Do you think IIT Guwahati certified course can help you in your career?
Introduction
Hashing is one of the elementary concepts in computer programming and is heavily used by developers for many use cases. Hashing is used to index and retrieve information from the database quickly. Hashing is the process of mapping a key to a value using hash functions. Hash functions are mathematical functions that help us hash key-value pairs.
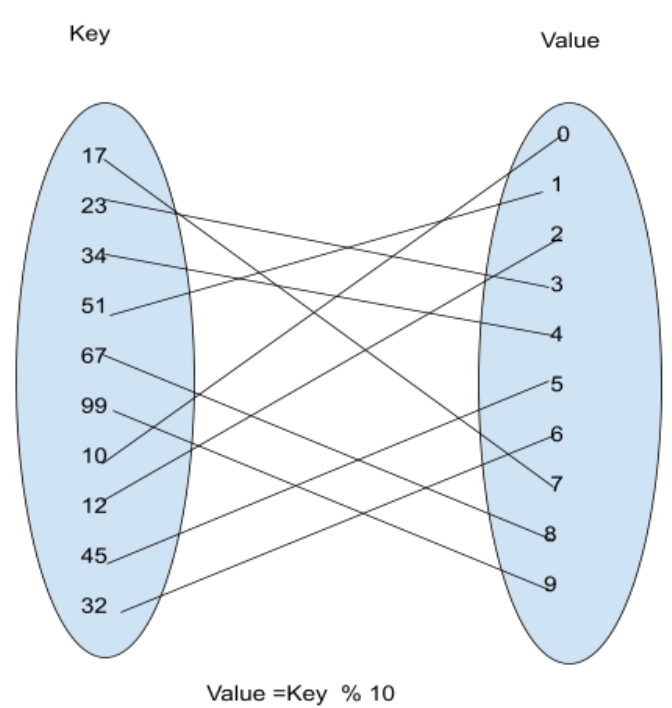
Consider a hash function: Y = K % N, where ‘K’ is a key, ‘N’ is the size of the hash table, and ‘Y’ is the generated value.
Let us suppose the size of the hash table is 10. In that case, the values will be generated in the following ways.
Here is the catch. The hash value for both 17 and 67 is 7. Should they be mapped to the same value? Definitely not. This situation, where one or more keys map to the same value, is called a collision. There are several methods to combat such problems. Let us briefly discuss them here.
What is Hashing in Data Structure?
Hashing is a technique used in data structures to efficiently store and retrieve data by mapping keys to specific indices in an array known as a hash table. It involves using a hash function that takes a key and computes an index where the corresponding value is stored. The goal is to distribute the keys uniformly across the hash table, minimizing collisions (when multiple keys map to the same index). When collisions occur, they are resolved using methods like chaining or open addressing. Hashing provides constant-time average-case complexity for insertion, deletion, and searching operations, making it highly efficient for large datasets. However, the worst-case complexity can be linear if the hash function is not well-designed or if there are too many collisions.
What Are Hashing Algorithms?
Hashing algorithms are mathematical functions that convert data into a fixed-size string of characters, typically called a hash value or hash code. These algorithms play a critical role in ensuring data integrity, enhancing security, and detecting errors. A small change in input drastically alters the hash, making them ideal for verifying file integrity, securing passwords, and enabling fast data retrieval in databases. Hashing is widely used in cryptographic applications, digital signatures, and data structures like hash tables.
Types of Hashing Algorithms
1. MD5 (Message Digest 5)
MD5 is one of the oldest and most widely known hashing algorithms. It produces a 128-bit (16-byte) hash value, typically rendered as a 32-character hexadecimal number. MD5 takes an input of any length and returns a fixed-length digest, which is useful for verifying file integrity. However, it’s no longer recommended for cryptographic purposes due to vulnerabilities to collision attacks. Key Features:
Fast computation
Fixed-size output
Simple implementation
Applications: Used in checksums, file verification tools, and non-critical security scenarios like duplicate file detection.
2. SHA-256 (Secure Hash Algorithm - 256 bit)
SHA-256 is part of the SHA-2 family and generates a 256-bit hash value. It is highly secure and widely used in modern cryptographic applications. The algorithm processes data in 512-bit chunks and ensures resistance to collisions and pre-image attacks. Key Features:
Strong cryptographic security
Reliable data integrity protection
Widely accepted industry standard
Applications: Commonly used in blockchain technology (like Bitcoin), digital signatures, and SSL certificate validation.
