Do you think IIT Guwahati certified course can help you in your career?
Introduction
Splitting a Torch dataset is a fundamental task in machine learning and deep learning pipelines that involves dividing a dataset into two or more subsets to ensure that the model's performance can be evaluated accurately and helps prevent overfitting. In this guide, we'll explore a straightforward approach to splitting a Torch dataset using Python's PyTorch library.
In this, you'll be better equipped to manage and optimise your machine learning workflows.
Why Dataset Splitting?
Dataset splitting is a crucial step in machine learning, where you divide your data into different parts for training, validation, and testing. This helps you build and evaluate your model effectively. So, Splitting datasets is like dividing a cake for different purposes in machine learning.
Here's a simple breakdown:
Training Data
This is the largest part of your dataset and is used to teach your model patterns and relationships in the data.
Validation Data
A smaller part of the data is used to fine-tune your model's parameters and settings. It helps prevent overfitting by assessing the model's performance on unseen examples.
Testing Data
This is a separate portion used to evaluate the final performance of your trained model. It gives you an estimate of how well your model might perform on real-world, new data.
Remember, these parts should be distinct and not overlap; each slice has a job, and keeping them separate makes sure your model is well-prepared, not too adjusted, and can prove its worth reliably.
Type of Dataset Splits
Here are the types of dataset splits explained simply:
Train-Test Split
Train-test split means dividing your toys before playing. You use some toys for practice (train) and keep others untouched (test) to check how well you've learned to play. It's like practising a game and then testing if you can play it for real.
Imagine sharing cookies with a friend. You keep most for yourself (train) to learn how to bake and give a few to your friend (test) to see if your baking skills are good.
Train-Validation-Test Split
Train-validation-test split is like learning, practising, and proving yourself. You study hard (train), do some practice quizzes (validation), and finally take the big test (test) to show you've mastered the subject. It's like getting ready step by step for the final challenge. It's like preparing for a test. You study a lot (train), review with a friend (validation), and finally, take the actual test (test) to see how well you've learned.
K-Fold Cross-Validation
K-Fold Cross-Validation is like trying out different ways to learn. Instead of just one big test, you take your learning material and divide it into smaller sections (folds). You study using some sections (train) and then test yourself using the others (validation). You do this multiple times, using different sections as your testing ground each time. It's like having many mini-tests to make sure you really understand everything. Pretend you have many quizzes. You keep one as a test and the rest as training. Then you rotate which quiz is the test to see how well you'd do on different types of questions.
Stratified Split
Stratified split is like keeping a balanced mix. If you have different flavours of candies, you make sure each pile has a similar mix of flavours. This way, when you split the candies into groups (train and test), each group tastes like the whole variety. It's like sharing candies fairly to represent all the flavours.
Imagine sorting candies by colour and then dividing them. You make sure each pile has the same mix of colours so each split (train or test) represents the whole better.
Time-Based Split
Time-based split is like reading a story step by step. You start from the beginning (train) to understand the plot, then pause in the middle (validation) to discuss what's happening, and finally reach the end (test) to see if you can predict how the story concludes. It's like following the timeline of events to see how well you can understand and anticipate what comes next.
Think of your life in chapters. You learn from past experiences (train), get advice while you go (validation), and test your skills in the present (test) to prepare for the future.
Leave-One-Out Cross-Validation
Leave-One-Out Cross-Validation is like testing your memory with friends. You have a group of friends, and you take turns hanging out with each friend separately (test) while the rest stay together (train). You repeat this with every friend, so each time, you're learning from the group and then checking if you remember well when you're alone with one friend. It's a way to see if you truly understand and can recall things on your own.
Like having many friends test your cooking. You serve each friend (test) a meal you cooked with one ingredient left out (leave-one-out) and see if they notice the missing flavour.
Remember, these splits help you train, tune, and evaluate your model with different techniques, making sure it's ready for real-world challenges.
Common Splitting Techniques
Here are common splitting techniques explained simply:
Random Splitting Technique
Random splitting is a technique used to divide your dataset into training and testing portions in a fair and unbiased manner. Here's a more detailed explanation without plagiarism.
Random splitting is like shuffling cards. You have a deck of cards (your data), and you randomly pick some for practice (train) and some for testing (test). It's like mixing things up to make sure your model learns from a variety of examples and can handle new ones it hasn't seen before.
Imagine you have a collection of colourful marbles, and you want to see how well your magic marble-predicting skills work. To do this, you need to train your magical powers using some marbles and then test them on marbles you haven't seen before.
Step 1 Gathering Marbles
First, you collect all your marbles, making sure you have a good mix of different colours and patterns.
