Do you think IIT Guwahati certified course can help you in your career?
Introduction
Huffman coding is a data compression technique that encodes fixed-length data objects into variable-length codes. This method, known as the Huffman coding algorithm, aims to create the most efficient code for a block of data, minimizing the need for padding or zeroes. It achieves code rates similar to Rabin decoding, making it useful as an entropy decoder as well. Developed by Donald E. Huffman in 1952, this blog post will explore:
What Huffman coding is
Why it is used
How it works
Examples of applications that use Huffman encoding
What is the Huffman coding algorithm?
The Huffman coding algorithm is a method used for data compression. It creates a variable-length code for each data element based on its frequency of occurrence. The most frequent elements get shorter codes, while less frequent elements get longer codes. This approach minimizes the total number of bits required to encode the data, making it more efficient.
Here’s a step-by-step explanation of how the Huffman coding algorithm works:
Frequency Calculation: First, the algorithm calculates the frequency of each data element in the dataset. This could be characters in a text file or pixels in an image.
Building the Huffman Tree: The algorithm then creates a binary tree called the Huffman tree. It starts by creating a leaf node for each unique element and its frequency. The nodes are then combined into a tree where each internal node represents the sum of the frequencies of its child nodes.
Assigning Codes: Once the tree is built, the algorithm assigns binary codes to each data element. The path from the root to a leaf node determines the code, with left branches usually representing 0 and right branches representing 1. The result is that frequent elements have shorter codes and infrequent elements have longer codes.
Encoding Data: Finally, the algorithm uses these codes to encode the original data. Each element in the dataset is replaced by its corresponding Huffman code.
Decoding Data: To decode, the encoded data is read and the Huffman tree is used to map the binary codes back to the original elements.
This method of encoding is effective because it reduces the average length of codes compared to fixed-length encoding, leading to compression of the data. Huffman coding is widely used in various applications, including file compression formats and data transmission protocols.
Key Features of Huffman Coding
Lossless Compression – Huffman coding keeps the original data intact, ensuring nothing is lost during compression or decompression.
Variable-Length Encoding – It gives shorter codes to frequent characters and longer ones to less frequent characters, reducing overall size.
Prefix Property – No code is a prefix of another, which helps in error-free decoding of the compressed data.
Based on Frequency Analysis – The algorithm uses character frequency to decide the code lengths, making it more efficient.
Binary Tree Structure – It builds a binary tree using input character frequencies to generate the most efficient codes.
Prefix Rule
The prefix rule, also known as the prefix property, is an important concept in Huffman coding and other encoding schemes. It ensures that no code assigned to a symbol is a prefix of any other code. This property is crucial for the following reasons:
Unique Decoding: By ensuring that no code is a prefix of another, the prefix rule guarantees that the encoded data can be uniquely and unambiguously decoded. This means that each code can be identified and decoded without confusion, ensuring that the original data is accurately reconstructed.
Efficient Decoding: The prefix property allows for a straightforward decoding process. As soon as the decoder reads a complete code from the encoded stream, it can directly translate it to the corresponding symbol. This avoids the need for complex backtracking or buffering during decoding.
Avoiding Ambiguity: Without the prefix rule, different codes could overlap, making it impossible to determine where one code ends and another begins. This would lead to ambiguity and errors in decoding.
In short, the prefix rule is fundamental to Huffman coding and other variable-length coding schemes. It ensures that each code is distinct and non-overlapping, which is essential for accurate and efficient data decoding.
Example
INPUT:
charList[] = { 'c', 'o', 'd', 'i', 'n', 'g' }
charFreq[] = { 7, 11, 13, 17, 19, 23 }
OUTPUT:
Character Code
c 000
o 001
n 01
g 10
d 110
i 111
We get a set of characters and their frequencies as input. We are supposed to encode the characters and return the unique codes for each character.
Huffman Coding Algorithm
The Huffman coding algorithm is a method used to compress data by assigning variable-length codes to different data elements based on their frequency of occurrence. Here’s a detailed explanation of how the algorithm works:
Calculate Frequencies:
Start by analyzing the dataset to determine the frequency of each unique element. For example, if encoding a text, count how often each character appears.
Create Leaf Nodes:
Create a leaf node for each unique element, where each node contains the element and its frequency.
Build the Huffman Tree:
Insert all leaf nodes into a priority queue or min-heap, where nodes with lower frequencies have higher priority.
