



























Introduction
Input buffering is an most important technique in compiler design that helps to improve performance and reduce expenses, and it must be used carefully and appropriately to avoid problems.
To understand the input buffering in compiler design in detail, a few terms need to be understood. We will discuss those terms before moving to input buffering in compiler design.

Lexical Analyser
The lexical analyzer's main purpose is to read the source program's input characters, arrange them into lexemes, and output a sequence of tokens for each lexeme in the source program.
When the lexical analyzer finds a lexeme part of an identifier, it must add it to the symbol table.
The lexical analyzer not only recognizes lexemes but also does pre-processing on the source text, such as deleting comments and white spaces.
Lexeme
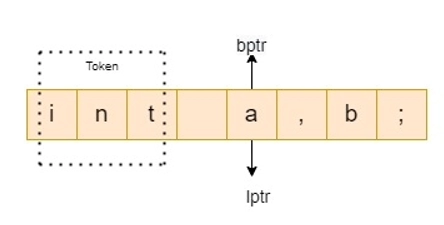
A lexeme is a sequence of characters in the source program that fits the pattern for a token and is recognized as an instance of that token by the lexical analyzer.
Token
A Token is a pair that consists of a token name and a value for an optional attribute.
The token name is a symbol that denotes the type of lexical unit.
Lexeme
| Lexeme | Token |
|---|---|
| = | EQUAL_OP |
| * | MULT_OP |
| , | COMMA |
| ( | LEFT_PAREN |
Pattern
A pattern is a description of the various forms that a token's lexemes can take. The pattern for a keyword as a token is just a series of characters that make up the term..
What is Input Buffering?
One or more characters beyond the following lexeme must be searched up to guarantee that the correct lexeme is identified.
As a result, a two-buffer system is used to safely manage huge lookaheads.
Using sentinels to mark the buffer end has been embraced as a technique for speeding up the lexical analyzer process.
Three general techniques for implementing a lexical analyzer
- With the help of a lexical-analyzer generator, you can: The generator does this by providing methods for reading and buffering the input.
- By building the lexical analyzer in a traditional systems programming language and reading the input with that language's I/O tools.
- Programming the lexical analyzer in assembly language and explicitly controlling the input reading.
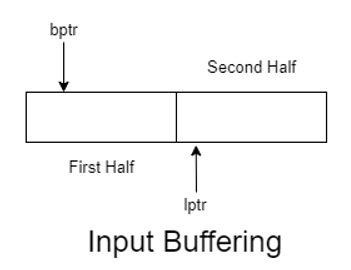
Buffer Pairs
Specialized buffering techniques decrease the overhead required to process an input character in moving characters.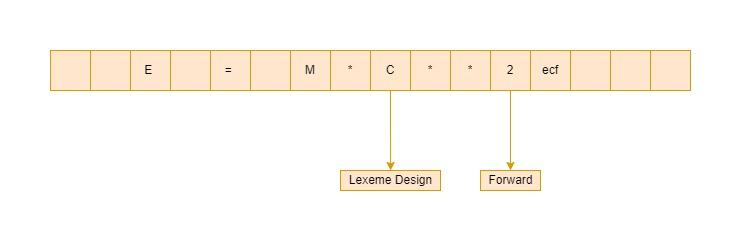
Buffer Pairs
- It consists of two buffers, each of which has an N-character size and is alternately reloaded.
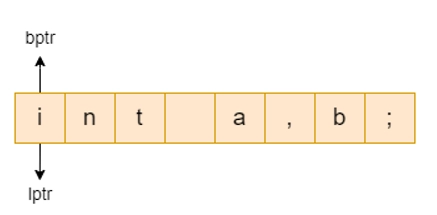
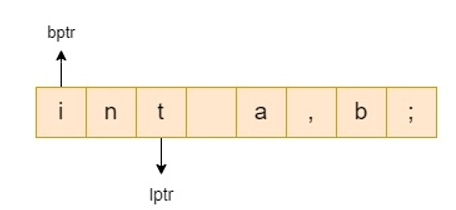
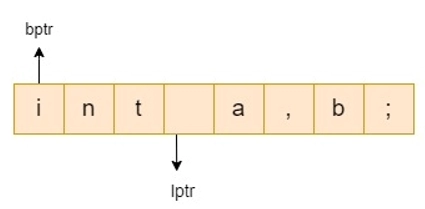
- There are two pointers: lexemeBegin and forward.
- Lexeme Begin denotes the start of the current lexeme, which has yet to be discovered.
- Forward scans until it finds a match for a pattern.
- When a lexeme is discovered, lexeme begin is set to the character immediately after the newly discovered lexeme, and forward is set to the character at the right end of the lexeme.
- The collection of characters between two points is the current lexeme.
Sentinels
Sentinels are used to performing a check each time the forward pointer is shifted to guarantee that one-half of the buffer has not gone off. If it's finished, the other half will need to be reloaded.
As a result, each advance of the forward pointer necessitates two checks at the ends of the buffer halves. Test 1: Check for the buffer's end. Test 2: To figure out which character is being read. By expanding each buffer in half to store a sentinel character at the end, sentinel reduces the two checks to one.
The sentinel is a unique character that isn't included in the source code. (The character of serves as a sentinel.)


 9+ registered
9+ registered 
