Types of virtualization and its impact on big data
In this section, we will talk about different types of virtualization and how it impacts big data.
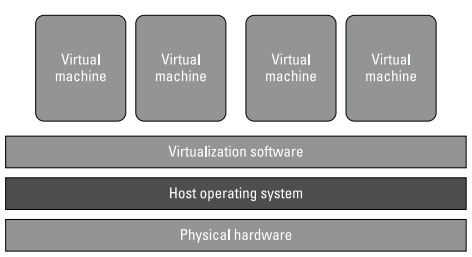
Server virtualization
One physical server is partitioned into many virtual servers in server virtualization. A machine's hardware and resources, including random access memory (RAM), CPU, hard drive, and network controller, can be virtualized (logically split) into several virtual machines, each running its applications and operating system.
The hypervisor is used in server virtualization to use physical resources efficiently. Of course, installing, configuring, and administering these virtual computers is a part of the process. This comprises license management, network management, workload management, and capacity planning.
Server virtualization ensures that our platform can scale as needed to manage the massive volumes and diverse data types in our big data study. Before we begin our analysis, we may not know the number or diversity of structured and unstructured data required. This uncertainty increases the requirement for server virtualization, which provides our system with the potential to meet unexpected demands for processing very big data sets.
Furthermore, server virtualization lays the groundwork for many cloud services used as data sources in big data analysis. Virtualization improves the efficiency of the cloud, making it easier to optimize many complicated systems. Big data platforms are rapidly being utilized to collect massive data about client preferences, sentiments, and activities. Companies can combine this data with internal sales and product data to better understand client preferences and provide more targeted and tailored offerings.
Application virtualization
Virtualizing application infrastructure is a cost-effective technique to manage applications in the context of consumer demand. The program is encased in such a way that it is no longer reliant on the physical computer system. This helps to improve the application's general management and mobility.
Furthermore, application infrastructure virtualization software often allows us to codify business and technical usage norms to ensure that our applications use virtual and physical resources consistently. Because we can more readily divide IT resources according to the proportional business value of our apps, we achieve efficiencies.
In conjunction with server virtualization, application infrastructure virtualization can aid in the fulfillment of business service-level agreements. When allocating resources, server virtualization monitors CPU and memory utilization but does not account for fluctuations in business importance.
Network virtualization
Network virtualization makes it possible to efficiently use networking as a pool of connection resources. Rather than relying on the physical network to manage traffic, we can establish many virtual networks that use the exact physical implementation. This is handy if we need to define a network for data collection with a specific set of performance attributes and capacity and another network for applications with varying performance and capacity.
Virtualizing the network aids in the reduction of bottlenecks and improves the ability to manage massive amounts of distributed data required for big data analysis.
Data processor and memory virtualization
Processor virtualization aids in processor optimization and performance enhancement. Memory virtualization separates memory from servers.
Big data analysis may involve repetitive queries of enormous data sets and the development of powerful analytic algorithms, all to uncover previously unknown patterns and trends. These complex analytics may need significant computing power (CPU) and memory (RAM). Some of these computations can take along without appropriate CPU and memory resources.
Data and storage virtualization
The usage of data virtualization can be utilized to provide a platform for dynamically linked data services. This enables data to be readily searched and connected using a single reference source. As a result, data virtualization provides an abstract service that consistently serves data regardless of the underlying physical database. Furthermore, data virtualization makes cached data available to all apps, which improves performance.
Storage virtualization combines physical storage resources to share them more effectively. This lowers storage costs and makes it easier to maintain the data repositories needed for big data analysis.
Implementing Virtualization to Work with Big Data
In this section, we will talk about how virtualization is implemented on big data to make it work.
Virtualization assists in making our IT system intelligent enough to handle big data analysis. We obtain the efficiency required to analyze and manage huge volumes of structured and unstructured data by optimizing all parts of our infrastructure, including hardware, software, and storage. Big data necessitates the access, management, and analysis of organized and unstructured data in a dispersed setting.
Big data is predicated on distribution. In practice, any MapReduce algorithm will perform better in a virtualized environment. We must be able to transfer workloads around based on computational power and storage requirements.
Thanks to virtualization, We will be able to tackle larger challenges that have not yet been scoped. We may not know how quickly we will need to scale ahead of time.
The most obvious benefit of virtualization is that it improves the performance of MapReduce engines. MapReduce will benefit from increased scalability and performance as a result of virtualization. Each of the Map and Reduce activities must be completed independently. We can reduce management overhead and allow for task burden expansions and contractions if the MapReduce engine is parallelized and configured to execute in a virtual environment. MapReduce is designed to be parallel and distributed from the start. We can run what we need whenever we need it by encapsulating the MapReduce engine in a virtual container.
Want to know the Salary of a Big Data Engineer? Check out the blog Big Data Engineer Salary in Various Locations to learn more about it.
Frequently Asked Questions
-
What is Data Virtualization?
Data virtualization is a data management strategy that enables an application to retrieve and alter data without requiring technical information about the data, such as how it was formatted at the source or where it is physically located and can provide a single customer view of the whole data.
-
What are the benefits of big data virtualization?
Managers can identify required information faster, study vast amounts of data more effectively, explore and drill down data to acquire a more thorough picture of their assets, operations, environment, and so on by visualizing big data.
-
What are the levels for implementing virtualization for distributed computing?
The levels for implementing virtualization for distributed computing are as follows:
application virtualization, utility computing, grids, virtual servers, virtual machines, and storage grids and utilities.
-
How virtualization supports distributed computing
Virtualization in distributed computing provides an organization with flexibility, scalability, portability, and cost savings. The combination of virtualization and distributed computing has opened up a plethora of choices for large to small businesses by maximizing performance and efficiently utilizing resources, resulting in lower infrastructure costs.
Conclusion
In this article, we have extensively discussed the concepts of big data virtualization. We started by introducing big data virtualization, its importance, and its types and finally concluded with virtualization implementation on big data.
We hope that this blog has helped you enhance your knowledge regarding big data virtualization. You can also consider our Data Analytics Course to give your career an edge over others. Do upvote our blog to help other ninjas grow. Happy Coding!





























 9+ registered
9+ registered 