Step 2 Random Shuffle
Just like shuffling a deck of cards, you mix up the marbles randomly. This ensures that you don't accidentally favour any specific colour or pattern in either the training or testing sets.
Step 3 Splitting
After shuffling, you divide the marbles into two groups. You take a bunch of marbles for practising your magic (training set) and another set for testing how accurate your predictions are (testing set).
Step 4 Magic Practice
You use the marbles in the training set to practise your magic. You learn the subtle hints and tricks that each colour and pattern might reveal.
Step 5 Magic Test
Once you're confident in your magical skills, you take the marbles in the testing set that you haven't used for practice. You predict their colours and patterns using your magical powers and see how accurate you are.
The key here is that you shuffled the marbles randomly before splitting them into training and testing sets. This prevents any bias and ensures that your magical abilities work well, not just on marbles you've practised with.
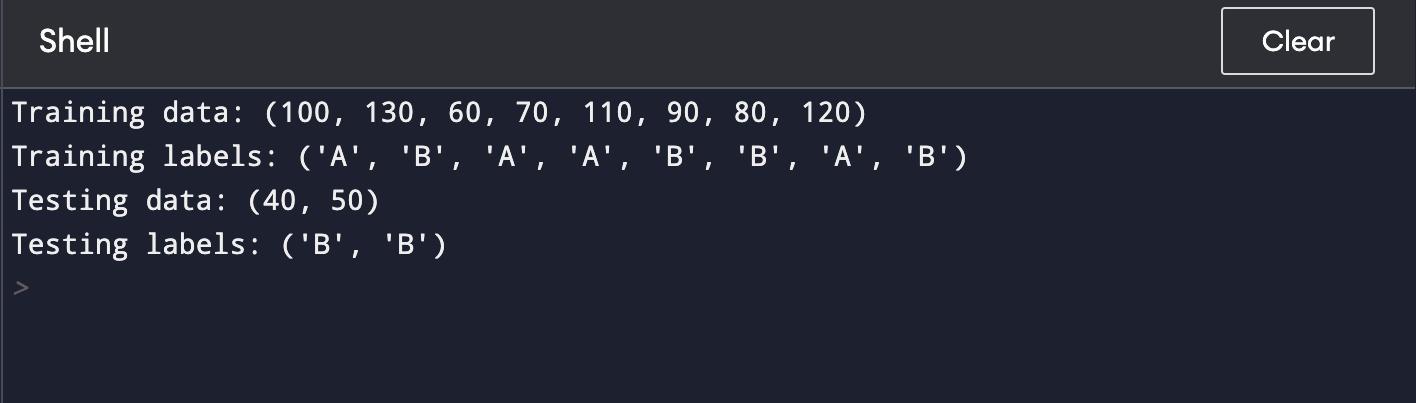
This code demonstrates the random splitting technique for dividing a dataset into training and testing sets. Here’s the breakdown of steps:
1. Import the random module to access randomisation functions.
2. Define an example dataset (data) and corresponding labels (labels).
3. Combine the data and labels into pairs using the zip() function and store them in the merge_sort list. This step associates each data point with its corresponding label.Randomly shuffle the pairs in the merge_sort list using the random.shuffle() function. This ensures that the data points and their labels are mixed up randomly.
4. Specify a division ratio (divide_ratio) that determines the proportion of data for training and testing. In this example, it's set to 0.8, indicating 80% for training and 20% for testing.
5. Calculate the split index by multiplying the length of the merged and shuffled data by the division ratio. This index will be used to separate the data into training and testing sets.
6. Use the calculated split_index to slice the merge_sort list. The first split_index pairs are used for training data and labels, and the rest are used for testing data and labels.
7. The zip() function is used again to unpack the training and testing pairs into separate lists: train_data, train_labels, test_data, and test_labels.
Finally, the code prints out the training and testing data and labels using the print statements.
Sequential Technique
Sequential data splitting involves organising your data in the order of time in which it was gathered or recorded. When working with time-dependent or historic data, such as historical stock prices, weather information, or text documents, this approach is especially helpful. Without copying content, the following is a more thorough explanation:
Consider keeping a journal in which you record your daily experiences. You keep a journal of your ideas and actions every day. Your diary eventually turns into a timeline of your life's events. Let's imagine you want to assess your ability to predict the future and how much you have learned from your journal entries. The sequential method helps you accomplish that. Now, let's say you want to see how much you've learned from your diary entries and how well you can predict future events. The sequential technique helps you do just that.
Recording Data
Every day, you record your experiences in your diary. This is your raw data, with each entry representing a snapshot of your life on that day.
Sorting by Time
To use the sequential technique, you organise your diary entries in the order they were written. The earliest entries come first, followed by the later ones.
