Get a skill gap analysis, personalised roadmap, and AI-powered resume optimisation.
Introduction
Hive Architecture provides a structured framework for managing and analyzing large datasets stored in Hadoop. It facilitates data querying and management through a SQL-like interface, allowing users to write queries in HiveQL. With a focus on scalability and extensibility,
Hive's architecture consists of components like the Hive Metastore, Driver, Compiler, and Execution Engine, enabling efficient data processing and retrieval.
What is Hive and how does it work?
Hive is a data warehousing tool built on top of Hadoop that facilitates the querying and analysis of large datasets stored in the Hadoop Distributed File System (HDFS). It provides a SQL-like interface called HiveQL, which allows users to write queries to perform operations on large datasets without needing to know complex MapReduce programming.
How Hive Works
Data Storage: Hive stores data in a structured format in HDFS. The data can be in various formats, including text files, ORC, Parquet, and Avro.
Schema Definition: Users define a schema in Hive using tables and columns, similar to traditional relational databases. This schema maps to the underlying data files in HDFS.
Querying with HiveQL: Users write queries in HiveQL to perform data manipulation and retrieval. Hive translates these queries into MapReduce jobs that run on the Hadoop cluster.
Execution Process:
Parser: The HiveQL query is first parsed to check for syntax and semantic correctness.
Compiler: The parsed query is then compiled into a logical plan.
Optimizer: The logical plan is optimized to improve query performance.
Execution: Finally, the optimized plan is converted into a series of MapReduce jobs, which are executed on the Hadoop cluster.
Results: After the execution of the MapReduce jobs, Hive collects the results and presents them to the user.
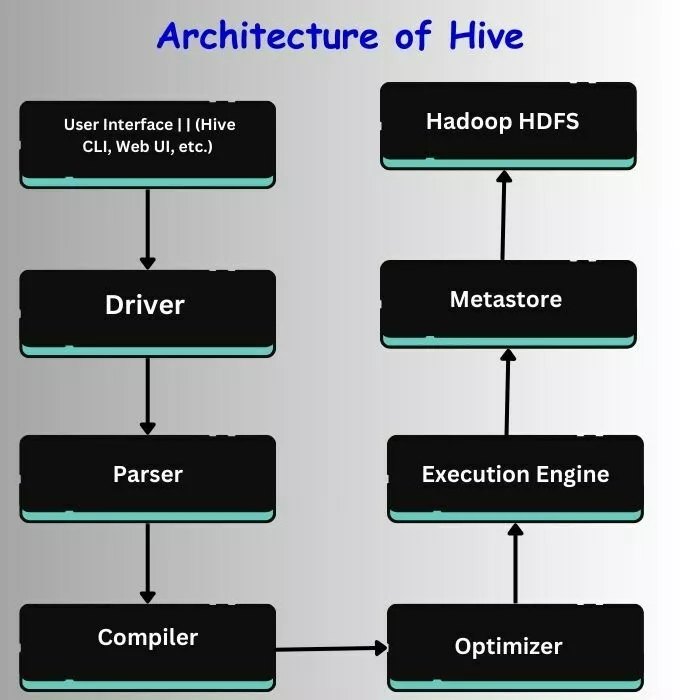
Architecture of Hive
Hive's architecture is designed to facilitate data processing and analysis over large datasets stored in the Hadoop ecosystem. It comprises several key components that work together to provide a seamless querying experience.
Understanding Apache Hive requires foundational knowledge of Hadoop. Hadoop, a framework for distributed storage and processing of large data sets, provides the groundwork on which Hive operates. Hive extends Hadoop's functionality, offering a more accessible and SQL-like interface for big data operations.
Hive's architecture is ingeniously crafted atop Hadoop, optimizing data warehousing capabilities. At its core, Hive transforms queries written in HiveQL, its SQL-like language, into Hadoop jobs. The architecture consists of key components:
Hive Server
It acts as the gateway for clients to interact with Hive. It receives HiveQL queries from various clients and forwards them for execution. There are two types of Hive servers - Hive Server1 for synchronous processing and Hive Server2 for asynchronous and more robust processing capabilities.
Driver
The heart of the Hive query processing mechanism. It manages the lifecycle of a HiveQL query. When a query arrives, the driver receives it and proceeds to create a session handle if one doesn't already exist.
Compiler
This component takes the HiveQL query from the driver and compiles it into an Abstract Syntax Tree (AST), translating the high-level query into a series of steps that can be executed.
Optimizer
After the AST is created, Hive's query optimizer kicks in. It transforms the logical plan into an optimized plan, rearranging steps and applying different techniques to enhance efficiency.
Executor
This is where the action happens. The optimized plan is executed over the Hadoop cluster. The executor interacts with Hadoop's JobTracker (for MapReduce) or ApplicationMaster (for YARN) to schedule and execute the tasks.
MetaStore
A critical component, the Metastore, stores metadata about the structure of the database, tables, columns, and data types. It's a relational database containing all the necessary information to execute queries correctly.
Hive Clients
These are interfaces through which users interact with Hive, such as command line (CLI), JDBC (Java Database Connectivity), and ODBC (Open Database Connectivity).
Command-Line Interface (CLI)
The CLI allows users to execute Hive queries directly in the command prompt or terminal. It’s mainly used for ad-hoc queries, debugging, and automation in scripts. CLI connects directly to the Hive metastore for quick query execution.
