Get a skill gap analysis, personalised roadmap, and AI-powered resume optimisation.
Introduction
Have you ever wondered how the Apache Spark framework could efficiently process such large volumes of data, also called Big Data? Then you have come to the right place.
In this article, we are going to discuss Apache Spark in detail. We will discuss some of the key features and components of the Apache Spark framework. We will also dive into the applications of the Spark framework.
Apache Spark is a popular free and open-source distributed computing system among users. Apache Spark's ability to process large amounts of data efficiently makes it a valuable tool in machine learning. In the upcoming sections, we will discuss the features and components of Apache Spark. But first, let us learn a bit more about it.
What is Apache Spark
As discussed in the previous section, Apache Spark is an open-source computing system designed for users to process large amounts of data using parallel processing techniques. Unlike traditional disk-based systems, which need separate disk memory, Spark uses in-memory computing, which results in faster processing times for the user.
This ability of Apache Spark makes it a good prospect for real-time applications as it can process queries faster, which is one of the main priorities in real-time applications.
Compared to traditional computer platforms, Apache Spark offers a faster data processing speed. It is straightforward to use and has widespread community support, which makes it easier for any beginner to learn. Now that you have understood the basics of Apache Spark, we will cover some important features of Apache Spark in the next section.
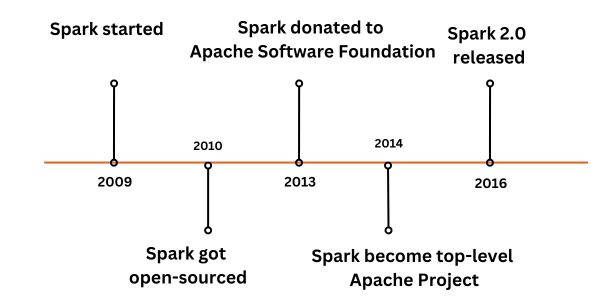
Matei Zaharia started Apache Spark in 2009 and open-sourced in 2010. In 2013, the project was contributed to the Apache Software Foundation and licensed under the Apache 2.0 license. Spark became a top-level Apache project in 2014. Apache Spark had more than 1000 contributors in 2015, making it one of the most active projects of the Apache Software Foundation and a popular project for big data processing.
Spark Architecture
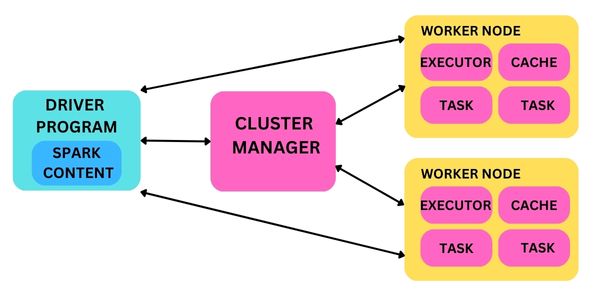
Apache Spark follows a master-slave architecture, where the master node hosts the driver program, and the worker nodes run multiple executors. The driver program acts as the main entry point and creates a SparkContext. It acts like a gateway to all Spark functionalities. Spark applications run as independent sets of processes on the cluster.
The cluster manager is responsible for resource management and coordination of Spark applications. It can be Spark's standalone cluster manager or other third-party cluster managers like Apache Mesos or Hadoop YARN. The cluster manager allocates resources and schedules tasks across the worker nodes. Spark divides a job into tasks that are distributed across the worker nodes for parallel execution.
Driver: It is the master node in the cluster. Its primary function is to maintain coordination between different executions in the Spark application.
Worker Nodes: The worker nodes act as a slave in these clusters and are responsible for executing different tasks assigned to them by the master node.
SparkContent: It is the gateway to all of Spark's functionality. It provides a platform to create RDDs and submit jobs to the cluster.
RDDs:RDDs are immutable datasets distributed among the clusters after dividing them into logical portions.
Jobs: Jobs are a collection of tasks submitted to the clusters.
Tasks: It is a subset of the Jobs. They are the smallest unit in the working of Spark.
When an RDD (Resilient Distributed Dataset) get created in the SparkContext, it can be partitioned and spread across various nodes in the cluster. The worker nodes act as slaves and execute different tasks assigned to them. Spark's architecture consists of a master node hosting the driver program, worker nodes running executors, a cluster manager for resource management, and the distribution of tasks and data across the cluster. This architecture enables parallel and distributed processing of data, making Spark efficient for big data analytics and processing workloads.
Features of Apache Spark
Apache Spark has many capabilities, making it one of the most popular big data frameworks. Some of these attributes are described below.
Speed
Unlike traditional disk-based systems, which need separate disk memory, Spark uses in-memory computing, which results in faster processing times for the user.
Fault Tolerance
A system's ability to handle failures is known as Fault Tolerance. A system designed on the Spark framework is built to continue processing even if some of the nodes (computers) in the cluster fail.
Easy to Use
Apache Spark has an easy-to-use API (Application Programming Interface) in multiple programming languages. Despite their proficiency in some languages, this ability allows all the users to develop and deploy applications quickly.
