Do you think IIT Guwahati certified course can help you in your career?
Introduction
Do you know what Spark ML is? Have you implemented any Models in Spark ML? If not, then don't worry; we got your back. In this article, we will look into Models in Spark ML. We will also see how to perform feature extraction using spark ML and implement classification, regression, and clustering models using Spark ML.
What is Spark ML?
Apache Spark ML is an open-source, cluster-computing framework that provides an ecosystem for Machine Learning and Analytics using the popular machine learning library MLlib.
MLlib library
MLlib library supports standard algorithms such as classification, regression, and Clustering. It can also be implemented for feature extraction, dimensionality reduction, and transformation.
Spark is an easy-to-use platform for data scientists and engineers that is much faster than its alternatives for high-volume and high-velocity data processing.
Now, let us understand some of the Feature Extractors in Spark ML.
Feature Extractors In Spark ML
Let's look at some feature extractors for extracting features from "raw" data.
TF-IDF
The first feature extractor is TF-IDF.Term Frequency-Inverse Document Frequency vectorization method for features is widely used for information mining. It shows the importance of a term in corpus. A corpus is a collection of data, but it is not referred to as a dataset itself.
In TF-IDF,
term is represented by t,
document by d
corpus by D.
Hence, the function Term Frequency as TF(t,d) shows the relation between the number of t terms present in document d. Similarly, the Document Frequency functionDF(t, D) represents the amount of Documents present in the corpus that contains the term t.
The information provided by a term is known as Inverse Documentary Frequency and it is calculated as:
Here, |D| is the total number of Documents that are present in the corpus.
To calculate the TFIDF we simply multiply the TF and IDF
TFIDF(t,d,D) = TF(t,d) . IDF(t,D)
Word2Vec
Word2Vec takes a sequence of words from documents and trains a model that works as an estimator. Every word is mapped to a unique fixed-size vector. Each record is transformed into a vector by taking the average of all words in the document; the vector obtained can now be used as features for calculating similarity in documents, predictions, etc.
The mathematical representation of the model is
CountVectorizer
The CountVectorizer aims to help convert a collection of text documents to vectors of token counts. Performing preprocessing tasks, it breaks down the sentence or paragraph into words. The NLP model is unable to understand the textual data, it works only for numerical values. Thus, vectorisation is required. CountVectorizer can be used as an estimator when a dictionary is unavailable. The model produces sparse representations of the documents over the vocabulary.
Classification using Spark ML
Generally, classification problems are the ones in which we must determine the class in which the particular point from the test dataset lies. It is applied when the output has finite and discrete values Example: Social media sentiment analysis has three potential outcomes, positive, negative, or neutral.
We can make various machine learning Classification models in Spark ML like Spark.ml to perform Logistic Regression, Decision Tree Classifier, Random forest Classifier, Gradient Boost Classifier, and other models.
Let's implement a binomial logistic regression classifier to better understand Classification Models in Spark ML.
We can use Spark on Jupyter notebook or google colab. Here we are using google colab for Spark ML.
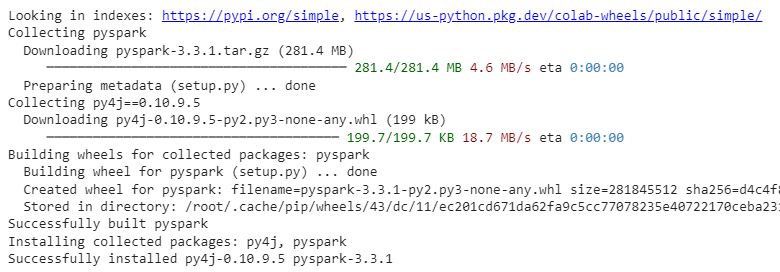
To use Spark on google colab, open a new notebook on colab and then write the below line of command install spark
!pip install pyspark
Now our google colab notebook is all set to use Spark for python.
To start, we will first build a new spark session.
! pip install pyspark # installing pyspark for Spark ML
from pyspark.sql import SparkSession # starting the spark Session for loading data into dataframes
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('logistic regression').getOrCreate()
The above code is used to install Spark and the output would look like:
Now we will get the sample data to perform logistic regression from the datasetand download the .txt file.
Now we will load the data to this session of Spark.
We are ready to implement logistic regression
# Loading the training data
df = spark.read.format("libsvm").load("/content/sample_libsvm_data.txt")
from pyspark.ml.classification import LogisticRegression
logreg= LogisticRegression(maxIter=10, regParam=0.3, elasticNetParam=0.8)