Repeatedly extract the two nodes with the lowest frequencies from the queue. Create a new internal node with these two nodes as its children. The frequency of the new internal node is the sum of the frequencies of its two child nodes.
Insert the new internal node back into the queue.
Continue this process until only one node remains in the queue. This node becomes the root of the Huffman tree.
Generate Codes:
Traverse the Huffman tree to generate codes for each element. Assign binary codes by traversing from the root to each leaf node. Move left for a '0' and right for a '1'. The code for each element is the sequence of bits read along the path from the root to the leaf node.
Encode Data:
Use the generated Huffman codes to encode the original data. Replace each element in the data with its corresponding Huffman code.
Decode Data:
To decode, use the Huffman tree to map the encoded data back to the original elements. Start at the root of the tree and follow the path according to the bits in the encoded data, moving left for '0' and right for '1', until reaching a leaf node. Each leaf node represents the original element.
The Huffman coding algorithm is efficient because it produces a compression that reduces the average code length compared to fixed-length encoding. It’s widely used in file compression formats, data transmission, and other applications where reducing data size is important.
Steps to Build a Huffman Tree
The Huffman encoding algorithm is a powerful method for compressing data based on character frequencies in a message. It works by encoding more frequent characters with shorter bit strings and less frequent characters with longer bit strings. Because different messages have different character frequencies, Huffman encoding can vary between messages.
Here’s how to implement the algorithm:
Maintain a MinHeap: Use a priority queue to create a MinHeap. Each node in the heap represents a character and its frequency.
Build the MinHeap:
Start by adding all characters and their frequencies to the heap.
Extract the two nodes with the lowest frequencies from the MinHeap.
Create a new internal node with a frequency equal to the sum of the two extracted nodes' frequencies.
Insert the new internal node back into the MinHeap.
Repeat this process until only one node remains. This node becomes the root of the Huffman tree.
