Do you think IIT Guwahati certified course can help you in your career?
Introduction
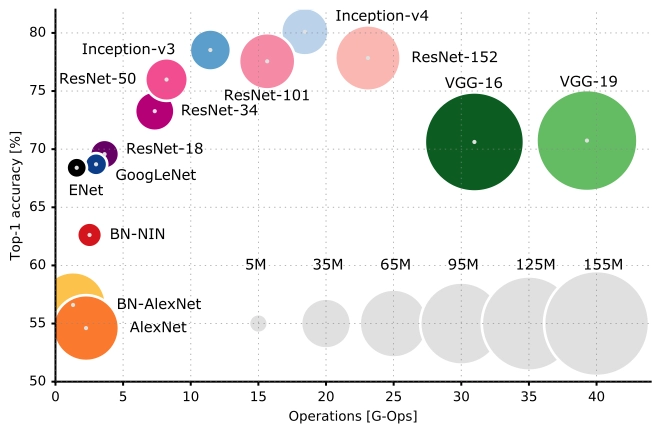
ImageNet Large-Scale Visual Recognition Challenge (ILSVRC) is a challenge that evaluates different algorithms for object detection and image classification. Each year, the winner of ILSRCV sets a new standard for visual recognition. InceptionNet is the winner of ILSRCV 2014 and significantly improved over AlexNet (winner of 2012) and ZFNet (winner of 2013). In this blog, we will talk about InceptionNet and its various versions.
InceptionNet uses a lot of tricks to improve performance in terms of accuracy and speed. InceptionNet uses Inception Modules to provide more efficient computation and deeper networks by reducing the dimensionality of the network with stacked 1X1 convolutions. The modules were created to address various difficulties, including computational expense and overfitting. In summary, rather than stacking different kernel filter sizes sequentially, the approach is to sequence them to function on the same level within the CNN.
How does an Inception Module functions?
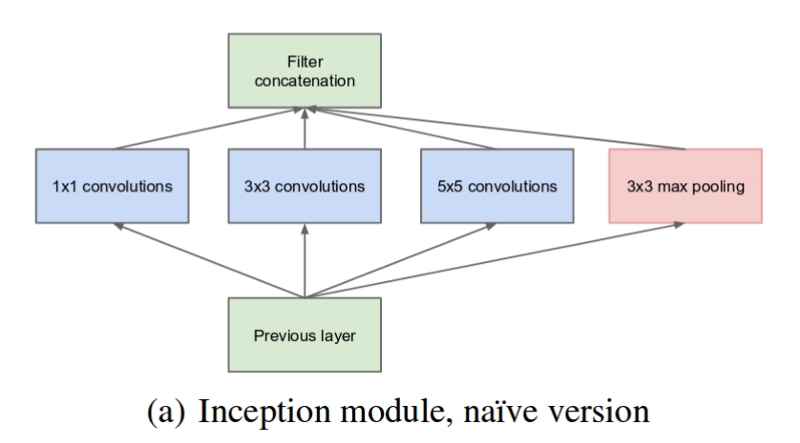
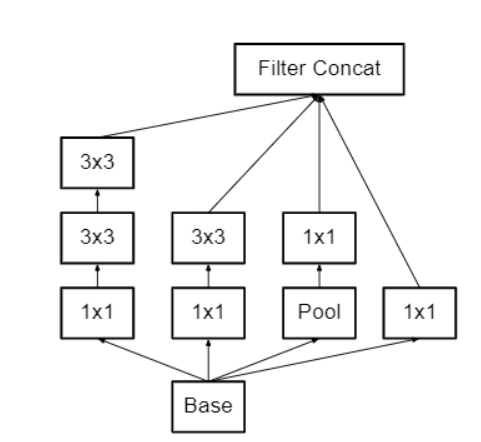
Inception Modules are used to cut down on processing costs. Neural networks must be designed effectively since they deal with many images with a wide range of featured visual material, also known as salient sections. Convolution is performed on input with not one but three different sizes of filters in the most basic version of an inception module (1x1, 3x3, 5x5). In addition, maximum pooling is used. The outputs are then concatenated and forwarded to the next tier. The network develops progressively wider, not deeper, by configuring the CNN to complete its convolutions on the same level.
