Inter-process communication through message passing method
The message passing method provides a mechanism to allow processes to communicate and to synchronize their actions without sharing the same memory space. This type of method is useful in distributed systems, where the communicating processes reside on different computers connected by a network.
The message passing method makes use of two basic operations:
- send(message): This operation is used by the sending process that wants to send a message to some other process.
- Receive (message): This operation is used by the receiving process that wants to receive a message from another process.
The message that is shared between the processes may be of fixed or variable size. In the fixed-size message, every process will send or receive the message of the fixed size, which is decided by the programmer or designer beforehand, while in variable-size messages, there is no limit to the size of the message.
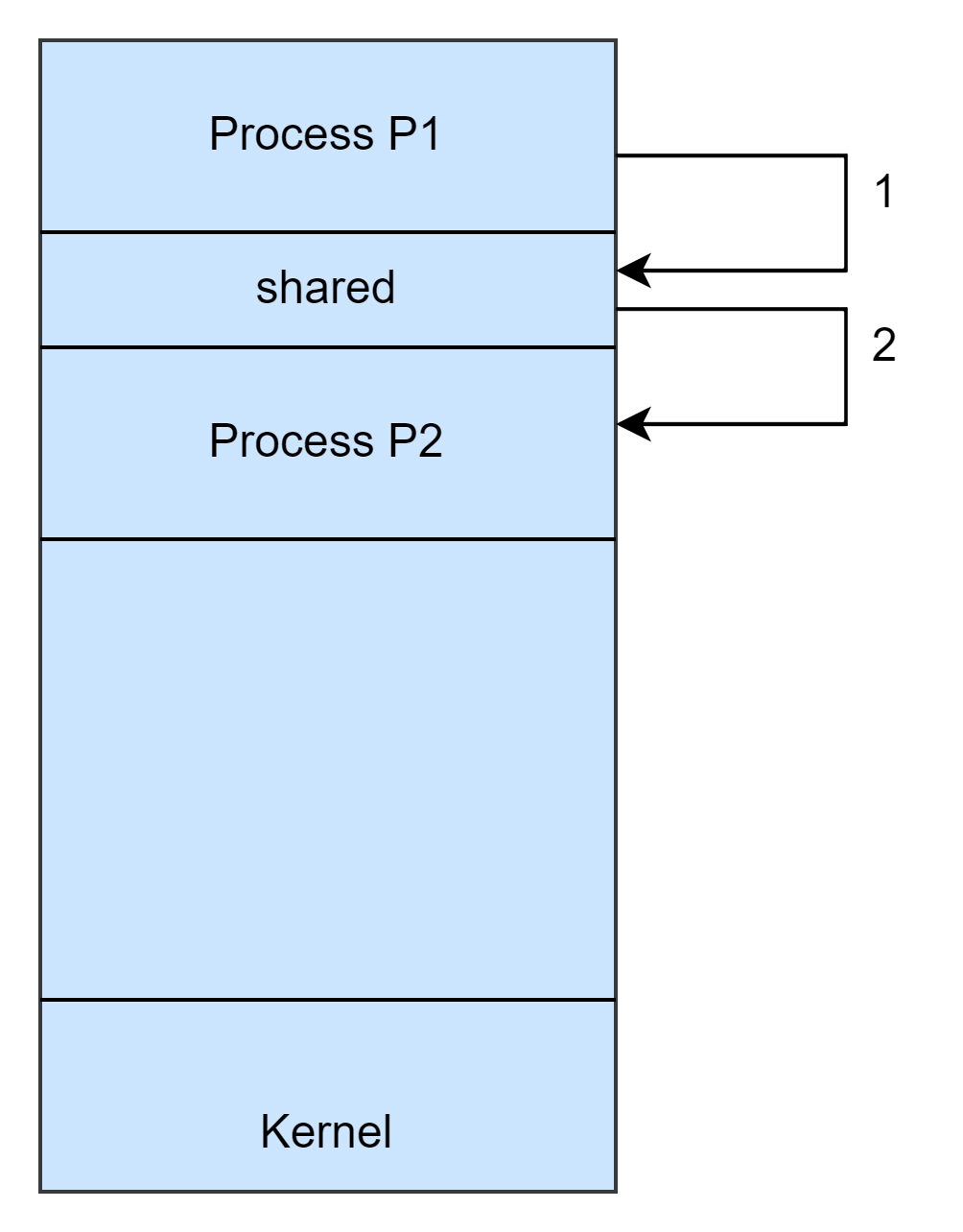
When two processes P1 and P2 wish to communicate with each other, there must be some facility such that both can send messages to each other and receive the message from each other. This facility is logically implemented using a communication link. A communication link can be simply thought of as a medium via which the processes share information.
There are three ways of logically implementing the communication link:
- Direct or indirect communication.
- Synchronous or asynchronous communication.
- Automatic or explicit buffering.
Direct and indirect communication
In the direct communication method, each process involved in the communication should explicitly name the recipient or sender of the communication.
The two operations in direct communication are:
- Send (P1, message): This operation is used by a process to send the message to process P1. Here the process that wants to send any message to some other process should explicitly name the processor should provide any other way to identify the process.
- Receive (P2, message): This operation is used by a process to receive the message from process P2. The process that wants to receive any message from P2 has to explicitly name it.
