Do you think IIT Guwahati certified course can help you in your career?
Introduction
Imagine you are the head of a department in your company and want to find the list of unique names in your department. One way of doing this is by using SQL queries to create a list of unique names.
SQL queries are the commands we use to get some information from a database. In this blog, we will discuss how to find duplicate records in SQL, including their Importance.
There are different ways to identify duplicate values in tables in SQL.
In SQL, using the select command with where and having a clause, you can identify the duplicate values in SQL. Below is the syntax to identify the duplicate values in the table.
SELECT ColumnName, COUNT(ColumnName) AS count FROM TableName GROUP BY ColumnName HAVING COUNT(ColumnName) > 1;
In this, you select the column that you want to check duplicity for with count to count the same columns that may have the same data.
Duplicate Values in One Column
To identify duplicate values in one column, you can use the below syntax:
SELECT ColumnName, COUNT(ColumnName) AS ColumnName FROM TableName GROUP BY ColumnName HAVING COUNT(ColumnName) > 1;
Let's understand this through an example below:
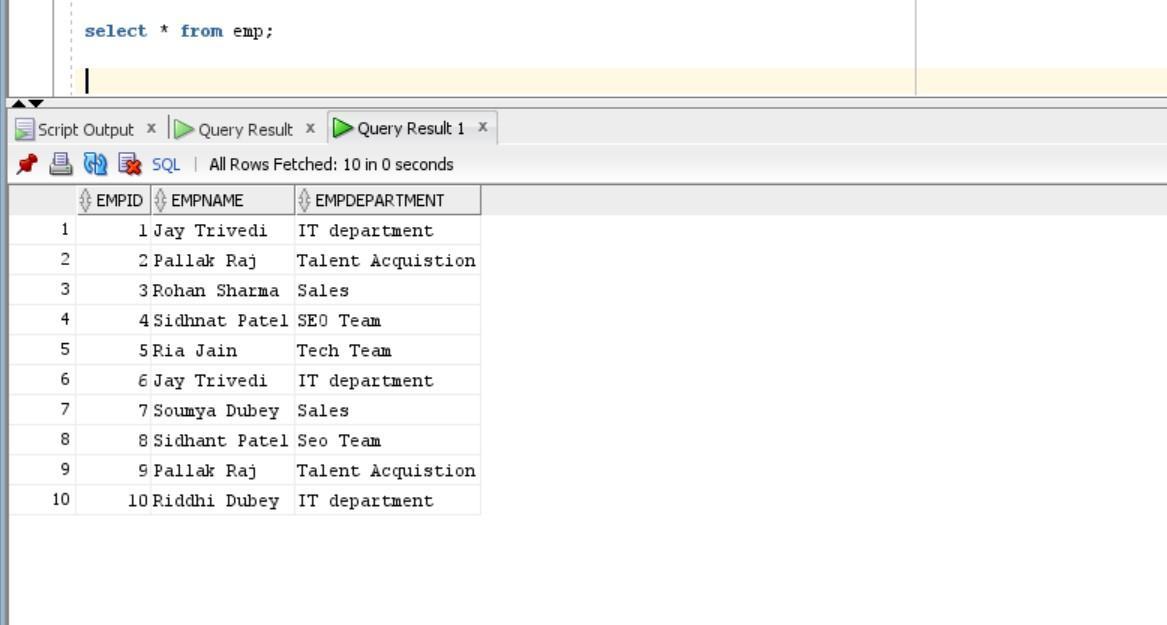
Consider we have an employee table and the table name is emp. Below is the data that is stored in the emp table.
