Do you think IIT Guwahati certified course can help you in your career?
Introduction
Several problems cannot be solved using regular algorithms like greedy or divide and conquer, and the solutions they provide are not optimal.
So, we use Dynamic Programming, which is an optimization of simple recursion to solve such problems. The basic idea is to store the results of sub-problems to avoid re-calculation and reduce the time complexity of the problems.
This blog will discuss one such fundamental problem of interleaving strings, which can easily be solved using dynamic programming.
Problem Statement
You are given 3 strings, S1, S2, and S3. You have to check whether the string S3 can be formed by interleaving strings S1 and S2.
NOTE: A string S3 is said to be an interleaving string if it contains all characters of strings S1 and S2 and the order of all the characters is the same as in the individual strings.
Let us try to understand this with the help of a simple example:
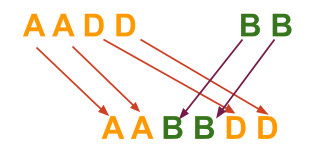
Example
S1 = “AADD“
S2 = “BB“
S3 = “AABBDD“
Thus, S3 is an interleaving string formed by the2 strings S1 and S2.
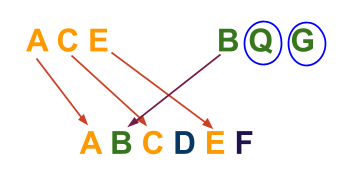
2. S1 = “ACE“
S2 = “BQG“
S3 = “ABCDEF“
Since the letters Q and G of string S2 do not occur in S3, S3 is not an interleaving string.
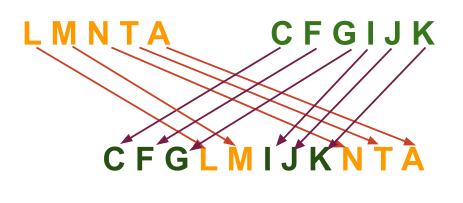
3. S1 = “LMNTA “
S2 = “CFGIJK“
S3 = “CFGLMIJKNTA“
Thus, S3 is an interleaving string formed by the2 strings S1 and S2.
Now, let us first solve this problem using basic Recursion, and then we will see how we can optimize our solution with the help of dynamic programming.
Recursion
The recursive approach consists of a function that takes in 3 parameters, strings S1, S2, and S3.
We have to keep 2 primary conditions in mind so that our logic works correctly for all test cases:
If the first character of S3 matches with the first character of S1, we move to the next character of S1 and S3 and call the function recursively.
If the first character of S3 matches with the first character of S2, we move to the next character of S2 and S3 and call the function recursively.
Let us try to understand the algorithm first before moving on to the actual code.
Algorithm
Create a recursive function that will check if the given string is interleaving or not.
Check if the length of S3 equals the sum of the lengths of strings S1 and S2. If not, we return false.
If the first character of string S3 matches that of S1, call the function by passing the remaining part of S1 and S3.
If the first character of string S3 matches with S2, call the function by passing the remaining portion of S2 and S3.
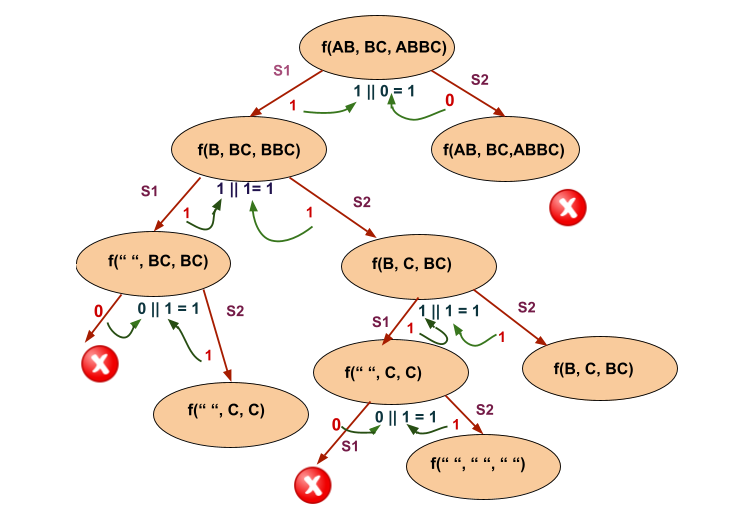
The algorithm may look confusing, so let's dry run a simple test case and better understand the concept.