3. CRC32 (Cyclic Redundancy Check)
CRC32 is not a cryptographic hash but is used primarily for error detection in data transmission and storage. It produces a 32-bit hash value based on polynomial division. While it doesn’t offer cryptographic security, it is efficient in detecting accidental data corruption. Key Features:
Fast and lightweight
Detects accidental errors in transmission
Not suitable for secure applications
Applications: Used in network communication protocols, file compression tools (ZIP, RAR), and disk storage integrity checks.
A hash table is a data structure that stores and retrieves key-value pairs efficiently.
It uses a hash function to compute an index for each key, determining where the data is stored in the underlying array.
Key-value pairs are stored in an array-like structure based on the computed index.
When multiple keys map to the same index (known as a collision), collision resolution techniques are used:
Chaining (using linked lists at each index)
Open addressing (finding another open slot within the array)
Hash tables offer average-case time complexity of O(1) for:
Insertion
Deletion
Searching
The worst-case time complexity can be O(n) if the hash function causes many collisions.
They are widely used in:
Caches
Symbol tables
Dictionaries
What is a Hash Collision?
A hash collision, or simply a collision, occurs in a hash table when two or more distinct keys map to the same hash value or index in the underlying array. In other words, the hash function generates the same hash code for different keys, causing them to be stored at the same location in the hash table.
Collisions are a common problem in hash tables because it is generally impossible to design a perfect hash function that avoids collisions entirely, especially when the number of possible keys is much larger than the size of the hash table.
When a collision happens, it needs to be resolved to maintain the integrity and efficiency of the hash table
Causes of Hash Collisions:
Insufficient hash table size: If the hash table size is too small relative to the number of keys being inserted, collisions become more likely. When too many keys exist for the available slots, the probability of keys mapping to the same index increases.
Poor hash function: A hash function that does not distribute keys evenly across the hash table can lead to frequent collisions. If the hash function produces similar hash values for different keys or if it does not use the full range of available indices, collisions will occur more often.
Identical hash values for distinct keys: Even with a well-designed hash function, distinct keys can produce the same hash value. This is known as a hash collision and is an inherent property of hash functions, as they map a larger set of keys to a smaller set of indices.
Clustered keys: If the keys being inserted into the hash table have similar characteristics or are clustered together, they may generate similar hash values, leading to collisions. For example, if the keys are strings with similar prefixes or integers with close values.
Limited hash function range: If the range of values produced by the hash function is limited compared to the size of the hash table, collisions can occur more frequently. A hash function with a narrow range may map different keys to the same indices.
Collision Handling Techniques
There are several collision-handling techniques. We will discuss a few of them here.
Linear Probing
Whenever a collision occurs, we try to find a new empty location for the key down the hash table. Whenever we find an empty location, we store the key on that location.
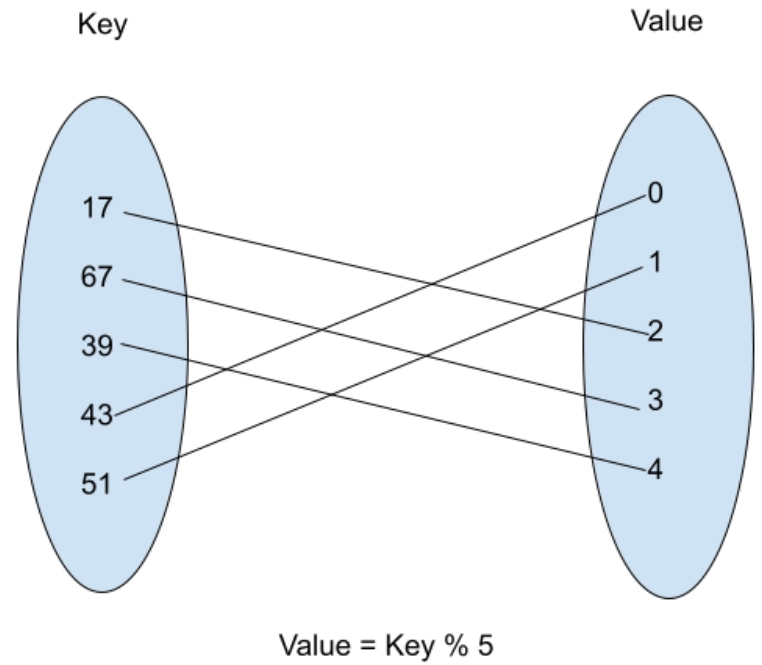
Notice that there is a collision between 17 and 67. At first, 17 is hashed using 17 % 5 to generate the value as 2. Now, for the key 67, value = 67 % 5, which is again 2. Hence, hashing of 17 and 67 results in a collision. Here we will use the concept of linear probing. We will search for the first empty location down the hash table. The first empty location after 2 is 3. Therefore, we insert 67 at location 3.
