Do you think IIT Guwahati certified course can help you in your career?
Introduction:
HashTable is a special type of table which maps different keys to different values. HashTable inherits the Dictionary class and implements the Map, Serializable, and Cloneable interface.
Properties of the HashTable:-
All the keys we add to the HashTable must implement the HashCode method. It provides a unique code to every key.
HashTable can be considered as an array of lists where each index of the list contains a bucket.
We can add only the unique keys in the HashTable.
One can not add null keys or values.
The initial default capacity of the HashTable class is 11 whereas load factor is 0.75.
Syntax to declare the java.util.Hashtable class:-
public class Hashtable<K,V> extends Dictionary<K,V> implements Map<K,V>, Cloneable, Serializable
K: It represents the type of keys we need to add to the HashTable.
V: It represents the type of values we need to add to the HashTable.
Constructors of HashTable:-
Constructors
Description
HashTable()
This constructor creates an empty HashTable of initial size and load factor.
HashTable(int capacity)
This constructor creates an empty HashTable of the mentioned ‘capacity’ size.
HashTable(int capacity, float loadFactor)
This constructor creates an empty HashTable of the mentioned ‘capacity’ size and loadFactor.
Hashtable(Map<? extends K,? extends V> t)
This constructor copies all the mappings of the passed table to the new table.
Example Code:-
import java.util.*;
public class Table {
public static void main(String[] args)
{
//Making a temp HashTable
Hashtable<String, Integer> temp = new Hashtable<>();
// Adding elements using put method
temp.put("vishal", 10);
temp.put("sachin", 30);
temp.put("vaibhav", 20);
// Different Hashtable with different constructors.
Hashtable<String, Integer> ht1 = new Hashtable<>();
Hashtable<String, Integer> ht2 = new Hashtable<>(5);
Hashtable<String, Integer> ht3 = new Hashtable<>(5, 1.01);
Hashtable<String, Integer> ht4 = new Hashtable<>(temp);
}
}
Important Methods of HashTable:-
Methods
Description
put(K key, V value)
This method add the specified key and map it with the specified value.
get(Object key)
This method returns the value associated with specified key.
remove(Object key)
This method removes the specified key from the HashTable.
size()
This method returns the total number of keys in the HashTable.
isEmpty()
This method returns true if the HashTable has no keys else false.
containsKey(Object key)
This method returns true if the specified key is present in the HashTable else false.
containsValue(Object value)
This method returns true if the specified value is associated with any key in the HashTable else false.
toString()
This method returns the String representation of the HashTable object.
replace(K key, V value)
This method replaces the old value of the specified key with the new value.
hashCode()
This method returns the HashCode value of the table.
clear()
This method is used to remove all the (Key, Value) pairs from the HashTable.
Example Code:-
import java.util.*;
public class Table {
public static void main(String[] args)
{
//Making a temp HashTable
Hashtable<String, Integer> table = new Hashtable<>();
// Adding elements using put method
table.put("vishal", 10);
table.put("sachin", 30);
table.put("vaibhav", 20);
// Removing the element from the table
table.remove("vishal");
// Checking if the table is empty or not
System.out.println(table.isEmpty());
//Getting the value associated to the specified key.
System.out.println(table.get("sachin"));
}
}
Hash Function Techniques:
Division:
The first order of business for a hash function is to compute an integer value
If we expect the hash function to produce a valid index for our chosen table size, that integer will probably be out of range
That is easily remedied by modding the integer by the table size
There is some reason to believe that it is better if the table size is a prime, or at least has no small prime factors
Folding:
Portions of the key are often recombined, or folded together
Shift folding: 123-45-6789 à 123 + 456 + 789
Boundary folding: 123-45-6789 à 123 + 654 + 789
Can be efficiently performed using bitwise operations
The characters of a string can be xor’d together, but small numbers result
Chunks of characters can be xor’d instead, say in integer-sized chunks
Mid-Square Function:
Square the key, then use the middle part as the result, example: 3121 à 9740641 à 406 (with a table size of 1000)
A string would first be transformed into a number, say by folding
Idea is to let all of the key influence the result
If the table size is a power of 2, this can be done efficiently at the bit level: 3121 à 100101001010000101100001 à 0101000010 (with a table size of 1024)
Extraction:
Use only part of the key to computing the result
Motivation may be related to the distribution of the actual key values, e.g., VT student IDs almost all begin with 904, so it would contribute no useful separation
Radix Transformation:
Change the base-of-representation of the numeric key, mod by table size
Not much of a rationale for it
A good hash function should:
Be easy and quick to compute
Achieve an even distribution of the key values that actually occur across the index range supported by the table
Ideally, be mathematically one-to-one on the set of relevant key values
Note: Hash functions are NOT random in any sense.
