How deep learning creates high-resolution images?
A degradation function can model a low-resolution image from a high-resolution image. This can be understood from the below equation:
Ix = D( Iy; σ)
Where Ix is the low-resolution image, Iy is the high-resolution image, and D and σ are the degradation parameters. D and σ are unknown and are taken randomly at first. Deep learning models predict the value of D and σ and find the inverse of the degradation function. The prediction is made by using the data provided in the form of high-resolution and low-resolution images.
Let us look at some of the techniques used to perform this task.
Image Super-Resolution frameworks
Pre-upsampling Super-resolution
Upsampling simply means increasing the resolution of an image. In the pre-upsampling super-resolution, we use traditional techniques like bipolar interpolation to upscale an image and then use deep learning to refine the upscaled image. Let us talk about some of the
SRCNN
Super Resolution Convolution Neural Network (SRCNN) is one of the first methods to use deep learning for image super-resolution. SRCNN is a convolutional neural network. It contains three layers.
Feature extraction layer: It extracts the features from the input and uses different convolutional filters to represent them.
Non-linear mapping: It is used to change the number of channels of the image to perform further processing of the image. It contains 1X1 convolutional filters.
Reconstruction layer: It is the final layer of SRCNN and is used to construct the high-resolution image.

SRCNN
VDSR
VDSR stands for Very deep super-resolution. It is based on VGG architecture and uses many small 3X3 filters. It is an improved version of SRCNN.
Instead of learning the direct mapping from the input image like SRCNN, VDSR is used to get the residuals of the image, and then the initial input image is added to get the high-resolution output.
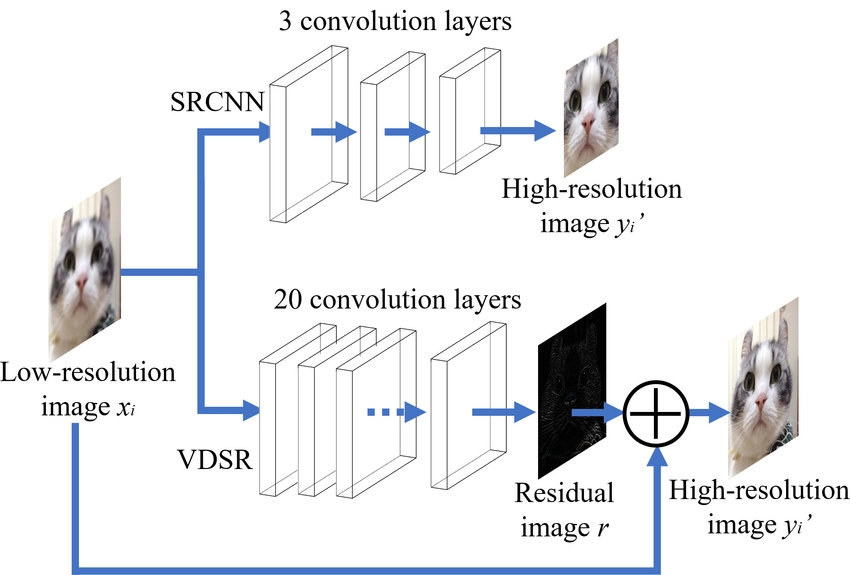
SRCNN vs VDSR
Post-upsampling Super-resolution
In pre-upsampling super-resolution, feature extraction is done after upsampling of the image. This requires a lot of computational power. To mitigate this problem, we use post-upsampling Super-resolution. In this, the feature extraction is done before upscaling the image. This helps us to cut down the computational cost significantly. Upscaling is done using complex methods such as sub-pixel convolution. This helps to create an end-to-end trainable model.
