributes or columns (key or non-key columns) to get the address of the block. That's why it is also known as Direct file organization.
If the hash function is generated using a key column, that column is known as the hash key.
If the hash function is generated using a non-key column, it is known as a hash column.
In this file organization, we don't need to perform operations like searching or sorting the entire file to get a particular record. Hash file organizations work on the principle of hashing.
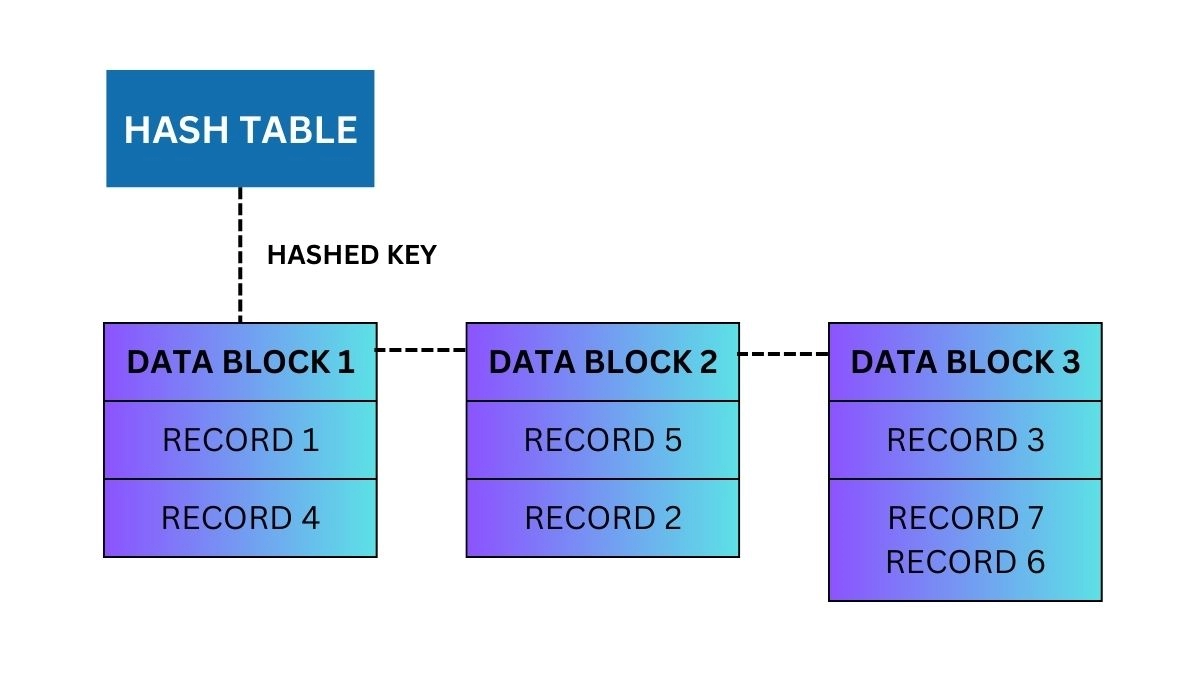
In the diagram above, a hash table maps the hashed keys to a specific data block in memory. Data blocks are represented as rectangular boxes, with each box containing one or more data records. Each data record is shown as a separate row in the data block.
When a new data record is inserted into the hash file, the hash function is used to hash its key, and the resulting hashed key is used to determine which data block it should be stored in. Then the data record is inserted, including the appropriate data block.
In this example, Record 1 and Record 4 are stored in Data Block 1, Record 5 and Record 2 in Data Block 2, and Record 3, Record 7, and Record 6 are stored in Data Block 3, respectively.
- Data Bucket: A data bucket refers to a storage unit used in hash-based data structures like hash tables or hash maps. It stores key-value pairs or other data elements based on the result of a hash function. Buckets are typically organized into an array or linked list, with each bucket containing data elements that map to the same hash index.
- Hash Function: A hash function is a mathematical algorithm that converts input data of arbitrary size into a fixed-size string of characters. It efficiently maps data to a unique hash code or hash value, typically used for indexing or organizing data in hash-based data structures. An ideal hash function minimizes collisions, distributing data uniformly across hash indexes.
- Hash Index: A hash index is a numerical value generated by applying a hash function to data. It represents the location or position within a hash-based data structure, such as a hash table or hash map, where the data is stored. Hash indexes are used to quickly locate and retrieve data elements, facilitating fast data access and retrieval operations.
Hashing is further categorized into two parts:
- Static Hashing
- Dynamic Hashing
Let us learn these hashing in detail using their suitable examples.