Let us consider a simple example where
S1 = “AB“
S2 = “BC“
S3 = “ABBC“
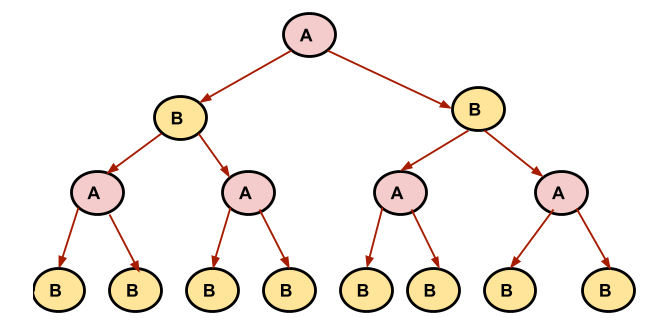
Let us take a look at the recursive tree for this example:
Implementation
/* C++ program to check if the given string, 'S3', is formed by the interleaving of two other strings,'S1' and 'S2', using simple recursion. */
#include <iostream>
#include <string>
using namespace std;
// Recursive function to check whether the string 'S3' is interleaving or not.
bool isInterleaving(string s1, string s2, string s3)
{
// Return true if the end of all strings is reached
// Base case condition, i.e., all strings have been traversed completely.
if (!s1.length() && !s2.length() && !s3.length())
{
return true;
}
// The function breaks if string 'S3' has been traversed completely, but 'S1' and 'S2' have not.
if (!s3.length())
{
return false;
}
// If the string 'S1' is not empty and the first character of 'S1' matches with that of 'S3'.
// Call the recursive function for the remaining substrings.
bool x = (s1.length() && s3[0] == s1[0]) &&
isInterleaving(s1.substr(1), s2, s3.substr(1));
// If the string 'S2' is not empty and the first character of 'S2' matches with that of 'S3'.
// Call the recursive function for the remaining substrings.
bool y = (s2.length() && s3[0] == s2[0]) &&
isInterleaving(s1, s2.substr(1), s3.substr(1));
// Returning the 'OR' of the two boolean variables.
return x || y;
}
int main()
{
string s1, s2, s3;
// Taking user input.
cout << "Enter the three strings: \n";
cin >> s1 >> s2 >> s3;
// Answer exists only if the length of S3 is equal to the sum of lengths of S1 and S2, else the answer will be false.
if (s1.length() + s2.length() == s3.length())
{
// Calling the function to check the strings.
if (isInterleaving(s1, s2, s3))
cout << "Yes the string " << s3 << " is interleaving";
else
cout << "No, the string " << s3 << " is not interleaving";
}
else
cout << "No, the string " << s3 << " is not interleaving";
return 0;
}
You can also try this code with Online C++ Compiler
O(2M+N), where M is the length of string ‘S1’ and ‘N’ is the length of string ‘S2’.
The character in string S3 can come from either S1 or S2. If the length of string S1 is M and that of string S2 is N, the length of string S3 will be M + N. Since every character has 2 possibilities and the total number of possibilities is 2M+N.
Space Complexity
O(M + N), or simply O(L), where ‘M’, ‘N’ and ‘L’ are the lengths of string ‘S1’, ‘S2’, and ‘S3’, respectively.
In any case, there will be a maximum of ‘L’ function calls that will occupy O(L) space of the recursion call stack. Hence, the space complexity is given by O(L).
Problems
Though the above approach is logically correct, it often poses the problem of time limit exceed. In the case of repetition of characters in the string, the recursion tree will have many overlapping subproblems, and multiple paths will be formed for every character.
The depth of the tree will be equal to the length of the string S3.
The recursion tree for a simple example,given below has been shown:
An optimized approach to solving the above problem is to use dynamic programming. In this technique, we will be using a hashmap or a memoization array to store the results of the sub-problems in a top-down manner. The bottom-up approach of the above solution would be to use a table and store the values accordingly.
Algorithm
We will maintain a 2-D memoization array or a simple unordered hash map of type <string, bool>, i.e., the value will either be true or false, where we will keep track of the substrings encountered so far.
We will also maintain 3 pointers, p1, p2, and p3, which will point to the current character of the strings S1, S2, and S3 respectively.
To keep the values of keys unique, we will convert the pointers into strings, compute the value of p1#p2#p3, and then mark it in the hash map. This helps reduce the redundancy of values, and if a value has already occurred, it does not have to be recalculated.