Integration
Apache Spark is easy to integrate with other frameworks like Hadoop. This makes retrieving data from various sources accessible irrespective of the data structure they follow.
Scalability
Like other big data processing architectures, Spark is also designed to scale data horizontally. Hence it allows the user to increase the number of systems as the data volume increases.
Data Visualization
Apache Spark can integrate with different libraries like Apache Zeppelin and Jupyter Notebooks, making the data visualization process more efficient.
Components of Apache Spark
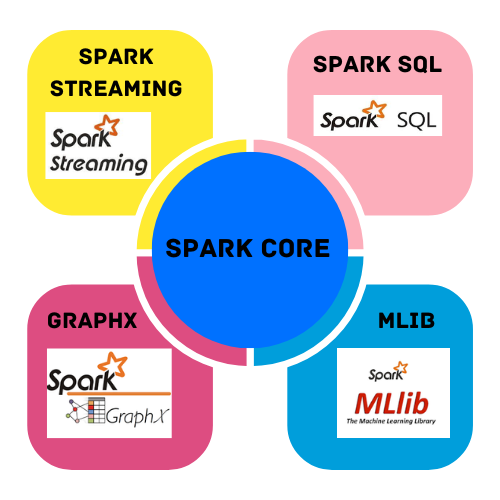
Apache Spark is made up of five major components. These components work together to provide a complete framework for processing big data. These components are Spark Core, Spark SQL, Spark Streaming, MLib, and GraphX. In this section, we will discuss each of these in detail.
Spark Core
The Apache Spark core is the crucial component of the Spark framework. It provides the fundamental functionality and the framework for distributed data processing. Spark Core has capabilities such as in-memorycomputation, simpleintegration, faultrecovery, and so on.
Spark SQL
Spark SQL is a component of the Apache Spark framework that gives users a user interface for SQL data querying. Spark SQL enhances the performance of SQL queries by integrating them with the distributed system and providing fundamental tools and frameworks for distributed data processing. Spark Core offers capabilities, including fault recovery, in-memory processing, and simple integration.
Spark Streaming
A real-time data processing engine known as Spark Streaming is also one of the main components of the Spark framework. It supports different data sources like Kafka, Kinesis, Flume, and HDFS (Hadoop Distributed File System). This qualifies it for applications that call for continual data processing.
MLib
MLib is an Apache Spark machine learning library that offers a distributed and scalable platform for implementing machine learning algorithms. It enhances the functionality and smooth ecosystem integration of machine learning models.
GraphX
GraphX is the graph processing framework built on Apache Spark. GraphX provides an API to work with graphs making it easy to work with graph-based computations. GraphX also supports various graph algorithms for multiple graph applications like socialnetworkanalysis and recommendationsystems.
There are a number of reasons why we should use Apache Spark over a SQL-only engine.
Flexibility - Spark supports many languages, such as Python, Java, and Scala. Spark has a unified platform for various data processing activities, including batch processing, real-time streaming, machine learning, and graph processing. If the user wants to analyze data beyond SQL, it is impossible in a SQL-only engine.
Performance - Spark is built to analyze massive data sets quickly and has features for distributed computing and parallel processing. Data is distributed among a group of computers, allowing faster execution.
Scalability - Spark can distribute workloads horizontally over a cluster of computers to enhance processing speeds and storage capacities. Spark can effectively manage large amounts of data and perform complex calculations.
Environment - Spark has various libraries and tools to increase its capability. For instance, Spark SQL enables you to combine SQL queries with Spark's other features, such as Spark Streaming for real-time data processing or MLlib for machine learning jobs.
These are some advantages you should consider while choosing Spark over SQL-only Engines.
Related products and Services of Spark
Apache Spark is a helpful framework for data processing due to its powerful data processing capabilities. Consequently, this made it gain significant use among various industries. Some of the most common applications of Apache Spark are discussed below.
Big Data Processing
Apache Spark has a powerful data processing system for analyzing large datasets. This makes it an essential tool for data cleaning and data processing. Moreover, Apache Spark's capabilities of distributed computation and in-memory calculation allow it to process and analyze large amounts of data efficiently.
E-Commerce
Apache Spark is used in E-commerce platforms to get real-time analytics from the users and generate personalized experiences. E-commerce platforms collect user-generated data, process it and then use it to extract patterns in the market. These patterns are vital in recognizing the current market trends and providing a personalizing experience to the users.
Financial Institutions
Financial institutions also use Spark for various applications like fraud detection systems. These applications process large volumes of transactions in real time and report suspicious transactions to prevent fraud.
Internet of Things (IOT)
Apache Spark is an excellent framework for use in IoT. Its ability to process data in real time allows it to handle data from various peripheral sensors and process it with as little delay as possible.
HealthCare
Apache Spark is used in healthcare systems for processing large amounts of patient data entries, etc. It can also be used to develop chatbots based on the processed data.
Alternatives of Apache Spark
Today, several alternatives to Apache Spark are in the big-data processing market. These alternatives provide similar computing abilities and features to Apache Spark. Some of the popular options are discussed below briefly.