The communication link in the direct communication methods has the following features:
- The processes involved in the communication process should explicitly name each other for identification.
- The link is associated with exactly two processes.
- For every pair of processes, there exists exactly one communication link.
In the indirect communication method, there is a “mediator” that helps the processes to communicate with each other. This mediator is known as a mailbox or port. Instead of directly sending the messages to each other, their communication is done via the mailbox.
For two processes P1 and P2, to communicate, they must have a shared mailbox that can be owned by any of the processes. Whenever process P1 wants to send any message to process P2, it will first send the message to the mailbox. The process P2 will then read that message from the mailbox. A mailbox can be thought of as an object into which messages can be placed by processes and from which messages can be removed.
Suppose the mailbox is identified by A. The send and receive operations work as follow:
- Send (A, message): used to send the message to the mailbox A.
- Receive (A, message): used to receive the message from the mailbox A.
There can be multiple mailboxes for various processes involved in the communication. Each mailbox has its own identification and is unique.
The communication link in the indirect communication methods has the following features:
- Link is established between a pair of processes only if they have a shared mailbox through which they can share the messages.
- Unlike direct communication, here, there may be multiple processes associated with a link. For example, process P1 writes any message in the mailbox. The message then can be read by various other processes like P2, P3, P4.
- Each link, however, corresponds to one mailbox.
Synchronous and asynchronous communication
The message sharing between two processes can be synchronous or asynchronous. Synchronous is also known as blocking, and asynchronous is also known as non-blocking. When a process sends a message, the send primitive can be blocking or non-blocking. Similarly, when a process receives a message, the receive primitive can be blocking or non-blocking. We shall now discuss each of these.
- Blocking send: The sending primitive is blocking in nature. The process that is sending the message is blocked until the message is received by the receiving process.
- Non-blocking send: The sending process is not blocked after sending the message. The sending process can continue its other operations, which may be sending some other messages.
- Blocking receive: The receiving process is blocked until it receives the message from the sending process. A receiving process implements receive primitives. In case of blocking receive, it will be blocked until it gets the message that it has sought through receive primitive.
- Non-blocking receive: The receiving process will not be blocked. It is either going to receive the message from the sending processor will receive a null in case of any failure.
Buffering
Whenever the processes communicate, either directly or indirectly, the messages that are to be exchanged are stored in a temporary queue known as buffers. Various types of such queues or buffers are:
- Zero capacity: The maximum length or size of the queue is zero. In this kind of buffer, the messages cannot be stored. It works as a gateway for the sending process to send the message to the receiving process. Here the send primitive is blocking in nature because the sender process must be blocked unless and until the receiving process receives the message. If the sending process is not blocked, it may continue to send messages to the process which is yet to receive the first message. But the problem is that the buffer size is zero, so the second message that has been sent cannot be stored. Only one message can be sent at a time.
- Bounded capacity: Unlike the zero capacity buffer, the bounded capacity buffer has a finite size. The sender process can keep sending the messages into the buffer until it gets full. So, the sender process here need not be blocked if the buffer is not full. Since the bounded capacity buffer has a finite size, at some point of time it may get full. In such a case, the sender must be blocked until the messages are retrieved from the buffer to free some space.
- Unbounded buffer: In such types of buffers, the size is infinite. Here the sender can send any amount of messages without getting blocked because there is no memory constraint.
Frequently Asked Questions
What is inter-process communication?
Inter-process communication is a mechanism by which processes communicate with each other.
Name the two popular mechanisms of IPC.
Shared memory, message passing.
What are the two basic primitives used in the message passing method?
send() and receive()
Where is the message passing method mostly used?
Distributed environment.
What is the difference between a bounded and unbounded buffer?
The size of the bounded buffer is finite; hence there is a restriction on the number of messages it can store at any given time, however in an unbounded buffer the size is infinite, and there is no restriction on the number of messages it can store.
Give an example of direct communication.
Print server.
Conclusion
- Inter-process communication is a mechanism by which processes communicate with each other.
- Two ways of inter-process communication are the shared memory method and the message passing method.
- In the shared memory method, two processes communicate with each other using common shared memory. E.g.: Producer-consumer problem.
- The message passing method provides a mechanism to allow processes to communicate and to synchronize their actions without sharing the same memory space. This type of method is useful in distributed systems.
- Two basic operations in the message passing method send () and receive().
- A communication link can be simply thought of as a medium via which the processes share information.
- Synchronous is also known as blocking, and asynchronous is also known as non-blocking.
- Whenever the processes communicate, either directly or indirectly, the messages that are to be exchanged are stored in a temporary queue known as buffers.
Recommended Readings:
Do check out The Interview guide for Product Based Companies as well as some of the Popular Interview Problems from Top companies like Amazon, Adobe, Google, Uber, Microsoft, etc. on Coding Ninjas Studio.
Also check out some of the Guided Paths on topics such as Data Structure and Algorithms, Competitive Programming, Operating Systems, Computer Networks, DBMS, System Design, etc. as well as some Contests, Test Series, Interview Bundles, and some Interview Experiences curated by top Industry Experts only on Coding Ninjas Studio.
Happy learning!






























 9+ registered
9+ registered 