Splitting the Diary
Now, you decide to use part of your diary to learn and another part to test your learning. You start from the earliest entries and set aside the earlier ones (train) to learn from.
Learning from the Past
You go through the entries you've set aside for training. This is like studying your past experiences to understand patterns, trends, and lessons from your journey so far.
Predicting the Future
Once you've learned from your past experiences, you take the entries that come after the training set (test). You use what you've learned to predict events, feelings, or activities in these entries.
Implementation
Let's discuss the implementation of the same.
Code
Python
Python
# Replace the sample sequential data with your own data.
The time_points list represents time instances, and the values list represents values associated with those time points. This could be any time-dependent data, like temperature readings over days, stock prices over time, etc.
Split Point
The split_point determines where to split the data into training and testing sets. In this example, it's set to 7, meaning the first 7 time points will be used for training, and the remaining time points will be used for testing.
Splitting Data
The data is split into two parts based on the split_point. train_time and train_values contain the time points and values for training, while test_time and test_values contain the time points and values for testing.
Printed Results
The code then prints the time points and values for both the training and testing sets.
Stratified Splits
Stratified splits are like sharing candies fairly. If you have different types of candies (classes), you want to make sure each group of friends (train and test) gets the same mix of candies. This way, you can check if your friends' reactions to candies match those of the whole group. It's about being fair and getting a reliable idea of how well something works for everyone.
Step 1: Install scikit-learn
Open your terminal or command prompt and execute the following command to
Install scikit-learn:
Python
Python
pip install scikit-learn
You can also try this code with Online Python Compiler
After successfully installing scikit-learn, you can use the code example provided earlier for stratified splits:
Code
Python
Python
from sklearn.model_selection import train_test_split from sklearn.datasets import load_iris
# Load the Iris dataset as an example (replace with your data) iris = load_iris() data = iris.data target = iris.target
# Split the data fairly, with similar class distribution train_data, test_data, train_target, test_target = train_test_split( data, target, test_size=0.2, random_state=42, stratify=target )
# Display the results print("Training data shape:", train_data.shape) print("Testing data shape:", test_data.shape)
You can also try this code with Online Python Compiler
This code will perform a stratified split of the Iris dataset, ensuring that the class distribution is maintained in both the training and testing sets. Make sure you have successfully installed scikit-learn using the pip install scikit-learn command before running the code.
Handling Imbalanced Datasets
Handling imbalanced datasets is like making sure everyone has a fair chance to play. Imagine you have a game with different teams, but one team has many more players than the others. This isn't fair because the larger team might dominate the game. Similarly, in machine learning, if you have more examples of one class than others, your model might become biased and perform poorly in the smaller classes.
To fix this, you balance the teams by giving everyone an equal opportunity. In machine learning terms, you balance the classes by either getting more data for the smaller class (collecting more players for the smaller team) or by creating artificial examples for the smaller class (borrowing some players from the larger team). This way, your model can learn from each class equally and make fair predictions. It's like ensuring that each team has a fair chance to win the game.
Real-Life Example
Imagine you're organising a game of tag, and you have different teams. But, you notice that one team has a lot more players than the others. This might make the game unfair because the larger team could easily win just due to its numbers. In machine learning, a similar issue arises when you have a dataset where one class has many more examples than the others. This is called an imbalanced dataset.
Now, let's talk about how to handle this situation:
Collect More Players
To balance the game, you might gather more players for the smaller teams. In machine learning, this means getting more data for the underrepresented class. You collect more examples so that each team (class) has a similar number of players (examples) to play the game (train the model).
Artificially Create Players
Sometimes, it's not easy to find more players for a smaller team. In machine learning, you can create new examples for the underrepresented class using techniques like duplication or generating similar examples. It's like creating virtual players to even the teams.
Give Everyone a Chance
With balanced teams, the game becomes fair. In machine learning, when you balance the classes, your model can learn from each class equally. It won't be biased towards the larger class, and it can make better predictions for all classes, not just the majority.
Data Leakage and Ratio Errors
Data Leakage
Data leakage is like giving away answers before the test. Imagine you're practising a game, and someone tells you the answers in advance. When you play the real game, you might seem very good, but you're actually cheating. In machine learning, data leakage happens when information from the future or the test set somehow sneaks into the training process. This can make your model appear accurate, but it's just memorising the answers, not really learning how to solve problems on its own.
In machine learning, data leakage occurs when your model learns from information that it shouldn't have access to during training. This might make your model seem very accurate, but it's not truly learning the patterns in the data. Just like you're not really learning if you're just copying answers from your friend. To build a reliable model, you need to make sure it learns from the right information and doesn't cheat by peeking into the future or using the information it shouldn't have.