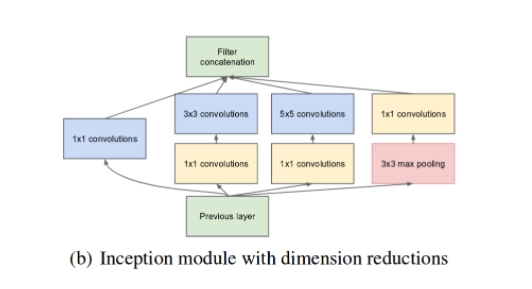
The neural network can be configured to add an extra 1x1 convolution before the 3x3 and 5x5 layers to make the process even less computationally expensive. The number of input channels is limited, and 1x1 convolutions are significantly less computationally costly than 5x5 convolutions. It's worth noting that the 1x1 convolution is applied after, not before, the max-pooling layer.
GoogLeNet, or Inception v1, is the name given to the design of the first Inception Module. Additional inception module modifications have been created to address difficulties such as the vanishing gradient problem.
There are several variations of Inception Network.
Why 1 X 1 convolutions are less expensive?
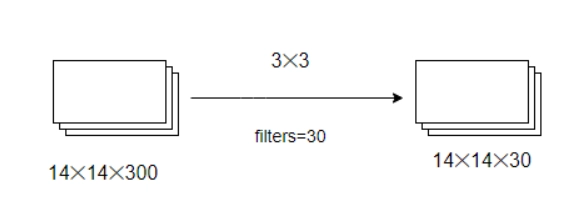
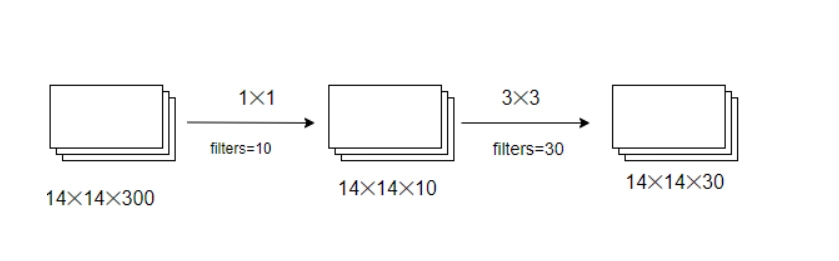
The 1X1 convolution is merely utilized to speed up the process. Let's look at an example to help you understand.
Assume you have to compute a 3X3 convolution with and without using a 1X1 convolution.
The total number of operations involved without 1x1 convolution is =(3*3*300)*(14*14*30) = 15876000.
The total number of operations involved when using 1x1 convolutional is = (14x14x10)x(1x1x300) + (14x14x30)(3x3x10) = 1117200.
The use of 1x1 convolutions reduces the number of operations by 14M. As a result, 1X1 convolutions can aid in the reduction of model size, which in turn can help in the removal of the overfitting problem..
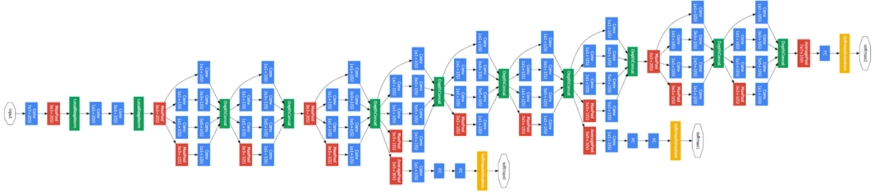
A neural network is built using this inception module and dimensionality reduction. Inceptionv1 or Google Net is the most basic neural network built in this manner. The following is a diagram of the architecture:
In GoogLeNet, there are nine such inception modules stacked linearly. It has 22 layers, including the pooling layers, for a total of 27. At the end of the previous inception module, it employs global average pooling. Its classification ability is excellent and can prevent the vanishing gradient problem, thanks to its lower data loss.