Now comes 39, which is hashed to 39 % 5 = 4. Since location 4 is empty, we insert 39 at location 4.
Then for key 43, there is another collision. Since 43 % 5 = 3, it should be inserted at location 3, we can see that location 3 is already occupied by key 67. Therefore, we will now search for the first empty location in the hash table. So, we found location 0 as an empty location. Thus, 43 is inserted at location 0.
In the end, the key 51 is hashed to 51 % 5 = 1. Since location 1 is empty, 51 is inserted there.
Now when we want to look up the table for a key, we just have to find a hash of the key.
For example, if we want to search 17 in the above hash table, we calculate its hash. So, value = 17 % 5 = 2. Therefore, we look up at location 2. If we don’t find it at that particular location, we need to look down the hash table until we find it. If the entire table is looked up and the key is not found, it means the value does not exist in the hashtable.
Chaining
Chaining is a simple technique to remove collisions. In this technique, we implement the hash table as an array of linked lists. We find the hash of a key, as usual, using the hash function. If a collision occurs, we attach the given key at the end of the linked list in that location.
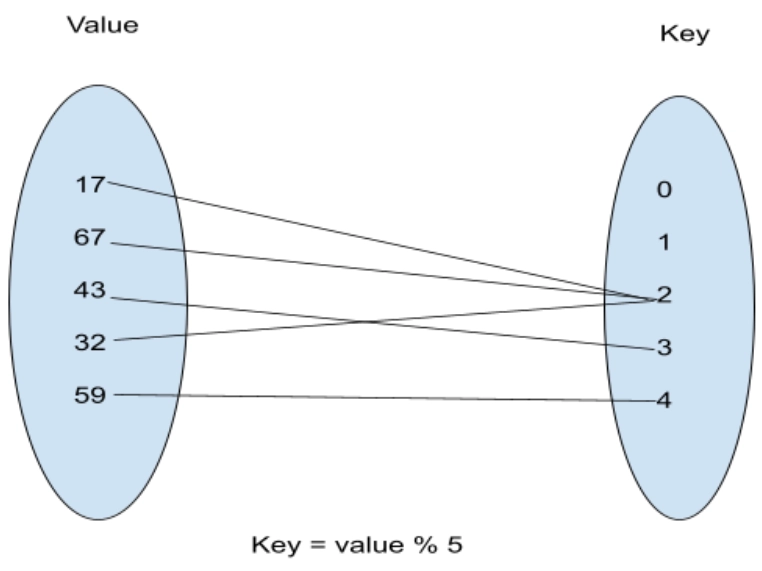
In this example, there are three collisions. Firstly, 17 is hashed to 2. Then 67 is again hashed to 2, and finally, 32 is also hashed to 2. So, as per chaining, they are linked together in a linked list.
Key
Value
Linked List Representation
17, 67, 32
Value = 2
2 -> 17 -> 67 -> 32
43
Value = 3
3 -> 43
59
Value = 4
4 -> 59
When we want to look up a key, we find its hash. Then if we want to find an element, we have to traverse the linked list. In this case, insertion, search, and deletion take O(n) time in the worst case. However, the amortized or the average complexity is still O(1) for insertion, deletion, and search.
Double Hashing
This collision resolution technique is quite efficient. As the name suggests, we apply two hash functions to an element. We apply the second hash only if a collision occurs after applying the first hash.
Double hashing is performed in the following way: Hash1(key) = key % size of hash table. Hash2(key) = prime - (prime - key % prime), where ‘prime’ is the prime number just smaller than the size of the hash table. Value = (Hash1 + i * Hash2) % size of the hash table, where ‘i’ is initialized with one and incremented if there is a collision.
Let us consider an example to understand double hashing.
Suppose we want to insert the numbers: 17, 67, 32, 45, and 98 in the hash table. Therefore, using double hashing, we can generate the values corresponding to every key in the following way:
Key
Function
Value
17
Hash1 = 17 % 5 = 2.