Generate Codes:
Traverse the Huffman tree to generate codes. Assign '0' when moving to the left child and '1' when moving to the right child.
To illustrate this process, let’s discuss an example.
We input the characters {c,o,d,i,n,g} with frequencies {7,11,13,17,19,23}. Our heap will look like this:
Nodes
Frequency
c
7
o
11
d
13
i
17
n
19
g
23
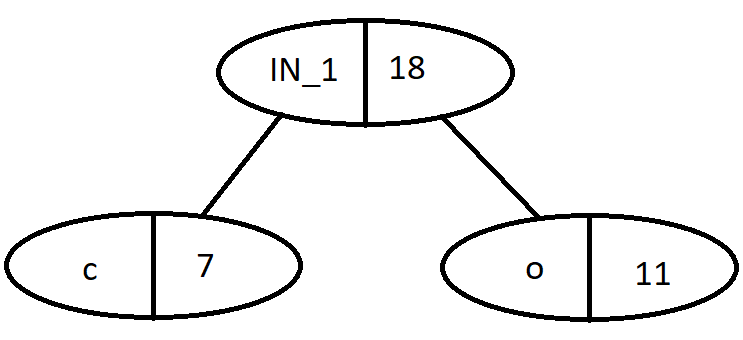
We pick the two characters with the smallest frequency. They are ‘c’ and ‘o’ with frequencies 7 and 11. We create an internal node (IN) to store their sum and create a tree. It will look like this:
Our table is updated to:
Nodes
Frequency
d
13
i
17
Internal Node (IN_1)
18
n
19
g
23
The next set of iterations and the gradual tree formation is shown below:
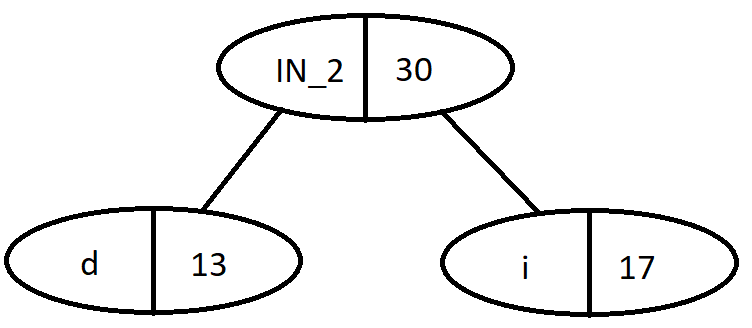
Iteration 2: choose from the heap d, i
Nodes
Frequency
Internal Node (IN_1)
18
n
19
g
23
Internal Node (IN_2)
30
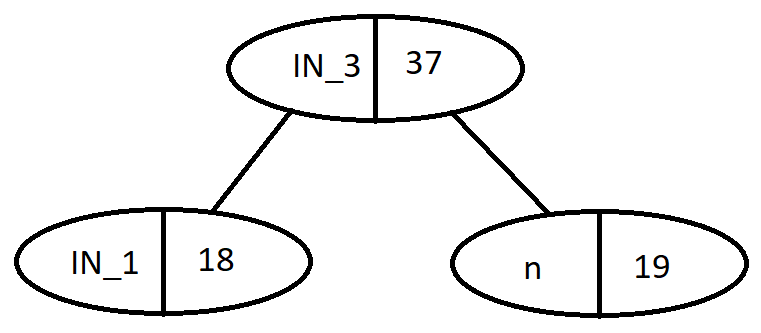
Iteration 3: choose from the heap IN_1 and n
Nodes
Frequency
g
23
Internal Node (IN_2)
30
Internal Node (IN_3)
37
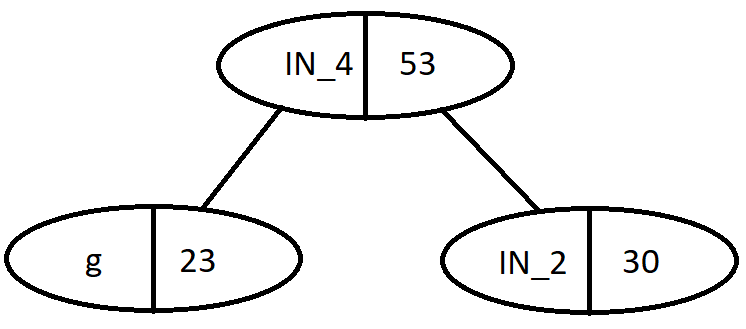
Iteration 4: choose from the heap: g and IN_2
Nodes
Frequency
Internal Node (IN_3)
37
Internal Node (IN_4)
53
Iteration 5: choose from the heap: IN_3 and IN_4
Nodes
Frequency
Internal Node (IN_5)
90
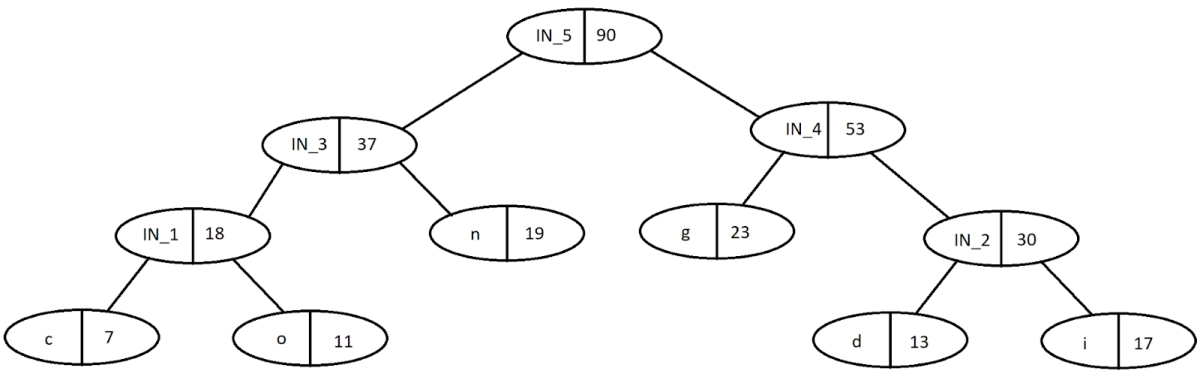
Final tree after all the calculations:
Now for the traversal, follow the given rule, that is 0 = left-child, 1 = right-child. On doing so, we get the tree below:
From this tree, we get the required codes for each character. To get the codes, we simply travel to the character from the root and store the incoming 0s and 1s. The characters and their codes are:
Characters
Codes
c
000
o
001
n
01
g
10
d
110
i
111
Hopefully, after seeing the explanation of the example, you will be able to formulate a logic and implement it first.
Recommended: First, try to solve the Huffman encoding algorithm on your own. You can go to this link Huffman Coding to try it on our Coding Ninjas Studio.
In the given implementation, we extract the minimum node from the heap in (log n) time, and we do this for all the n nodes. Thus, the time complexity is,
T(n) = O(n log n),
where n is the number of nodes.
Space Complexity
In the given implementation, we have n symbols to encode and store. Thus,
Space complexity = O(n),
where n is the number of nodes.