FSRCNN
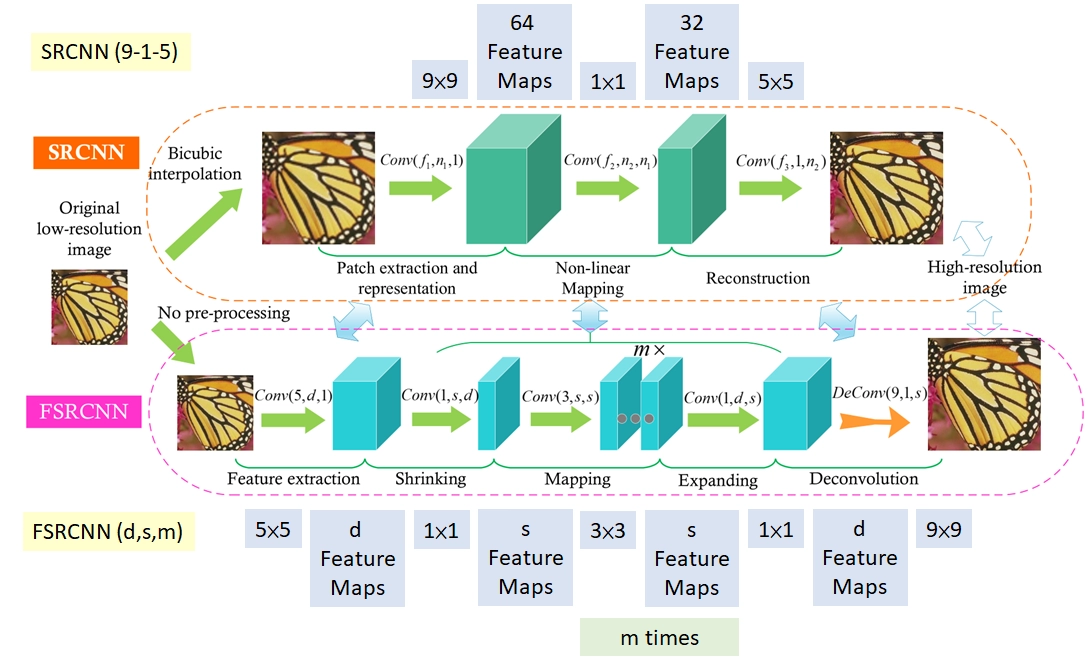
FSRCNN VS SRCNN
FSRCNN stands for Fast Super-Resolution Convolutional Neural Network. The feature extraction is done before the upsampling of the image. It uses 5X5 convolutional filters for feature extraction and the 1X1 filters to reduce the size. Multiple 3X3 filters are used for mapping.
The upsampling is done using deconvolution. This improves the model. FSRCNN is faster and more accurate than SRCNN.
ESPCN
Efficient Sub-Pixel Convolutional Neural Network (ESPCN). It uses sub-pixel convolution for upsampling. ESPCN converts different channels of a low-resolution image to form a single channeled high-resolution image.
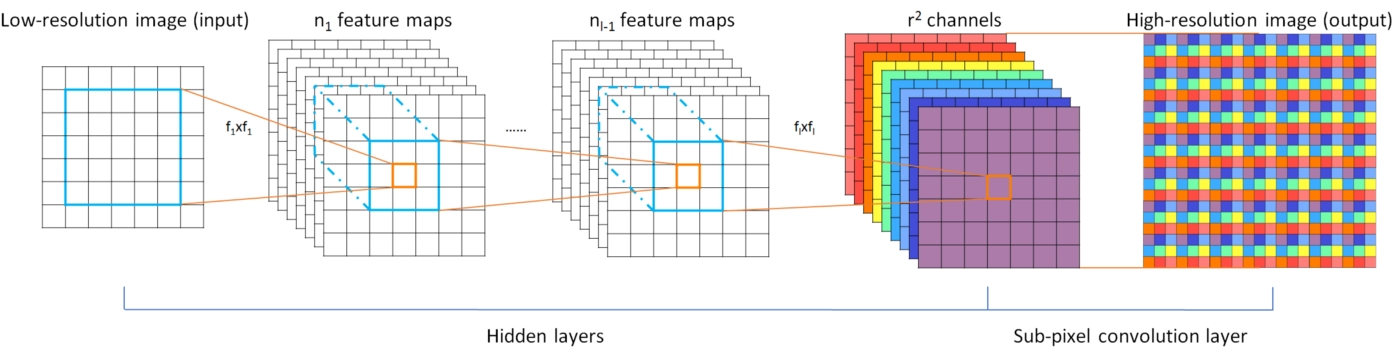
ESPCN network architecture
Residual networks
Residual networks are also used to perform image super-resolution.
EDSR stands for Enhanced Deep Residual Networks. It contains multiple residual blocks and its architecture is based on SRResNET. To create EDSR, batch normalization layers are removed from SRResNet.