To prevent this, you need to make sure your model only learns from past information during training.
Ratio Errors
Ratio errors are like misunderstanding proportions in a group. Let's say you have a bag of candies with different colours, and you think there are more red candies than there actually are. You might make decisions based on this wrong belief. In machine learning, ratio errors occur when you misjudge the proportions of different classes in your dataset. This can lead to biased predictions, as your model might think one class is more important than it actually is. In machine learning, ratio errors happen when you misjudge the proportions of different things in your data. For instance, if you have more data points for one type of flower compared to another type, your model might think that the first type is more important or occurs more frequently. Just like with the cakes, your model might give more attention to one class, even if it's actually balanced.
To avoid this, it's important to make sure your model accurately understands the true distribution of things in your data, just like you would want to know the real amount of cake at the party to make sure everyone gets a fair share.
To avoid this, you need to ensure your training data accurately represents the real distribution of classes.
Both data leakage and ratio errors can mislead your model's performance and predictions. Being aware of them and taking steps to prevent them helps ensure your model learns and makes decisions accurately.
Evaluating Split Performance
Evaluating split performance is like checking if a cake was sliced properly. Imagine you're cutting a cake to share with friends. You want each slice to be of the same size and have a fair mix of cake and frosting. To make sure the slices are good, you take a look at them after cutting.
In machine learning, when you split your data into training and testing sets, you're essentially slicing your dataset. Just like with the cake, you want to ensure that both your training and testing sets are balanced and representative of the whole dataset. By evaluating the split performance, you're checking if your data is divided in a way that your model can learn well and perform accurately on new, unseen examples.
You do this by using various metrics and techniques to measure how well your model is learning from the training data and how effectively it's making predictions on the testing data. It's similar to examining cake slices to make sure they're all fair and delicious. If your split is good, your model will be well-prepared for real-world challenges, just like well-cut cake slices are ready to be enjoyed by everyone.
Metrics for Evaluation
Imagine you're baking cookies, and you want to know how good they turned out. You taste them, check their texture, and ask others for their opinions. These are all ways to measure how well your cookies are doing.
In machine learning, we also measure how well our models are doing using metrics. Instead of taste and texture, we use numbers to understand performance.
Here are a few "taste-test" metrics:
Accuracy
This is like counting how many cookies turned out exactly how you wanted. It measures how often your model's predictions are correct.
Precision
Precision is like making sure you only say a cookie is delicious when you're really sure. It checks how accurate your positive predictions are.
Recall
The recall is like not missing out on any yummy cookies. It looks at how well your model finds all the positive cases.
F1-Score
F1-Score is like finding a balance between precision and recall. It's useful when you want a mix of both accurate positive predictions and finding all positive cases.
Just like your taste test helps you understand how to improve your cookies, these metrics guide you in making your model better by showing you where it's doing well and where it needs a little more work.
Comparing Different Splits
Split Technique
Description
Use Cases
Advantages
Disadvantages
Random Split
Randomly divides data into train and test sets
General datasets
Quick and simple
May lead to unbalanced splits
Sequential Split
Uses data in chronological order for split
Time-dependent data; sequences
Reflect temporal patterns
Limited to time-dependent scenarios
Stratified Split
Maintains class distribution in train and test sets
Imbalanced datasets, classification tasks
Reduces bias, better model performance
Complexity with multi-class data
Frequently Asked Questions
Why do we split data for machine learning?
Data splitting helps us evaluate how well our model will perform on new, unseen data. It ensures our model doesn't memorise but learns to generalise.
What's the purpose of cross-validation?
Cross-validation assesses how well a model can handle different data samples. It reduces the risk of getting overly optimistic or pessimistic results from a single split.
How can imbalanced data impact model performance?
Imbalanced data can make models biased toward the majority class, leading to poor performance on minority classes. This happens because the model's learning gets skewed towards the prevalent class.
Conclusion
Splitting a Torch dataset is like dividing a big chocolate bar to share with friends. It's essential to make sure everyone gets a fair piece. When working with Torch, you're dealing with data for training and testing a machine-learning model. Splitting the Torch dataset helps ensure that your model learns well and performs accurately on new data. By carefully dividing your dataset into training and testing portions, you're setting up your model for success. It's like giving each friend a proper share of the chocolate bar so that everyone can enjoy it. This practice helps your model learn without cheating and makes sure it's ready to face real-world challenges with confidence.
But suppose you have just started your learning process and are looking for questions from tech giants like Amazon, Microsoft, Uber, etc. For placement preparations, you must look at the problems, interview experiences, and interview bundles.

































 18+ registered
18+ registered 

