Get a skill gap analysis, personalised roadmap, and AI-powered resume optimisation.
Introduction
The tree is one of the most commonly used data structures in computer science. As a result, numerous alternative variants have been created. We'll get a deeper understanding of the so-called B-trees in this blog. To accomplish so, we must first comprehend its various components and structure. Following that, we'll look at their various operations, such as searching, insertion, and deletion. Finally, we'll go over the advantages and disadvantages of using B-trees for data storage.
A B-tree of order m, according to Knuth's definition, is a tree that satisfies the following properties:
A maximum of m children can be found in each node.
Except for root, every non-leaf node has at least m/2 child nodes.
There are at least two children if the root is not a leaf node.
There are k-1 keys in a non-leaf node with k children.
All of the leaves are on the same level and are devoid of any information.
The keys of each internal node serve as separation values, dividing its subtrees. For example, if an internal node has three subtrees, it must have two keys: a1 and a2. All values in the leftmost subtree will be less than a1, all values in the middle subtree will be between a1 and a2, and all values in the rightmost subtree will be greater than a2. Internal nodes
Operations on B-Tree
B-Trees support efficient data handling operations and are widely used in databases and file systems due to their ability to manage large datasets with minimal disk access. They maintain balance by storing multiple keys per node, ensuring logarithmic time complexity for major operations.
1. Search
The search operation finds whether a key exists in the B-Tree. It starts from the root and recursively checks child pointers based on key comparison.
Time Complexity: O(log n)
Example: Like finding a name in a well-organized phone directory split alphabetically.
2. Insert
Insertion involves finding the correct node for a new key and placing it in sorted order. If the node exceeds its capacity, it splits and propagates changes up the tree.
Time Complexity: O(log n)
Example: Like inserting a book into a sorted shelf and adjusting rows if space runs out.
3. Delete
Deletion removes a key while maintaining balance. It may involve redistributing or merging nodes if a minimum key threshold is violated.
Time Complexity: O(log n)
Example: Like removing a book from a library shelf and rearranging others to fill gaps.
4. Traverse
Traversal visits all keys in sorted order, typically using in-order traversal.
Time Complexity: O(n)
Example: Like scanning through a sorted list of items one by one.
These operations ensure that the B-Tree stays balanced and efficient even as data grows dynamically.
Need of a B-Tree in Data Structure
B-Trees are critical in handling large-scale data efficiently, especially in systems where quick access and minimal disk reads are vital.
Improved Performance Over M-way Trees
B-Trees outperform basic M-way trees by maintaining strict balance and node utilization. Each node has a fixed key capacity, ensuring uniform height and reduced depth. This minimizes the number of node accesses during operations, improving consistency and speed.
Optimized for Large Datasets
In large datasets, operations like search, insert, and delete remain efficient due to the B-Tree's self-balancing nature. By storing multiple keys per node and limiting the height, they offer fast access times even with millions of records.
Optimized for Slower Secondary Storage
Traditional binary trees (BSTs, AVL, Red-Black) hold one key per node, leading to tall structures with many disk accesses — inefficient on slower storage like HDDs. B-Trees reduce height significantly by storing multiple keys and children per node. This design minimizes I/O operations, making B-Trees ideal for databases and disk-based indexing.
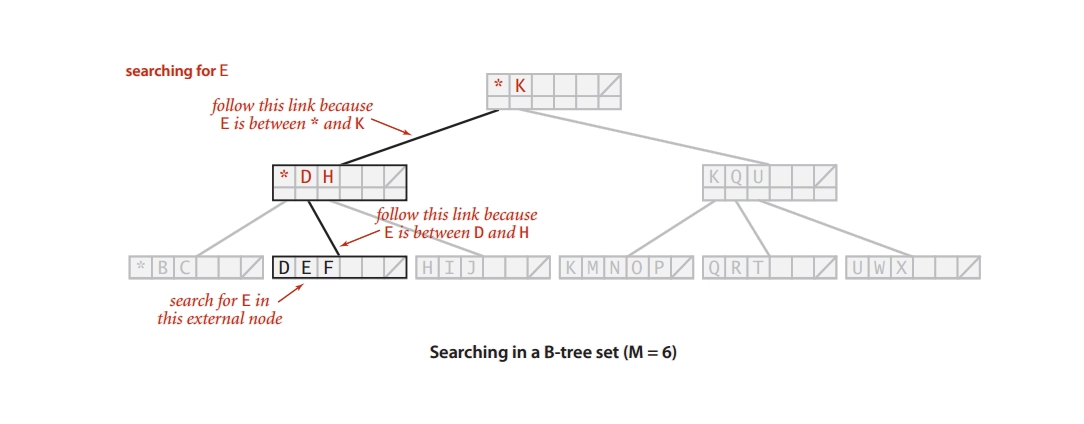
Searching an element
The generalized form of searching for an element in a Binary Search Tree is searching for an element in a B-tree. The steps below are followed.
