Do you think IIT Guwahati certified course can help you in your career?
Introduction
Many of you might have heard about problems that go like this - “given a weighted tree, requests for modification edges and queries finding the minimum on the edges between two vertices.” An exquisite data technique called heavy-light decomposition can be used to do this.
In this article, I’ll introduce you to the data structure, and heavy-light decomposition.
What is heavy-light decomposition?
Upon thinking a bit more, you might be feeling that you’ve heard the above problem before. Think!!
Yes! You recalled it right. We have solved a problem similar to this one, using segment trees. But, the problem here is that we’re given a tree. Whereas a segment tree can be built using an array. So, if we can reduce the given tree into arrays, the problem is solved! Heavy-light decomposition does that for us.
Let’s study it in detail.
Let there be a tree G of n vertices, with an arbitrary root. Heavy-light decomposition is a technique for decomposing a rooted tree into a set of paths. The essence of this tree decomposition is to split the tree into several paths/chains to reach the root vertex from any v by traversing at most logn paths. In addition, none of these paths should intersect with one another. A chain is a set of nodes connected one after another. It can be viewed as a simple array of nodes/numbers. We can do many operations on an array of elements with O( log N ) complexity using segment tree / BIT / other data structures. You can read more about segment trees here.
Why do we need heavy-light decomposition?
Suppose you have a problem that says:
You’re given an unbalanced tree of n nodes, and you have to perform actions to answer q queries. Each query can be of two types:
a) update(p,q) - update the value of the vertex with value p to value q.
b) maxEdge(p,q) - In the path from p to q, print the maximum value node.
For solving this problem, one might come up with a solution that traverses the whole tree once in each query. Note that this solution will have O(q*n) time complexity since traversing the tree takes O(n) time. This isn’t an efficient solution.
We can solve this problem in logarithmic time using heavy-light decomposition.
Construction algorithm
Basic idea
We will divide the tree into vertex-disjoint chains ( Meaning no two chains has a node in common ) in such a way that to move from any node in the tree to the root node, we will have to change at most log N chains. To put it in another word, the path from any node to root can be broken into pieces such that each element belongs to only one chain, then we will have no more than log N pieces.
Why logn?
A balanced binary tree of n vertices has a height of logn. You need to visit most log N nodes to reach the root node from any other node. Thus, even if you change the chain at each level of height, you’ll have to change no more than logn chains at most.
Terminologies
Heavy child:Among all child nodes of a node, the one with the maximum sub-tree size is considered a heavy child. Each non-leaf node has precisely one heavy child.
Heavy edge: For each non-leaf node, the edge connecting the node with its heavy child is considered a heavy edge. All the other edges are labeled as light.
Algorithm
First, calculate the size of the subtree, s(v), for each vertex v. Next, consider all the edges leading to the children of a vertex v. We call an edge heavy if it leads to a vertex c such that:
s(c)≥s(v)/2 ⟺edge (v,c) is heavy.
All other edges are labeled light.
Now we will decompose the tree into disjoint paths. Consider all the vertices from which no heavy edges come down. We will go up from each such vertex until we reach the tree’s root or go through a light edge. As a result, we will get several paths that are made up of zero or more heavy edges plus one light edge. The path that has an end at the root is an exception and will not have a light edge. Let these be called heavy paths - these are the desired paths of heavy-light decomposition.
Proof that at most one edge will be heavy: It is evident that at most, one heavy edge can emanate from one vertex downward because otherwise, the vertex v would have at least two children of size ≥s(v)2, and therefore the size of the subtree of v would be too big, s(v)≥1+2s(v)2>s(v), which leads to a contradiction.