# Fitting the data in the logistic regression model
Model = logreg.fit(df)
# Print the coefficients and intercept for logistic regression
print("Coefficients: " + str(Model.coefficients))
print("Intercept: " + str(Model.intercept))
The above code will represent the following output:
Regression using spark ML
As you might know, regression problems are the ones that try to answer the question of "How Much?"—applied when the output is a serial number. A simple regression algorithm:
y = wx + b
In Spark ML, we can make various kinds of machine learning Regression models using spark.ml like linear regression, generalised regression, Decision tree regression, random forest regression, gradient boost regression, etc.
Let's implement a linear regression model to understand regression models in Spark ML better.
To start, we will first build a new spark session.
! pip install pyspark # installing pyspark for Spark ML
from pyspark.sql import SparkSession # starting the spark Session for loading data into dataframes
spark = SparkSession \
.builder \
.appName('Linear regression') \
.getOrCreate()
Now we will get the sample data to perform logistic regression on from the dataset, right-click, and save it as a .txt file.
Now we will load the data to this session of Spark.
We are ready to implement linear regression.
# Load training data
training = spark.read.format("libsvm")\
.load("/content/sample_linear_regression_data.txt")
from pyspark.ml.regression import LinearRegression
lr = LinearRegression(maxIter=10, regParam=0.3, elasticNetParam=0.8)
# Fit the model
lrModel = lr.fit(training)
# Print the coefficients and intercept for linear regression
print("Coefficients: %s" % str(lrModel.coefficients))
print("Intercept: %s" % str(lrModel.intercept))
# Summarizing the model over the training set and printing out some metrics
trainingSummary = lrModel.summary
print("numIterations: %d" % trainingSummary.totalIterations)
print("objectiveHistory: %s" % str(trainingSummary.objectiveHistory))
trainingSummary.residuals.show()
print("RMSE: %f" % trainingSummary.rootMeanSquaredError)
print("r2: %f" % trainingSummary.r2)
The output of the above code is:
Clustering Models In Spark ML
An ML technique that involves the grouping of data points is called Clustering.
Various clustering techniques are available to us in spark ML, such as K-means clustering, Bisecting K-means, Gaussian mixture model, and Power iteration clustering.
Let's implement a K-means clustering model to understand clustering models in spark ML better.
To start, we will first build a new spark session.
!pip install pyspark # installing pyspark for Spark ML
from pyspark.sql import SparkSession # starting the spark Session for loading data into dataframes
spark = SparkSession.builder.appName('kmeans').getOrCreate()
Now we will get the sample data to perform logistic regression on fromthe dataset,right-click, and save as a .txt file.
Now we will load the data to this session of Spark.
We are ready to implement the K-means Clustering
# Loading the data in dataframe.
df = spark.read.format("libsvm").load("/content/sample_kmeans_data.txt")
from pyspark.ml.clustering import KMeans
from pyspark.ml.evaluation import ClusteringEvaluator
# Train a k-means model.
kmeans = KMeans().setK(2).setSeed(1)
model = kmeans.fit(df)
# Make predictions
predict = model.transform(df)
# Evaluating kmeans clustering by calculating Silhouette score
eval = ClusteringEvaluator()
silhouette = eval.evaluate(predict)
print("Silhouette with squared euclidean distance = " + str(silhouette))
# Shows the result.
centers = model.clusterCenters()
print("Cluster Centers: ")
for center in centers:
print(center)
The above code will give the following output:
Frequently Asked Questions
What is unsupervised learning?
When we train a Machine learning model with a dataset that does not contain any labelled or classified data, that type of learning is known as Unsupervised learning.
What is supervised learning?
When a model is trained using an input-output pair, that learning process is Supervised learning. It infers a process from labelled training data consisting of training examples.
What is PySpark?
It is an interface for Apache Spark in Python. Using PySpark, we can write Python-like commands to analyse data in a distributed processing environment.
Conclusion
In this article, we got a brief introduction to Spark ML. We looked into different feature extractors in Spark ML. We also saw how to use Spark ML for Classification, Regression, and Clustering models.





























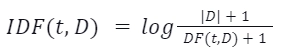

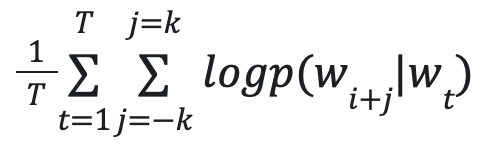




 9+ registered
9+ registered 