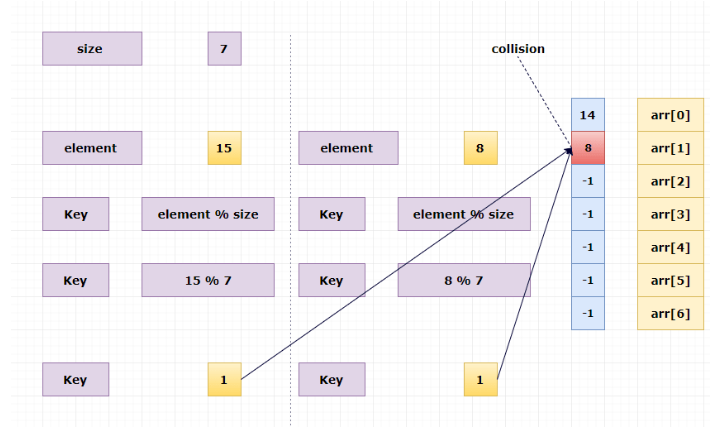
Collision:
It is a situation in which the hash function returns the same hash key for more than one record, it is called a collision. Sometimes when we are going to resolve the collision it may lead to an overflow condition and this overflow and collision condition makes the poor hash function.
What if we insert an element say 15 to existing hash table?
But already arr[1] has element 8. Here, two or more different elements pointing to the same index under modulo size, This is called a collision.
Collision Resolution Technique:
If there is a problem of collision occurs then it can be handled by applying some technique. These techniques are called as collision resolution techniques. There are generally four techniques which are described below.
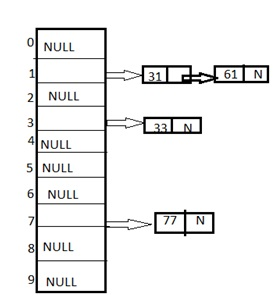
Chaining: It is a method in which additional field with data i.e. chain is introduced. A chain is maintained at the home bucket. In this when a collision occurs then a linked list is maintained for colliding data.
Example: Let us consider a hash table of size 10 and we apply a hash function of H(key)=key % size of the table. Let us take the keys to be inserted are 31,33,77,61. In the above diagram we can see at same bucket 1 there are two records which are maintained by linked list or we can say by chaining method.
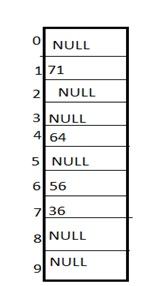
Linear Probing: It is a very easy and simple method to resolve or to handle the collision. In this collision can be solved by placing the second record linearly down, whenever the empty place is found. In this method there is a problem of clustering which means at some place block of a data is formed in a hash table.
Example: Let us consider a hash table of size 10 and the hash function is defined as H(key)=key % table size. Consider that following keys are to be inserted that are 56,64,36,71.
In this diagram we can see that 56 and 36 need to be placed at same bucket but by linear probing technique the records linearly placed downward if place is empty i.e. it can be seen 36 is placed at index 7.
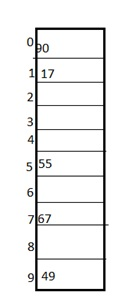
Quadratic Probing This is a method in which solving of clustering problem is done. In this method the hash function is defined by the H(key)=(H(key)+x*x)%table size. Let us consider we have to insert following elements that are:-67, 90,55,17,49.
In this, we can see if we insert 67, 90, and 55 it can be inserted easily but at the case of 17 hash function is used in such a manner that :-(17+0*0)%10=17 (when x=0 it provide the index value 7 only) by making the increment in the value of x. let x =1 so (17+1*1)%10=8.in this case bucket, 8 is empty hence we will place 17 at index 8.