Problems with Huffman Coding
Inefficiency with Small Datasets: Huffman coding is less effective for very small datasets or those with limited character diversity. In such cases, the overhead of encoding and decoding may outweigh the benefits of compression.
Complexity in Dynamic Data: When dealing with data that changes frequently or has varying frequencies, updating the Huffman tree can become complex. Dynamic Huffman coding can mitigate this but adds its own complexity.
Non-Optimal for Certain Data: Huffman coding may not perform well with data that has very uniform frequency distribution. It tends to be most effective when there are significant differences in character frequencies.
Header Overhead: Huffman encoding requires the transmission or storage of the Huffman tree or its equivalent. This overhead can be significant, especially for small files, reducing the overall efficiency of compression.
Loss of Data Integrity: If the encoded data is corrupted, the entire decoding process can fail, leading to potential data loss or misinterpretation.
Uses of Huffman Coding
File Compression: Huffman coding is commonly used in file compression formats such as ZIP and GZIP. It reduces the size of files by encoding frequently occurring data with shorter codes and less frequent data with longer codes.
Image Compression: In image formats like JPEG, Huffman coding helps compress image data by reducing redundancy. It works alongside other techniques like Discrete Cosine Transform (DCT) to achieve high compression ratios.
Text Compression: Huffman coding is used in text compression algorithms to minimize the size of text files by replacing common characters or sequences with shorter binary codes.
Communication Protocols: In various communication protocols, Huffman coding reduces the amount of data that needs to be transmitted. It helps in efficient bandwidth usage by compressing data streams.
Data Storage: Huffman coding is used in data storage systems to compress data files, which saves disk space and improves data retrieval speeds. This is particularly useful in databases and large-scale storage solutions.
Advantages and Disadvantages of Huffman Coding
Advantages of Huffman Coding
Efficient Lossless Compression: Huffman coding compresses data without losing any original information, making it ideal for text and file storage.
Reduces Average Code Length Based on Frequency: It assigns shorter codes to more frequent characters and longer codes to less common ones, which helps reduce the overall size.
Supports Variable-Length Encoding: It uses variable-length binary codes, making the compression flexible and efficient.
Used in Real-World Applications: Huffman coding is widely used in ZIP files, JPEG images, and MP3 audio formats for space-saving compression.
Disadvantages of Huffman Coding
Not Ideal for Small Datasets: Huffman coding works best with large files. It may not show much benefit when used on small datasets.
Needs Frequency Distribution: Before encoding, it must know how often each character appears, which adds extra steps.
Encoding/Decoding Can Be Slow for Large Files: For big files, building the tree and processing the data can be time-consuming and resource-intensive.
Frequently Asked Questions
What are Huffman coding symbols?
Huffman coding symbols are the characters or bits used to represent data in a compressed format, based on their frequency of occurrence.
Is Huffman coding a Greedy algorithm?
Yes, Huffman coding is a Greedy algorithm because it builds the optimal code by always choosing the least frequent characters first.
What is Huffman coding fixed length?
Fixed-length Huffman coding uses the same number of bits for each symbol, unlike variable-length Huffman coding which uses different bit lengths based on symbol frequency.
What are the two types of Huffman coding?
The two types of Huffman coding are static Huffman coding, which uses a fixed coding tree, and dynamic Huffman coding, which adjusts the tree as data is processed.
Conclusion
To summarize the article, we have thoroughly discussed the Huffman encoding algorithm. We first saw the general idea of the algorithm, followed by an example, then the approach to take and the explanation of the example. We also saw the C++ implementation, its time and space complexity. In the end, we summed it up with a few FAQs.
Live masterclass
Build GenAI Projects that can get you Amazon interview
by Anubhav Sinha
23 Jul, 2026
11:30 AM
Get shortlisted for Amazon data interview: SQL+Python Prep
by Abhishek Soni
20 Jul, 2026
11:30 AM
Top 5 GenAI Projects to Crack 25 LPA+ Roles in 2026
by Shantanu Shubham
21 Jul, 2026
12:30 PM
Interview-Ready Excel & AI Skills for Amazon Analyst Roles
by Prerita Agarwal
22 Jul, 2026
12:30 PM
Build GenAI Projects that can get you Amazon interview
by Anubhav Sinha
23 Jul, 2026
11:30 AM
Get shortlisted for Amazon data interview: SQL+Python Prep

































 6+ registered
6+ registered 