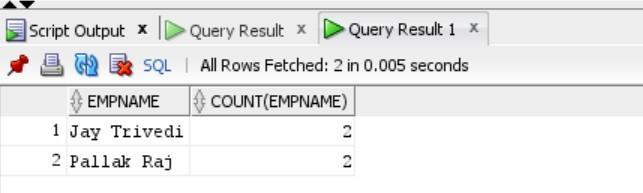
In our case, let's find duplicate values in one column empname and to do so, we use the below syntax:
SQL
SQL
Select empname, count(empname) as empname from emp group by empname having count (empname) > 1;
Output
Duplicate Values in Multiple Columns
To identify duplicate values in multiple column, you can use the below syntax:
SELECT ColumnName1,count(ColumnName1), ColumnName2,COUNT(ColumnName2) AS ColumnName FROM TableName GROUP BY ColumnName1, ColumnName2 HAVING COUNT(ColumnName1) > 1 AND COUNT(CoulumnName2)>1;
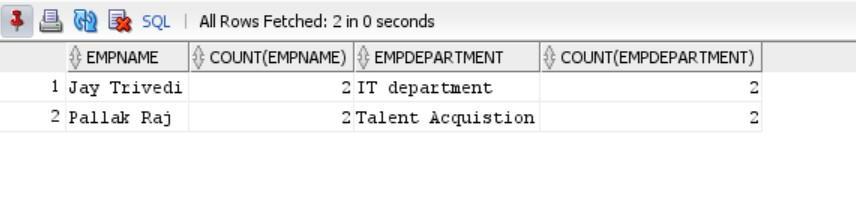
Let's understand this with the emp table: In our case, let's find duplicate values in one column empname, empdepartment, and to do so, we use the below syntax:
SQL
SQL
select empname, count(empname), empdepartment, Count(empdepartment) from emp group by empname,empdepartment having count(empname)> 1 AND count (empdepartment) > 1;
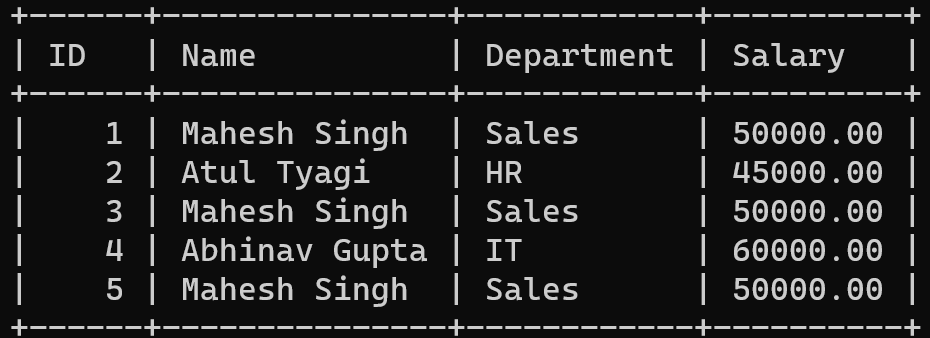
Duplicate Records are the rows in our database that are identical to one another. For our sample dataset, we can see that there are three identical rows with the same name (“Mahesh Singh”), Department (Sales) and Salary (50000.00).
Now let us discuss some methods used to find Duplicate records in the SQL Table we created in the previous section.
Using GROUP BY and HAVING
We can use GROUP BY and HAVING statements to find duplicate records. GROUPBY statements group the columns containing duplicate entries. The HAVING clause is used to find the entries with the count of certain entries greater than one.
Syntax
Here is the basic syntax for using GROUPBY statement and HAVING clause.
SELECT column1, column2, ..., COUNT(*) AS count
FROM table
GROUP BY column1, column2, ...
HAVING COUNT(*) > 1;
Example
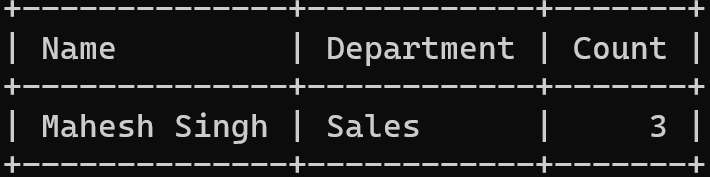
Let us consider the SQL table company and try to find its duplicate records using GROUP BY and HAVING statements.
SQL Query
SELECT Name, Department, COUNT(*) as Count
FROM Company
GROUP BY Name, Department
HAVING COUNT(*) > 1;
Output
Explanation
In this example, we grouped the Name, Department and counted the number of records of each record. If the count of any record is greater than one, we return the name, Department and count of that record.
Using Self Joins
We can also join the table with itself to find the duplicate record in SQL.
Syntax
Here is the basic syntax for using Self Join.
SELECT tab1.column1, tab1.column2, ...
FROM table tab1
JOIN table tab2 ON tab1.column1 = tab2.column1 AND tab1.column2 = tab2.column2 AND...
WHERE t1.id <> t2.id;
Example
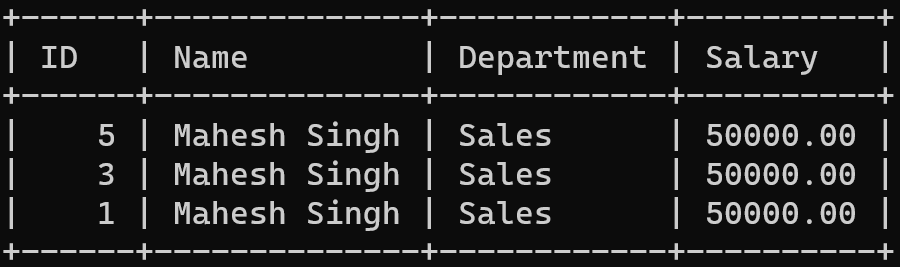
Let us consider the SQL Table company and try to find its duplicate records using Self Join.