Double Hashing: It is a technique in which two hash function is used when there is an occurrence of a collision. In this method, 1 hash function is simple as same as the division method. But for the second hash function, there are two important rules which are:
It must never evaluate to zero
Must sure about the buckets, that they are probed
The hash functions for this technique are:
H1(key)=key % table size H2(key)=P-(key mod P)
Where, p is a prime number which should be taken smaller than the size of a hash table.
Example: Let us consider we have to insert 67, 90,55,17,49.
In this, we can see 67, 90 and 55 can be inserted in a hash table by using the first hash function but in case of 17 again the bucket is full and in this case, we have to use the second hash function which is H2(key)=P-(key mode P) where p is a prime number which should be taken smaller than the hash table so the value of p will be the 7. i.e. H2(17)=7-(17%7)=7-3=4 that means we have to take 4 jumps for placing the 17. Therefore 17 will be placed at index 1.
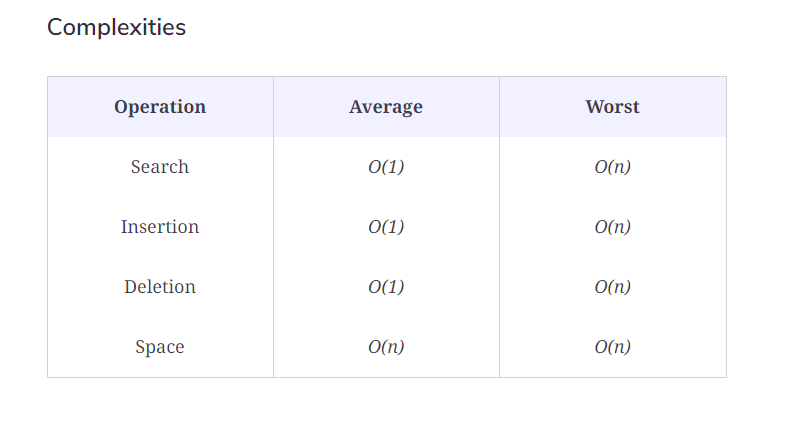
Basic Operations
Following are the basic primary operations of a hash table.
Search: Searches an element in a hash table
Insert: Inserts an element in a hash table
Delete: Deletes an element from a hash table
Initialise the hash bucket:
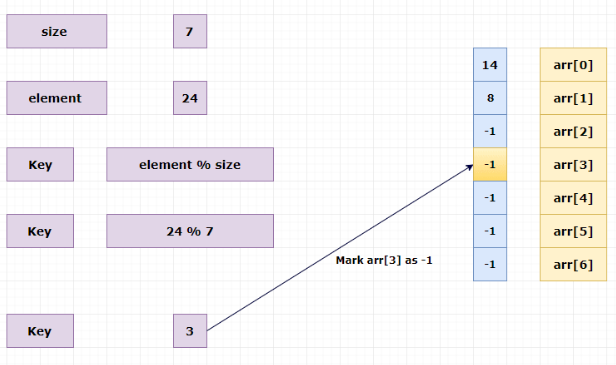
Before inserting elements into an array. Let’s make array default value as -1. -1 indicates element not present or the particular index is available to insert.
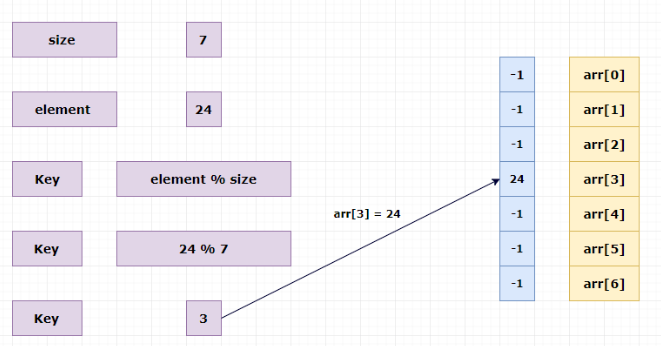
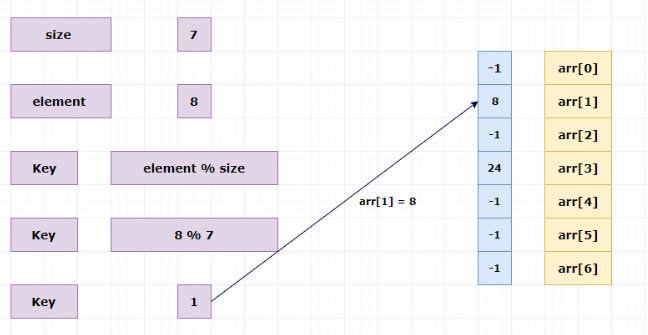
Inserting elements in the hash table:
Insert 24
Insert 8
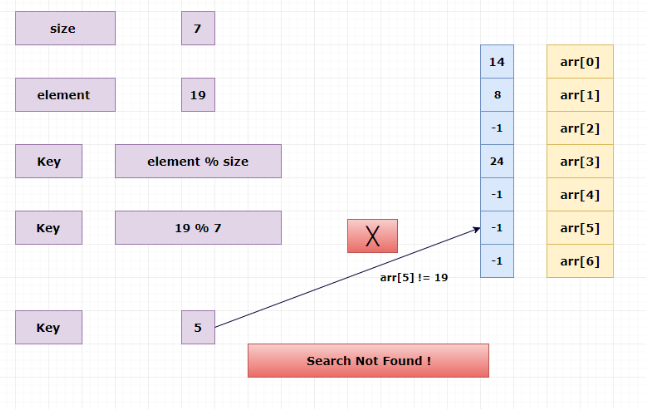
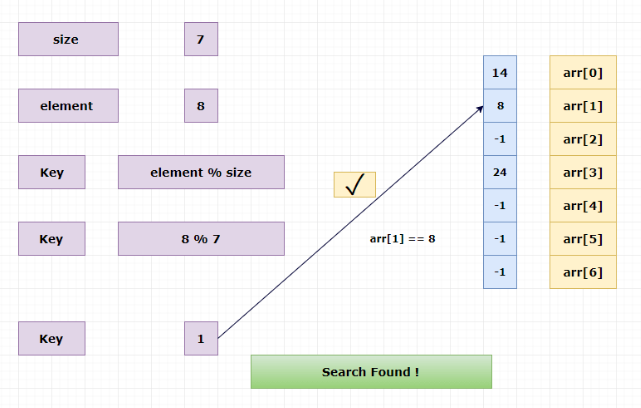
Searching elements from the hash table:
Search 19
Search 8
Deleting an element from the hash table:
Here, we are not going to remove the element. We just mark the index as -1. It indirectly deletes the element from an array.
Delete 24
Frequently Asked Questions:
What is a HashTable?
HashTable is a special type of table which maps different keys to different values. HashTable inherits the Dictionary class and implements the Map, Serializable, and Cloneable interface.
What are the initial default capacity and the load factor of the HashTable?
The initial default capacity of the HashTable class is 11 whereas the load factor is 0.75.
Conclusion
In this blog, we have covered the following things:
We first discussed what is HashTable.
Then we discussed its different methods and example code.
If you want to learn more about Programming Language and want to practice some questions which require you to take your basic knowledge on Programming Languages a notch higher, then you can visit our here.
Until then, all the best for your future endeavors, and Keep Coding.
Live masterclass
Prompt Engineering: New Must-Have GenAI Skill for Developers
by Anubhav Sinha
02 Aug, 2025
08:30 AM
Beyond ChatGPT: Build Skills for ₹30LPA+ GenAI Roles
by Anubhav Sinha
28 Jul, 2025
01:30 PM
Amazon Data Analyst Roadmap – From Resume to Interview
by Abhishek Soni
29 Jul, 2025
01:30 PM
Build ChatGPT-like Search Using RAG - Live with Google SDE3
by Saurav Prateek
30 Jul, 2025
01:30 PM
Amazon Data Analyst: Advanced Excel & AI Interview Tips
by Megna Roy
31 Jul, 2025
01:30 PM
Build Your First GenAI-Powered Job Search Tool
by Sumit Shukla
01 Aug, 2025
03:00 PM
Using Netflix Data to Master Power BI
by Ashwin Goyal
01 Aug, 2025
01:30 PM
Amazon India – Prime Day Sales data analysis using SQL
by Abhishek Soni
02 Aug, 2025
06:30 AM
Prompt Engineering: New Must-Have GenAI Skill for Developers
by Anubhav Sinha
02 Aug, 2025
08:30 AM
Beyond ChatGPT: Build Skills for ₹30LPA+ GenAI Roles






























 16+ registered
16+ registered 