Java Database Connectivity (JDBC)
JDBC is a Java API that enables Java applications to interact with Hive databases. It’s ideal for Java-based applications needing to query and analyze Hive data, supporting complex, reusable interactions between Hive and Java programs.
Open Database Connectivity (ODBC)
ODBC provides a language-agnostic interface for connecting non-Java applications to Hive. It’s widely used for integrating Hive with BI tools and applications across different languages, enabling easy access to Hive data for analysis and reporting.
HDFS (Hadoop Distributed File System)
The backbone of Hive, where actual data resides. Hive queries are executed against data stored in HDFS.
YARN (Yet Another Resource Negotiator)
It manages resources in the Hadoop cluster and schedules jobs.
Job Execution Flow in Hive Architecture
In Hive, job execution follows a systematic flow that converts high-level queries into MapReduce jobs for processing within the Hadoop ecosystem. This flow ensures efficient query handling, from user query submission to final result generation. Understanding this process helps to optimize query performance and manage large data workloads effectively.
Let's understand the job execution flow:
Step 1 - Query Submission
Users submit queries to Hive through various interfaces like CLI, JDBC, or ODBC. The Hive Server receives these queries.
Step 2 - Query Compilation
Once a query is received, the Hive Driver initiates the compilation process. The query is parsed into an Abstract Syntax Tree (AST), representing the query's hierarchical structure.
Step 3 - Logical Plan Generation
The AST is converted into a logical plan, outlining the sequence of operations required to execute the query.
Step 4 - Logical Plan Optimization
The logical plan undergoes optimization for efficient execution. This involves reordering operations, applying optimization algorithms, and resolving data dependencies to reduce execution time and resource consumption.
Step 5 - Physical Plan Generation
The optimized logical plan is then converted into a physical plan, detailing the specific tasks to be executed on the Hadoop cluster.
Step 6 - Task Submission
The Executor submits these tasks to the Hadoop cluster. Depending on the Hive configuration and cluster setup, these tasks are executed as MapReduce or Tez jobs.
Step 7 - Job Execution
Hadoop's JobTracker (for MapReduce) or ApplicationMaster (for YARN) schedules and manages the execution of these tasks across the cluster. This step involves data processing, shuffling, sorting, and reducing based on the query's requirements.
Step 8 - Data Retrieval and Output
Once the tasks are executed, the processed data is retrieved and compiled into a format specified in the HiveQL query. The output is then returned to the user.
Step 9 - Handling Intermediate Data
Throughout the process, intermediate data generated by various tasks is stored and managed efficiently, ensuring optimal use of resources.
Step 10 - Error and Exception Handling
The Hive system continuously monitors for errors or exceptions during execution. In case of any failures, appropriate error messages are communicated back to the user, and recovery or rollback processes are initiated.
Features of Hive
Below, we have discussed the features of the hive:
Scalability: Hive's distributed nature allows for scaling by simply adding more nodes to the Hadoop cluster, making it adept at handling growing data volumes.
Data Accessibility: HiveQL, resembling SQL syntax, democratizes data accessibility, enabling users to query big data without deep knowledge of Java (the language of MapReduce).
Data Integration: Hive complements other Hadoop ecosystem tools like Pig, HBase, and MapReduce, ensuring a cohesive data processing environment.
Flexibility: It effortlessly processes both structured and unstructured data in formats like CSV, JSON, and Parquet.
Security: Hive strengthens data security through authentication, authorization, and encryption mechanisms.
Limitations of Hive
High Latency: Compared to traditional databases, Hive exhibits slower query execution, attributed to the overhead in a distributed system.
Limited Real-time Processing: Primarily designed for batch processing, Hive is not optimal for real-time data analytics.
Complexity: Setting up and managing Hive necessitates proficiency in Hadoop, SQL, and data warehousing concepts.
Lack of Full SQL Support: HiveQL, while powerful, does not fully support all SQL operations like transactions and indexes.
Debugging Challenges: Troubleshooting Hive queries is complex, as they are executed across a distributed system.
Frequently Asked Questions
How does Hive handle security?
Hive incorporates several security features including authentication, authorization, and encryption to safeguard data integrity and privacy.
What is Hive workflow?
Hive workflow defines a sequence of actions or processes in Hive, including query execution, data transformations, and loading, to streamline and automate data processing tasks within Hive.
What is Hive best used for?
Hive is best used for querying, analyzing, and managing large datasets stored in Hadoop, making it ideal for data warehousing tasks in big data environments.
Is Hive an ETL tool?
While not a traditional ETL tool, Hive can perform ETL functions by transforming and loading data through queries, although it primarily functions as a data warehousing and querying tool.
Conclusion
Apache Hive stands as a cornerstone in the realm of big data, leveraging Hadoop's capabilities while simplifying user interaction with a SQL-like interface. Its scalability, data accessibility, and integration with the Hadoop ecosystem make it an indispensable tool. However, awareness of its limitations, like high latency and complexity, is essential. Hive exemplifies the balance between accessibility and power in big data processing, making it a critical component in the data engineer's toolkit.































 9+ registered
9+ registered 