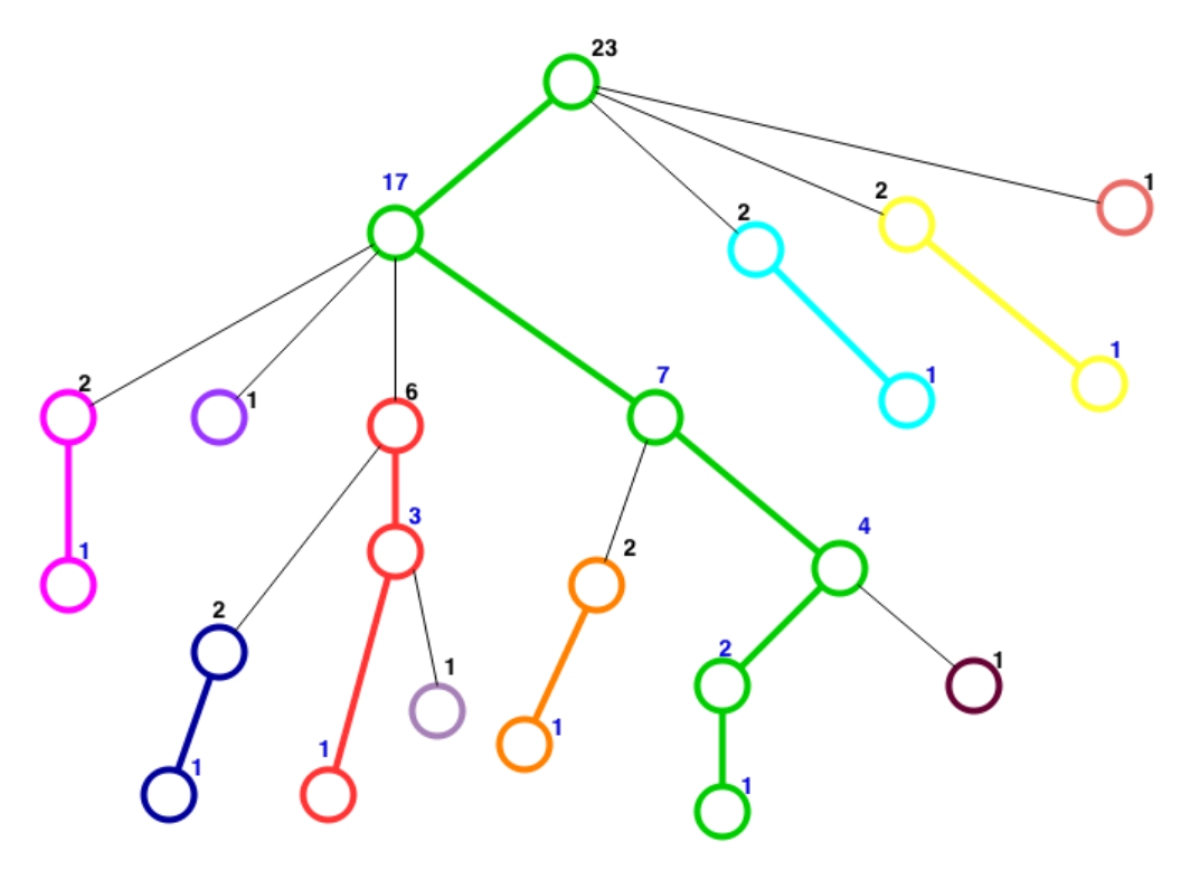
Below is an example tree with its hld done:
Each chain is represented by a different color here. The edges in black connect two chains.
How to solve query problems using heavy-light decomposition?
Now that you’ve understood why we need hld and what it is let’s see how it answers our queries.
update(p,q) 1. Over each heavy path, we will construct a segment tree, which will allow us to search for a vertex with the maximum assigned value in the specified segment of the defined heavy path in O(logn). 2. Perform the update using the update of segment trees. 3. Therefore, the time complexity of the update operation will be O(logn).
maxEdge(p,q) 1. Over each heavy path, we will construct a segment tree, which will allow us to search for a vertex with the maximum assigned value in the specified segment of the specified heavy path in O(logn). 2. To answer a query (a,b), we find the lowest common ancestor of a and b as l by any preferred method.
Now the task has been reduced to two queries (a,l) and (b,l), for each of which we can do the following: find the heavy path that the lower vertex lies in, make a query on this path, move to the top of this path, again determine which heavy path we are on and make a query on it, and so on, until we get to the path containing l.
One should be careful with the case when, for example, a and l are on the same heavy path - then the maximum query on this path should be done not on any prefix but on the internal section between a and l.
Responding to the subqueries (a,l) and (b,l) each requires going through O(logn) heavy paths, and for each path, a maximum query is made on some section of the path, which again requires O(logn) operations in the segment tree. Hence, one query (a,b) takes O(log^2n) time.
C++ implementation
For doing the heavy-light decomposition, we need to perform 2 steps.
Calculate the subtree size for each node
Decompose the tree into disjoint chains
Let’s talk about the implementation of each part separately.
Calculate the subtree size for each node
We can run a dfs call for doing this. Basically, subtree size of any node is the sum of (the subtree sizes of all its children)+1. Also, the subtree sizes of all the leaf nodes is 1 as there are no children.
int subtree_size[N] = {0}; // subtree_size[i] will denote the subtree size of the //ith node.
int dfs(int curr,int parent) {
// subtree size of any node = sum of subtree size of its children+1.
int ans=1;
for(auto x:adj[curr]){
if(x!=parent){
ans+=dfs(x,curr); // Add the subtree sizes of the children
}
}
// Update the subtree_size of current node to ans and return it
return subtree_size[curr] = ans;
}
Decompose the tree into disjoint chains
This is the part of HLD. We make a function named HLD and pass the parameters node and the current chain to it. In the HLD function:
Add the current node to the current chain.