Static Hashing
In static hashing, the resultant address of the data bucket will always be the same. You will learn about static hashing clearly by the following example.
Example
If we generate an address for USER_ID= 13 using the simple hash function mod(5), it will always result in the same bucket address 3. There will be no change in the resultant bucket address in this example.
This proves that the number of data buckets in the memory remains constant throughout the process in static hashing.
Operations
Some of the operations of static hashing are given below:
- Search a record
To search a particular record, the hash function retrieves the memory address of the bucket where the desired data is stored (by the same hash function).
- Insert a record
To insert a new record into the table, the hash function generates an address for the new record based on the hash key, and the record is stored in that location.
- Update a record
To update a record, it needs to be searched in the database. The hash function is used to search the record, then update it.
- Delete a record
To delete a record from the table, we will first fetch the record using searching(by hash function), then we will delete the records for that address in the memory.
Now you must be thinking, if we want to insert a record and the hash function gives the address of the block already filled with some record, what will we do!
When we want to insert some new record into the table, but the address of a data bucket generated by the hash function is not empty(means already filled by some other data), this situation in static hashing is known as Bucket Overflow. There are several methods provided to overcome this situation.
Some commonly used methods are discussed below:
- Open Hashing: Open hashing, also known as separate chaining, involves storing multiple items in the same bucket of a hash table. If a collision occurs (i.e., two items hash to the same index), the collided items are stored in a linked list, array, or another data structure within the bucket. Each bucket maintains a pointer to the head of the list or array, allowing for efficient retrieval of collided items during lookup operations.
- Closed Hashing: Closed hashing, also known as open addressing, involves resolving collisions by finding an alternative location within the hash table. When a collision occurs, the hash table is probed sequentially until an empty slot (or a slot with a matching key in certain cases) is found. Closed hashing methods include linear probing, quadratic probing, and double hashing.
- Quadratic Probing: Quadratic probing is a method used in closed hashing to resolve collisions by systematically probing alternate locations within the hash table. Instead of linearly searching for the next available slot, quadratic probing uses a quadratic function to determine the next probe position. The probing sequence is typically of the form h(k) + c1 * i + c2 * i^2, where h(k) is the initial hash value, i is the probe index, and c1, c2 are constants.
- Double Hashing: Double hashing is another method for resolving collisions in closed hashing by using a secondary hash function. When a collision occurs, the secondary hash function determines the offset for probing the next location in the hash table. Double hashing aims to distribute collided items more evenly across the hash table, reducing clustering and improving lookup performance.
Also Read - Specialization and Generalization in DBMS, hash function in data structure
Dynamic Hashing
Since, in static hashing, the data buckets do not expand or shrink dynamically as the size of the database increases or decreases. This is the major drawback of static hashing, and that's why the concept of dynamic hashing comes under the picture.
In Dynamic hashing, the data buckets expand or shrink ( data buckets added or removed) dynamically according to the increase or decrease in records. It is also known as Extended hashing.
Example
In this, hash functions are made to generate a large number of values. For example, three records A1, A2, and A3 need to be stored in the table. The hash function produces three addresses for each 1001, 0101, and 1010 respectively. If we try to load the data according to the first bit, it tries to load three at addresses 1 and 0.
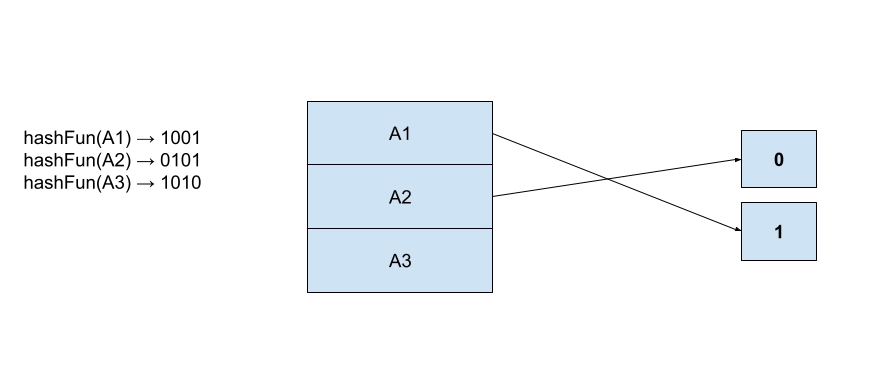
But the problem is there is no remaining bucket address for A3 as one is already filled by A1.
Thus, the bucket has to expand dynamically to store the third record A3, so it changes the address will use two bits instead of one bit; then it tries to accommodate A3.
The figure below shows this example perfectly:



 8+ registered
8+ registered 