Apache Flink
Similar to Spark, Apache Flink is a popular framework for stream processing. Apache Spark provides low-latency processing, making it a popular real-time application choice.
Apache Hadoop
Hadoop is also one of the most popular distributed processing frameworks. Hadoop is used for parallel processing of large values of data over a distributed system of computers.
DataBricks
Azure Databricks is a cloud-based platform for performing data analysis like Spark. DataBricks platform supports the Apache Spark framework and provides some other additional tools on top of that. DataBricks was developed by the creators of Apache Spark to provide an alternative to Hadoop's MapReduce technology.
Apache Hive
Apache Hive is a distributed, open-source data warehouse software for processing data. One of the main advantages of Apache Hive is that it allows the users to write queries in SQL format and automatically translates them into formats like Spark, MapReduce, etc.
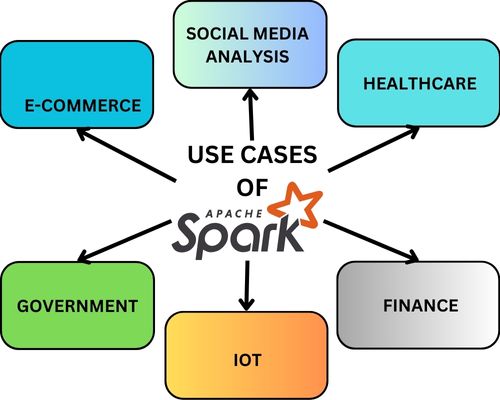
Use Cases of Apache Spark
There are different use cases of Apache Spark like:
E-Commerce
E-commerce platforms use Spark to drive real-time analytics and personalized experiences. They are used in recommendation engines to offer customized product suggestions to customers, drawing insights from their browsing and purchase history.
Healthcare
Spark plays an essential role in the processing and analysis of Electronic Health Records (EHRs), Medical Imaging Data, and genomic data. It can be used in clinical decision support systems(chatbots), disease prediction models, and drug discovery research, driving advancements in healthcare and precision medicine.
Finance
Financial institutions use Spark for implementing fraud detection systems. By processing massive volumes of transactional data in real time, Spark can quickly identify patterns and red flag suspicious activities that can give us an alarm to prevent fraudulent transactions.
Government
Government agencies use Spark to analyze extensive datasets, enabling improved decision-making, optimized public services, fraud detection, and enhanced security measures.
Internet of Things(IOT)
Apache Spark is an open-source distributed processing system well-suited for handling vast sensor data from Internet of Things (IoT) devices. Spark's capabilities enable real-time data processing, anomaly detection, predictive maintenance, and intelligent grid analytics. With Spark's stream processing features, organizations can gain real-time insights and swiftly respond to events occurring in the IoT environment.
Social Media Analysis
Apache Spark is a powerful tool for processing and analyzing social media data. It can extract insights, sentiment analysis, topic modeling, and influence detection. Businesses can use social media data to understand real-time customer preferences, trends, and brand reputation.
Difference Between Hadoop and Spark
Features
Hadoop
Apache Spark
Data Processing model
Batch Processing.
Batch Processing and Real-Time Stream Processing.
Processing Speed
It is slower because of disk-based processing.
It is faster as compared to Hadoop because it uses memory processing.
Data storage
It uses Hadoop Distributed File System (HDFS).
It uses different data storages including HDFS.
Programming languages
It mainly supports Java.
It supports multiple languages like Java, Python, Scale, etc.
Real-Time Processing
Real-time processing capabilities are limited in Hadoop.
It has Built-in real-time stream process with Spark Streaming.
Data caching
Disk-based caching.
In-memory caching is present which increases the data access speed.
Graph Processing
Graph Processing capabilities are limited in Hadoop.
It can integrate Graph Processing Library (GraphX).
Frequently Asked Questions
What is Apache Spark used for?
Apache Spark is used for large-scale data processing and analytics. It's an open-source, cluster computing framework that enables high-speed data processing, machine learning, and graph processing.
Is Apache Spark an ETL tool?
While Apache Spark can be used for ETL (Extract, Transform, Load) processes, it is not primarily an ETL tool but a general-purpose, high-performance data processing framework that includes ETL capabilities.
What is Apache Spark vs Hadoop?
Apache Spark and Hadoop are both big data processing frameworks, but Spark is faster due to in-memory processing, while Hadoop primarily uses disk storage. Spark is more suitable for iterative processing and real-time data analysis.
Is Apache Spark like SQL?
Apache Spark includes Spark SQL, a module that allows SQL-like querying of structured data. It provides a SQL interface for data processing, making it easier for data analysts and engineers to work with large datasets.
Conclusion
In this article, we discussed Apache Spark in detail. We discussed some key features and components of Apache Spark. We also discussed some applications of the Spark framework why it is better to choose Apache Spark over SQL-only frameworks. In the end, we concluded by discussing some applications of Apache Spark and some frequently asked questions. So now that you have learned about Apache Spark, you can refer to similar articles.


































 9+ registered
9+ registered 