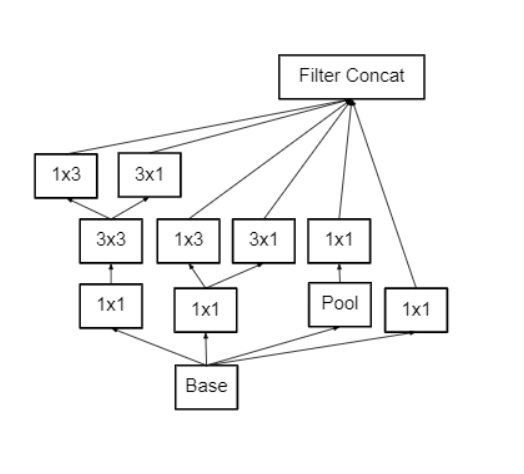
Inception v1 has issues with 5X5 convolution, which results in information loss. Furthermore, the complexity decreases when we utilize more extensive convolutions, such as 5X5, as opposed to 3X3. We may go much further in factorization, dividing a 3X3 convolution into an asymmetric 1X3 convolution, then a 3X1 convolution, and so on. This is the same as sliding a two-layer network with the same receptive field as a 3X3 convolution but at a 33% lower cost. When the input dimensions are large, this factorization does not work well for early layers, but it does when the input size is mm, where m is between 12 and 20.
Inception v2
Inception v2, 3X3 convolutions are employed in the 5X5 space to improve performance. Because a 5X5 convolution is 2.78 times more expensive than a 3X3 convolution, this reduces computing time and boosts computational speed. As a result, using two 3X3 layers instead of 5X5 improves architecture performance.
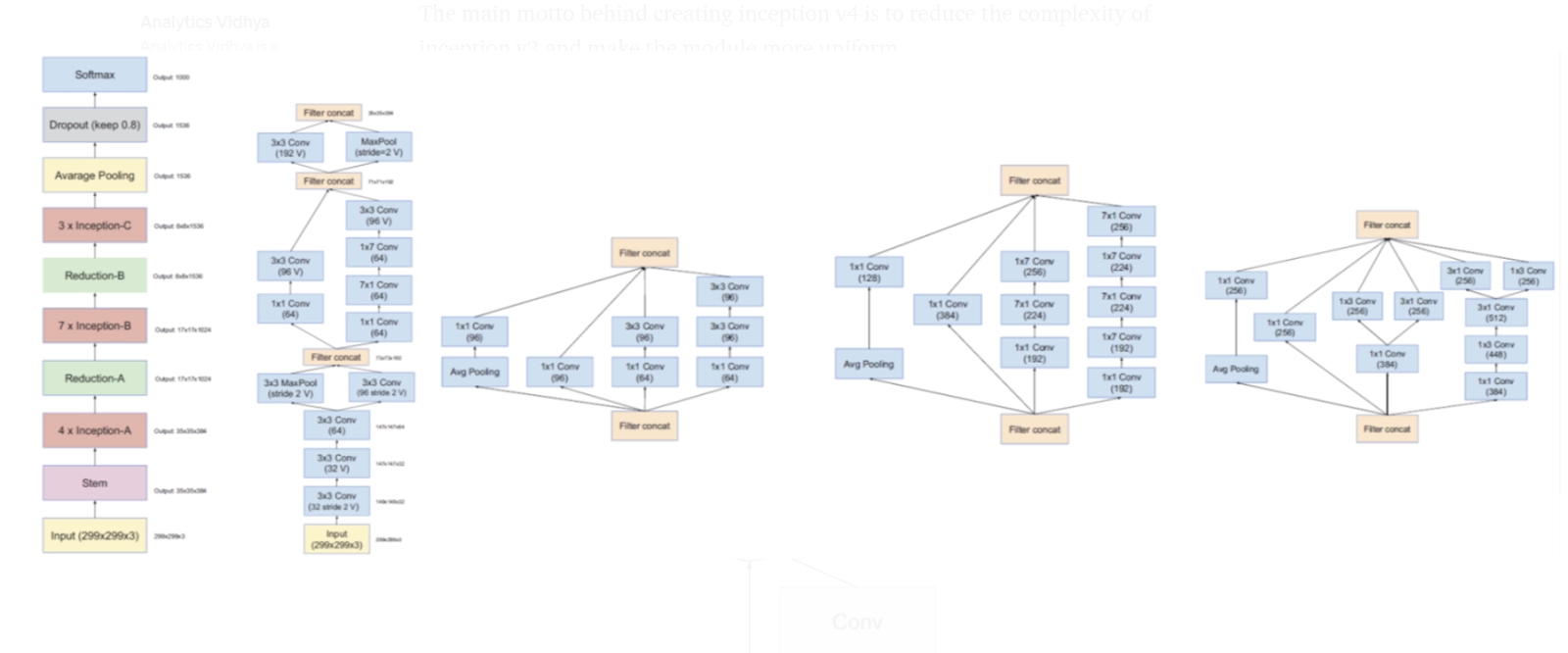
As demonstrated in fig2, the architecture also turns an nxn factorization into 1xn and nx1 factorization.