If the current node is the leaf node, just end the process and return.
Otherwise, traverse through each child node of the current node and find the heavy child.
Call the HLD function for the heavy node with the same chain.
For the light children of the current node, call the HLD function but with a new empty chain as the old chain won’t be continuing here.
The above steps are doing HLD correctly. But while writing this into code, we’ll be short of information. We need a bit more information. We need to find the answer of the problems:
Given a node, to which chain does that node belong?
Given a node, what is the position of that node in its chain?
Given a chain, what is the head of the chain?
Given a chain, what is the length of the chain?
To answer these, we’ll have some variables: chainNo -> which tells the current chain number we’re on. (initializing it 0 as there will be no chains in the beginning) chainHead[N] -> which tells the chain head of the chain ith node belongs to. (Initializing for each node to -1 as initially there is no chain, so no heads) chainPos[N] -> which tells the position of the ith node in the chain. chainInd[N] -> which tells the index of the chain ith node belongs to. chainSize[N] -> which tells the size of the chain the ith node belongs to. (initializing it 0 as initially, all the sizes will be 0)
In the HLD function, for the current node:
We check if the chain head of the current chain number is -1 or not. If the head is not -1, this means that no new chain is forming from this node and it is a part of the earlier chain only. So the head remains the same. Otherwise, we have started a new chain from the current node and thus, chainHead of the current chain number will be this node.
Update the value of chainIn of the node to the current chain number. Update the value of the chain position of the current node to the chain size of the chain it belongs to. Increase the size of the current chain by 1.
If the current node is not a leaf, find its heavy child by finding out the child which has the maximum subtree size.
If you’ve got a heavy child, call HLD for the heavy child while keeping the chain the same.
For the light children, call HLD by increasing the chain number by 1 each time as there will be a new chain-forming from each such child.
Below is the implementation of the HLD function:
void hld(int cur) {
/*check if the chain head of the current chain number is -1 or not. If the //head is not -1, this means that no new chain is forming from this node and it is //a part of the earlier chain only. So the head remains the same. Otherwise, we //have start a new chain from the current node and thus,
//chainHead of the current chain number will be this node.*/
if(chainHead[chainNo] == -1) chainHead[chainNo]=cur;
//Update the value of chainIn of the node to current chain number.
chainInd[cur] = chainNo;
//Update the value of chain position of the current node to the chain size of //the chain it belongs to.
chainPos[cur] = chainSize[chainNo];
//Increase the size of the current chain by 1.
chainSize[chainNo]++;
// Finding the heavy child
int heavy_child = -1,mx = -1;
for(int i = 0; i < adj[cur].sz; i++) {
if(subtree_size[ adj[cur][i] ] > mx) {
mx = subtree_size[ adj[cur][i] ];
heavy_child = i;
}
}
//If you've got the heavy child, call HLD for the heavy child while
//keeping the chain same.
if(heavy_child >= 0) hld( adj[cur][heavy_child] );
//For the light children, call HLD by increasing the chain number
//by 1 each time as there will be a new chain forming from each such child.
for(int i = 0; i < adj[cur].sz; i++) {
if(i != heavy_child) {
chainNo++;
hld( adj[cur][i] );
}
}
}
The main idea of Heavy Light Decomposition of an unbalanced tree is to club vertices of long (or heavy) paths together in chains so that these linear chains can be queried in O(Logn) time using a data structure like Segment Tree.
What is the time complexity of heavy light decomposition?
The time complexity of Heavy-Light Decomposition is O(log N), where N is the number of vertices in the tree, making it efficient for various tree-based algorithms.
What are the components of HLD?
Heavy-Light Decomposition consists of the Heavy Chain, Light Chain, and LCA (Lowest Common Ancestor) computation components, crucial for optimizing tree traversal and query operations.
Where are segment trees used?
Segment Tree is used in cases where there are multiple range queries on an array and modifications of elements of the same array.
Conclusion
In this article, we discussed a very useful and interesting technique called heavy-light decomposition. We started off by discussing why exactly is it needed, then moved on to what heavy-light decomposition is, how its algorithm work and how is it used to solve the range query problems. We also saw the implementation of HLD in C++. Using HLD in solving problems requires the use of segment trees also. So if you’re not familiar with segment trees, it’s highly recommended to refer to this article.
To practice more such problems, Coding Ninjas Studio is a one-stop destination. You can also attempt our Online Mock Test Series. This platform will help you acquire effective coding techniques and give you an overview of student interview experience in various product-based companies.































 9+ registered
9+ registered 