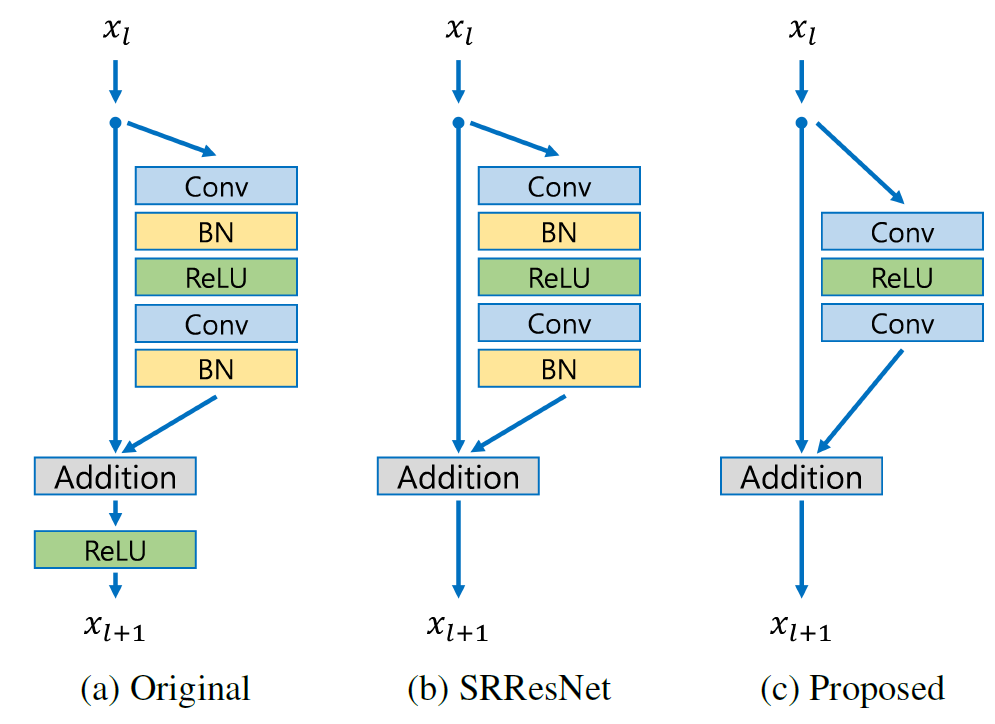
source
Implementation of Image Super-Resolution
Let us try to implement image super-resolution using OpenCV. We will use FSRCNN to generate a high-resolution image from a low-resolution image.
Importing the libraries
import cv2
import matplotlib.pyplot as plt

You can also try this code with Online Python Compiler
Reading the image
img = cv2.imread("path/to/image.png")
You can also try this code with Online Python Compiler
Using FSRCNN
sr = cv2.dnn_superres.DnnSuperResImpl_create()
path = "FSRCNN_x3.pb"
sr.readModel(path)
sr.setModel("fsrcnn",3)
result = sr.upsample(img)
You can also try this code with Online Python Compiler
FSRCNN will increase the resolution of the image. The desired output will be like this:
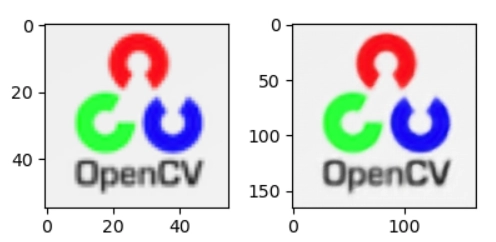
Applications of image super-resolution
- It is widely used in the medical field.
- Used in remote sensing by enhancing the picture quality.
- Increase the quality of the images taken from surveillance.
- Astronomical imaging - the images taken from telescopes are enhanced using super-resolution.
-
Improving facial recognition accuracy.
Also read, Sampling and Quantization
Frequently Asked Questions
Are there more methods to perform image super-resolution?
Yes, there are many other methods such as Super-Resolution Generative Adversarial Network (SRGAN), MDSR, CARN, etc.
What is the most widely used image super-resolution method?
SRCNN is considered the most widely used super-resolution method.
Can we implement image super-resolution methods by using other libraries?
Yes, we can also use other libraries such as TensorFlow for implementing image super-resolution methods.
Conclusion
This article talked about image super-resolution and the basic idea of achieving it by using deep learning. We also learned about some of the deep learning methods for super-resolution. We talked about its application and implemented FSRCNN by using OpenCV. But the learning should not stop here. There are more methods of image super-resolution.
Refer to our Guided Path on Coding Ninjas Studio to upskill yourself in Data Structures and Algorithms, Competitive Programming, JavaScript, System Design, Machine learning, and many more! If you want to test your competency in coding, you may check out the mock test series and participate in the contests hosted on Coding Ninjas Studio! But if you have just started your learning process and are looking for questions asked by tech giants like Amazon, Microsoft, Uber, etc., you must look at the problems, interview experiences, and interview bundle for placement preparations.
Nevertheless, you may consider our paid courses to give your career an edge over others!
Do upvote our blogs if you find them helpful and engaging!
Happy Learning!!





























 8+ registered
8+ registered 