2
67
Hash1 = 67 % 5 = 2,
Hash2 = 3 - 67 % 3 = 2,
Value = (2 + 1 *1) % 5 = 3.
3
32
Hash1 = 32 % 5 = 2,
Hash2 = 3 - 32 % 3 = 1,
Value = (2 + 1 *1) % 5 = 3,
Value = (2 + 2 *1) % 5 = 4.
4
45
Hash1 = 45 % 5 =0
0
98
Hash1 = 98 % 5 = 3,
Hash2 = 3 - 98 % 3 = 1,
Value = (3 + 1 * 1) % 5 = 4,
Value = (3 + 2 * 1) % 5 = 0.
Value = (3 + 3 * 1) % 5= 1.
1
Similar to the above case, the time complexity for insertion, deletion, and search is O(N). However, the amortized time complexity is still O(1) for all three operations.
Applications of Hashing
Hashmap: Hashing can be used to create hashmaps where we store key-value pairs. Values are unique, whereas there can be multiple keys for the same value.
Message Digest: This is an excellent use case of hashing. The message digest is an application of cryptographic hash functions where messages can be of arbitrary length, and the hash is always of a fixed no of bits. For example, the SHA256 hashing algorithm uses 256 bits to store the hash of any message digest.
Rabin-Karp Algorithm: This is one of the most famous applications of hashing. Rabin-Karp is a string-searching algorithm that uses hashing to find patterns in a string.
Advanatges of Hashing:
Now, let's discuss the main advantages of using hashing:
1. Data Integrity: Hashing ensures data integrity by providing a way to verify that the original data has not been altered. Any changes made to the data, even a single bit, will result in a completely different hash value. This property allows for easy detection of data tampering or corruption.
2. Password Storage: Hashing is commonly used for securely storing passwords. Instead of storing passwords in plain text, which is highly insecure, hashing algorithms are employed to convert passwords into irreversible hash values. When a user enters their password, it is hashed and compared with the stored hash value for authentication. This approach prevents the exposure of actual passwords even if the database is compromised.
3. Data Lookup and Retrieval: Hashing enables efficient data lookup and retrieval in large datasets. By using hash tables or hash maps, data can be stored and accessed based on a unique hash key. This allows for constant-time average-case complexity for insertion, deletion, and retrieval operations, making it highly efficient compared to other data structures like arrays or linked lists.
4. Caching and Duplicate Detection: Hashing is utilized in caching mechanisms to quickly determine if data is already present in the cache. By comparing the hash values of the requested data with the stored hash values in the cache, duplicates can be identified and retrieved efficiently, reducing the need for expensive database or network calls.
5. Data Anonymization: Hashing can be used to anonymize sensitive data while still preserving its uniqueness. By hashing personally identifiable information (PII) like names, addresses, or social security numbers, the original data is transformed into a fixed-size hash value. This allows for data analysis and processing without revealing the actual sensitive information.
6. File and Data Comparison: Hashing is employed to compare files or large datasets quickly. Instead of comparing the entire contents byte by byte, hash values of the files or datasets can be calculated and compared. If the hash values match, it indicates that the files or datasets are likely identical, saving time and resources in the comparison process.
7. Blockchain and Cryptocurrency: Hashing plays a crucial role in blockchain technology and cryptocurrencies. In blockchain, each block contains a hash of the previous block, creating a tamper-evident chain of blocks. Hashing is also used in proof-of-work consensus algorithms, where miners compete to find a specific hash value to validate transactions and add new blocks to the chain.
8. Message Authentication and Digital Signatures: Hashing is a fundamental component of message authentication codes (MACs) and digital signature algorithms. By hashing the message or data and combining it with a secret key, the integrity and authenticity of the message can be verified. Digital signatures use hashing to create a unique signature that can be verified by recipients to ensure the origin and integrity of the data.
Disadvantages of Hashing
The main disadvantages of hashing are:
1. Hash Collisions: Hash collisions occur when two or more distinct inputs produce the same hash value. Although hash functions are designed to minimize collisions, they can still happen, especially with weak or poorly designed hash functions. Collisions can lead to ambiguity and potential security vulnerabilities if not handled properly. Resolving collisions often requires additional computational overhead and can impact the performance of hash-based systems.
2. Irreversibility: Hashing is a one-way process, meaning that it is computationally infeasible to reverse a hash value back to its original input. While this property is desirable for security purposes, such as storing passwords, it also means that if the original data is lost or forgotten, it cannot be recovered from the hash value alone. In cases where data needs to be retrieved or decrypted, hashing alone is not sufficient, and additional mechanisms like encryption or secure storage of the original data are necessary.