SQL Query
SELECT DISTINCT a.*
FROM Company a
JOIN Company b ON a.Name = b.Name AND a.Department = b.Department
WHERE a.ID <> b.ID;
Output
Explanation
In this case, we know that the duplicates are based on having the same Name, Department, and Salary values. So our output displays three rows of different ids, which tells us that there are three duplicate records for the name "Mahesh Singh" in the Sales with a salary of 50000.00.
Using ROW_NUMBER() Function
We can also use the ROW_NUMBER function to give a specific row number to each record based on the duplicates and select the record with a row number greater than one.
Syntax
Here is the basic syntax for using the ROW_NUMBER function.
WITH num_rows AS (
SELECT column1, column2, ...
ROW_NUMBER() OVER (PARTITION BY column1, column2, ... ORDER BY column1) AS row_num
FROM table
)
SELECT column1, column2, ...
FROM num_rows
WHERE row_num > 1;
Example
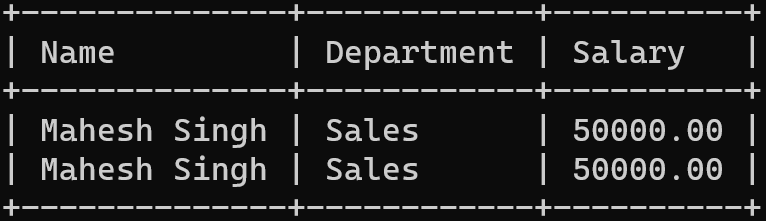
Let us consider the SQL Table company and try to find its duplicate records using the ROW_NUMBER function.
SQL Query
WITH numbered_rows AS (
SELECT Name, Department, Salary,
ROW_NUMBER() OVER (PARTITION BY Name, Department, Salary ORDER BY Name) AS row_num
FROM Company
)
SELECT Name, Department, Salary
FROM numbered_rows
WHERE row_num > 1;
Output
Explanation
In this example, we use the ROW_NUMBER() function and partition the data by the Name, Department, and Salary columns.
We allot a unique row number to each record. The row_num column helps us identify the duplicates.
Now we select the Name, Department, and Salary columns from the numbered_rows where the row number exceeds one.
Why Duplicates in SQL Are Bad
Duplicates in SQL tables are bad for various reasons:
Ambiguity error: When we have duplicate records in SQL, it can lead to unpredictable results which makes it difficult to understand and analyze the data.
Data Redundancy: Duplicate records often lead to data redundancy. It consumes unnecessary space and consumes more time to fetch the query.
Low performance: Duplicate records in the table lead to low performance. This means performance gets hampered as query output time is increased.
Data Integrity: It is another important issue when we have duplicate records in our table. Data consistency and integrity is disturb.
Comparison Table
Now, we will look at the comparison table for the best method for finding duplicate records in SQL.
Method
Description
Use Cases
GROUP BY and HAVING
We group entries based on specified columns and filters for groups with a count greater than 1.
Identifying duplicate entries in a dataset.
Finding records with multiple occurrences based on specific criteria
Self Join
We compare every record with other records having the same values for specified columns but different IDs.
Finding exact duplicates in a table.
Identifying records with identical values for specific columns
ROW_NUMBER()
We assign a row number to each record using the ROW_NUMBER() function.
Filtering duplicate records based on a specific order ranking duplicate records within the same group.
Importance of Finding Duplicates
Now, let us look at why it is crucial to find duplicates in SQL.
It improves our data quality, which reduces any difficulty during data analysis.
It reduces the space taken by the dataset as the duplicate entries are removed.
It also removes any errors or faults in our dataset, maintaining data integrity.
To find duplicates in data using SQL, we make use of the select command with where and having clause. This helps in the easy detection of duplicate data in the tables.
Q. How do I prevent duplicates in SQL?
To prevent duplicate records in SQL tables, SQL provides us with multiple features like applying constraints, validation rules, indexes, normalization, data checks, triggers and much more. This functionality helps in preventing duplicate records in the table.
Q. How to find duplicate records in SQL without count?
To find duplicate records in SQL without the count method, you can use self-join in SQL with group by and having clause.
Q. How do I identify and DELETE duplicate records in SQL?
To identify duplicate records in SQL, you can use the CTE (Common Table expression) or RowNumber. To later delete duplicate records in SQL, use the delete command in SQL. Also, we can use the DELETE statement within the queries to remove duplicate records.
Conclusion
This article discusses the topic of finding duplicate records in SQL. In this blog, we have discussed how to find duplicate records in SQL, including their importance.
We hope this blog has helped you enhance your knowledge of View in SQL. If you want to learn more, then check out our articles.





























 8+ registered
8+ registered 