To deal with the problem of the representational bottleneck, the feature banks of the module were expanded instead of making it deeper. This would prevent the loss of information that causes when we make it deeper.
Except for a few changes, Inception v3 is nearly identical to Inception v2. The following are the most recent updates:
The RMSprop optimizer is used.
Batch normalization in the Auxiliary classifier's fully linked layer.
Convolution with a factor of 77%.
Regularization of Label Smoothing (a method to regularise the classifier by estimating the effect of label dropout during training). It stops the classifier from predicting a class with too much certainty. The addition of label smoothing improves the error rate by 0.2 percent.
Inception v4
The main goal of inception v4 was to make the module more standardized and reduce the complexity of inception v3.
There are no leftover connections in this Inception variation. It may be trained using memory optimization and backpropagation without splitting the replicas.
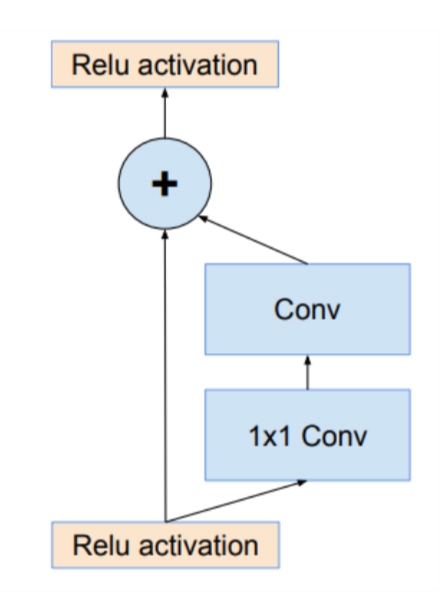
Inception-ResNet v1 and v2
A combination of inception and the residual module was proposed, inspired by the success of ResNet. This combo includes two models: Inception ResNet v1 and v2.
The calculation cost is reduced when the inception module is used in the above architecture. Each Inception block is followed by a filter expansion, a 1x1 convolution without activation. This is done to increase the filter bank's dimensionality to match the input depth to the following layer. After summations, batch normalization is not employed in Inception ResNets models. This is done to make the model smaller so it can be trained on a single GPU. The Reduction Block architectures are the same in both Inception architectures, but the stem topologies are different. They have different hyperparameters for training as well. Inception-ResNet V1 has a computational cost similar to Inception V3, and Inception-ResNet V2 has a computational cost identical to Inception v4.
Frequently Asked Questions
Why can't three 3x3 convolutions take the place of seven 7x7 convolutions in InceptionNet?
3x3 convolutions with 3 non-linear activation functions, boosting non-linear expression possibilities and separability of the segmentation plane. Reducing the number of parameters is a good idea. 7x7 provides parameters for the convolution kernel of C channels, and the number of 3x3 parameters is considerably decreased.
What is the role of a 1x1 convolution kernel?
Increase the model's nonlinearity while keeping the receptive field the same. The non-linear activation function plays a non-linear role in a 1x1 winding machine, which is comparable to linear transformation.
What is ResNet?
ResNet, or Residual Network, is a form of neural network. It was introduced in 2015 in the paper "Deep Residual Learning for Image Recognition," and is utilized as the backbone for many computer vision applications.
Is global average pooling used by the InceptionNet?
At the end of the previous inception module, it employs global average pooling. Needless to say, it's a quite sophisticated classifier. The vanishing gradient problem affects it, as it does any exceedingly deep network.
Conclusion
In this blog, we saw how InceptionNet outperforms prior versions of CNN models. It achieves top-five accuracy on ImageNet while drastically reducing computational costs without sacrificing speed or accuracy.






























 8+ registered
8+ registered 