3. Key Management: In certain hashing applications, such as message authentication codes (MACs) or digital signatures, a secret key is used along with the hashing algorithm. The security of the system relies on the proper management and protection of these keys. If the keys are compromised or leaked, the integrity and authenticity of the hashed data can be undermined. Key management, including secure key generation, storage, and distribution, adds complexity to the overall system.
4. Computational Overhead: Hashing algorithms perform complex mathematical computations to generate hash values. While modern hashing algorithms are designed to be efficient, the computational overhead can still be significant, especially when hashing large amounts of data or performing frequent hash operations. This overhead can impact system performance and may require additional computational resources.
5. Limited Tampering Detection: Hashing can detect if data has been modified, but it cannot pinpoint the exact location or nature of the tampering. If a single bit is altered in the input, the resulting hash value will be entirely different, but it does not provide information about which part of the data was modified. In scenarios where more granular tampering detection is required, additional techniques like digital signatures or data verification algorithms may be necessary.
6. Susceptibility to Brute-Force Attacks: Hashing is vulnerable to brute-force attacks, particularly when the input space is relatively small or predictable. Attackers can generate a large number of possible inputs and compare their hash values with the target hash to find a match. This is especially concerning when hashing is used for password storage, as weak or commonly used passwords can be easily guessed or cracked using precomputed hash tables (rainbow tables).
7. Dependence on Secure Hash Algorithms: The security of hashing heavily relies on the strength and security of the underlying hash algorithm. If a hash algorithm is found to have weaknesses or vulnerabilities, it can compromise the entire system that depends on it. Therefore, it is crucial to choose well-established, extensively analyzed, and secure hash algorithms and to stay updated with any newly discovered vulnerabilities or attacks.
Hashing vs. encryption
Aspect
Hashing
Encryption
Purpose
Verify data integrity and authenticate data origin
Protect data confidentiality and secure communication
Reversibility
One-way process, irreversible
Two-way process, reversible with the correct key
Output
Fixed-size hash value, typically shorter than the input
Ciphertext, typically the same size or larger than the input
Key Usage
No key required for basic hashing, the key is used in keyed-hash functions (e.g., HMAC)
Requires a secret key for encryption and decryption
Security Focus
Data integrity, authentication, and non-repudiation
Data confidentiality and privacy
Collision Resistance
Hash functions aim to minimize collisions, but collisions can still occur
Not applicable, as encryption does not involve collisions
Vulnerability to Brute-Force Attacks
Vulnerable to brute-force attacks, especially for weak or commonly used inputs
Vulnerable to brute-force attacks if weak encryption keys are used
Typical Use Cases
Password storage, file integrity verification, digital signatures, blockchain
Secure communication, data storage, file protection, secure key exchange
Speed and Performance
Generally faster than encryption, as it does not involve complex mathematical operations
Slower than hashing due to the overhead of encryption and decryption processes
Data Recovery
Original data cannot be recovered from the hash value alone
Original data can be recovered from the ciphertext using the correct decryption key
Integrity Verification
Hashing provides data integrity verification by detecting any changes to the input data
Encryption alone does not provide data integrity verification, additional mechanisms like digital signatures are required
Frequently Asked Questions
What is the time complexity of insertion in a hashmap?
The time complexity of the insertion of an element in a hashmap is constant, which is O(1)
What is the difference between a map and an unordered_map in C++?
The data is stored in an ordered fashion in the map based on the ascending order of keys whereas the unordered_map stores the data in the fashion in that keys are inserted in.
What are the 3 hashing algorithms?
The three main hashing algorithms are the division method,the multiplication method, and universal hashing. The division method computes the hash value by taking the modulo of the key with the table size. The multiplication method multiplies the key by a constant and then takes the modulo with the table size. Universal hashing involves randomly selecting a hash function from a family of hash functions to minimize collisions.
Conclusion
In this blog, we discussed the concept of hashing. We explained what hashing is, the different types of hashing, why we need it and much more. We also looked at the reasons for hashing collision and the different methods to solve that like various collision resolution techniques,and at the end of the article,e we discussed many applications of hashing.
Recommended Problems:
Please head over to Coding Ninjas Studio and practice some famous interview problems and gain expertise in hashing.





























 9+ registered
9+ registered 
