


























Introduction
Indexing improves database performance by reducing the number of disk accesses necessary when a query is run. It's a Data Structure strategy for finding and accessing data in a database rapidly.
An Index-
- As input, it accepts a search key.
- Returns a group of matching records quickly.
The indexing has several characteristics:
- Access Types: This relates to the access method, such as value-based search, range access, and so on.
- Access Time: It refers to the amount of time it takes to locate a specific data element or combination of data elements.
- Insertion Time. Refers to the time it takes to find and insert new data into the right place.
- Deletion Time: Time it takes to locate an item, delete it, and update the index structure.
- Space Overhead: It refers to the extra space that the index necessitates.
Types of Indexing

Source: Types of Indexing
The indexing properties of a database specify its indexing. There are two primary types of indexing methods:
- Primary Indexing
- Secondary Indexing
Primary Index
A primary index is a two-field, ordered file with a defined length. The first field is the same as the primary key, while the second field points to the data block in question. There is always a one-to-one relationship between the entries in the index table in the primary index.
The primary indexing in a Database management system is also divided into two types:
- Dense Index
- Sparse Index
Dense Index
For each search key value in the database, a record is created in a dense index. This allows you to search more quickly, but it requires more storage space for index information. Method records in this Indexing contain the search key value and point to the real record on the disk.

Source: Dense Index
Sparse Index
It's an index record that only appears for a subset of the file's values. Sparse indexes assist you in resolving DBMS dense indexing challenges. This indexing approach keeps the same data block address in a series of index columns, and when data is needed, the block address is retrieved.
Sparse Index, on the other hand, only keeps index entries for a subset of search-key values. It takes up less space and has a smaller maintenance overhead for insertions and deletions, but it is slower to locate records than a dense index.

Source: Sparse Index
Secondary Index
In a database management system, a secondary index can be constructed by a field that has a unique value for each record and should be a candidate key. A non-clustering index is another name for it.
To reduce the size of the first-level mapping, this two-level database indexing strategy is applied. Because of this, a wide range of values is chosen for the first level, and the mapping size is always kept minimal.
Clustering Index
The records themselves, not references, are stored in a clustered index. Non-primary key columns are sometimes used to build indexes, and they may not be unique for each record. In this case, you can aggregate two or more columns to generate unique values and create a clustered index. This also aids in the faster identification of the record.
What is a Multilevel Index, and how does it work?
When a primary index is too large to fit in memory, multilevel indexing is used. You can reduce the amount of disk access by shortening any record and keeping it on a disc as a sequential file, then creating a sparse base on that file using this indexing strategy.

Source: Multilevel Indexing
B-Tree Index
In relational databases, the B-tree index is the most extensively used data structure for tree-based indexing. It's a multilevel tree-based indexing strategy in DBMS that uses balanced binary search trees. The B tree's leaf nodes represent actual data references.
Furthermore, a link list connects all leaf nodes, allowing a B tree to enable random and sequential access.
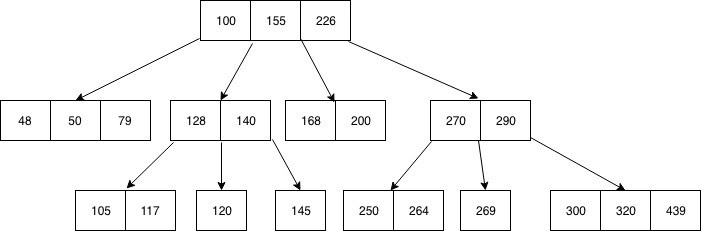
Source: B-Tree
- Between 2 and 4 values are required for lead nodes.
- Every path from the root to the leaf is roughly the same length.
- Apart from the root node, non-leaf nodes have between 3 and 5 offspring nodes.
- There are between n/2 and n children for every node that isn't a root or a leaf.


 8+ registered
8+ registered 