If the sum of the lengths of S1 and S2 is not equal to the length of S3, we exit the function and return false, as string S3 can not be interleaving in this case. Else we will call the recursive function.
If the value of S1[p1] equals the value of S3[p3], the pointers,p1 and p3, are incremented, and the function is called again.
Similarly, If the value of S2[p2] equals the value of S3[p3], the pointers,p2 and p3, are incremented, and the function is called again.
In order to stop the recursive call, we need a base condition which is, p3==S3.length(). When our function meets this condition, it will returnfalse if(p1!=S1.length() or p2!=S2.length()) else it will return true.
Implementation
/* C++ program to check if the given string, S3, is formed by the interleaving of two other strings, S1 and S2, using the top-down approach. */
#include <iostream>
#include <string>
#include <unordered_map>
using namespace std;
// Declaring an unordered map for memoization.
unordered_map<string, bool> mem;
// Recursive function to check whether the string S3 is interleaving or not.
// p1,p2, and p3 are the 3 pointers that will be used to iterate the strings S!, S2, and S3, respectively.
bool check(string s1, string s2, string s3, int m, int n, int l, int p1, int p2, int p3)
{
/* Base case condition, i.e., if the string S3 has been traversed completely, then strings S1 and S2 also should have been traversed completely. */
if (p3 == l)
return (p1 == m and p2 == n) ? true : false;
// Calculating a unique map key using * operator to avoid repetition of keys.
string key = to_string(p1) + "#" + to_string(p2) + "#" + to_string(p3);
// The key is returned if it is already found in the map.
if (mem.find(key) != mem.end())
return mem[key];
// If string S1 has been completely traversed.
// Comparing the characters of string S2 and S3.
if (p1 == m)
return mem[key] = s2[p2] == s3[p3] ? check(s1, s2, s3, m, n, l, p1, p2 + 1, p3 + 1) : false;
// If string S2 has been completely traversed.
// Comparing the characters of string S1 and S3.
if (p2 == n)
return mem[key] = s1[p1] == s3[p3] ? check(s1, s2, s3, m, n, l, p1 + 1, p2, p3 + 1) : false;
// Initialising 2 boolean variables.
bool flag1 = false, flag2 = false;
// If the character of S1 and S3 matches.
if (s1[p1] == s3[p3])
flag1 = check(s1, s2, s3, m, n, l, p1 + 1, p2, p3 + 1);
// If the character of S2 and S3 matches.
if (s2[p2] == s3[p3])
flag2 = check(s1, s2, s3, m, n, l, p1, p2 + 1, p3 + 1);
// Returning the 'OR' of the two boolean variables.
return mem[key] = flag1 || flag2;
}
/* Function to check the basic condition and call the check function
after the user provides input.*/
bool isInterleaving(string s1, string s2, string s3)
{
// Calculating the lengths of the strings entered by the user.
int m = s1.length();
int n = s2.length();
int l = s3.length();
/* If the length of S3 is not equal to the sum of the lengths of S1 and S2,
the function returns false.*/
if (l != m + n)
return false;
// Otherwise it calls the check function.
return check(s1, s2, s3, m, n, l, 0, 0, 0);
}
int main()
{
string s1, s2, s3;
// Taking user input.
cout << "Enter the three strings: \n";
cin >> s1 >> s2 >> s3;
// Calling the function to check the strings.
if (isInterleaving(s1, s2, s3))
cout << "Yes, the string " << s3 << " is interleaving";
else
cout << "No, the string " << s3 << " is not interleaving";
return 0;
}
You can also try this code with Online C++ Compiler
The time complexity is given by O(M*N), where M is the length of string S1, and N is the length of string S2.
This is because every combination is computed only once and there are a total of M*N possible combinations.
Space Complexity
The space complexity is given by O(M*N), where M is the length of string S1, and N is the length of string S2.
This is because we are using an unorderedhashmap whose size can go up to M*N in the worst case, to store all possible combinations.
Key Takeaways
So, this blog discussed two different approaches to solve the famous and most fundamental problem of dynamic programming and discussed how the time complexity can be reduced significantly by using dynamic programming.
To learn more, head over right now toCoding Ninjas Studio to practice problems on dynamic programming and strings and crack your interviews like a Ninja!






























 9+ registered
9+ registered 