Starting with the root node, compare k to the node's first key. Return the node and the index if k is the node's first key.
Return NULL if k.leaf = true (i.e. not found).
If k is the root node's initial key, recursively search the left child of this key.
Compare k to the node's next key if the current node contains more than one key and k is greater than the first key. If k is the following key, look for the key's left child (i.e., k lies between the first and the second keys). Otherwise, look for the key's right child.
Repeat steps 1–4 until you reach the leaf.
Example:
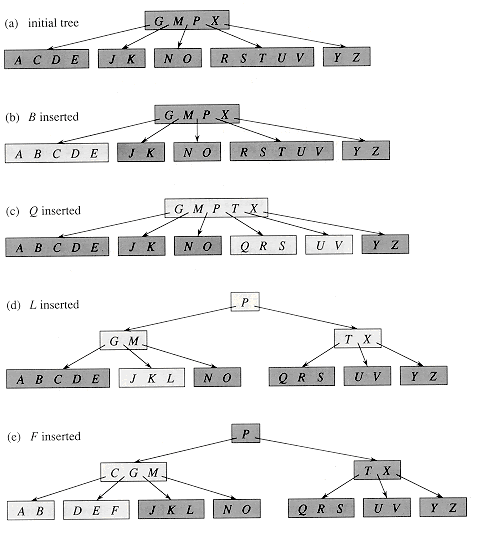
Inserting an element
At the leaf node level, insertions are made. The following algorithm must be followed to place an item into B Tree.
Navigate the B Tree until you find the suitable leaf node to insert the node.
If there are fewer than m-1 keys in the leaf node, insert the element in ascending order.
Else, it should proceed to the next step if the leaf node contains m-1 keys.
In the rising sequence of elements, add the new element.
In the middle, divide the node into two nodes.
The median element should be pushed up to its parent node.
If the parent node has the same m-1 number of keys as the child node, split it.
Example:
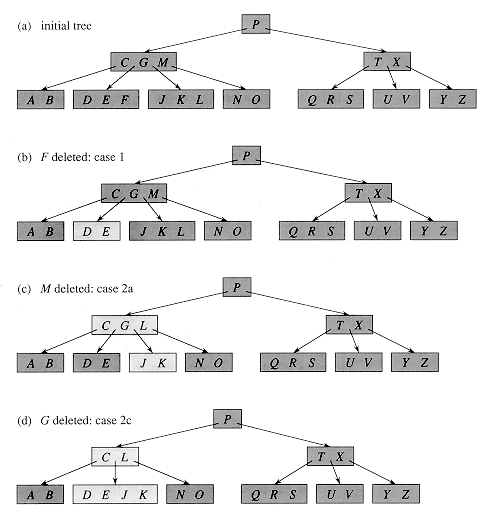
Deleting an element
At the leaf nodes, deletion is also conducted. It can be a leaf node or an inside node that must be destroyed. To delete a node from a B tree, use the following algorithm.
Find the position of the leaf node.
If the leaf node has more than m/2 keys, delete the required key from the node.
If the leaf node lacks m/2 keys, fill in the gaps with the eighth or left sibling element.
If the left sibling has more than m/2 elements, shift the intervening element down to the node where the key is deleted and push the largest element up to its parent.
If the right sibling has more than m/2 items, shift the intervening element down to the node where the key is deleted and push the smallest element up to the parent.
Create a new leaf node by merging two leaf nodes and the parent node's intervening element if neither sibling has more than m/2 elements.
If the parent has less than m/2 nodes, repeat the operation on the parent as well.
If the node to be destroyed is an internal node, its in-order successor or predecessor should be used instead. Because the successor or predecessor will always be on the leaf node, the operation will be similar to deleting the node from the leaf node.
Example:
Applications of B-Trees
Because accessing values held in a vast database saved on a disc is a very time-consuming activity, the B tree is used to index the data and enable fast access to the actual data stored on the discs.
In the worst situation, searching an unindexed and unsorted database with n key values takes O(n) time. In the worst-case scenario, if we use B Tree to index this database, it will be searched in O(log n) time.
A B-tree, in particular:
keeps keys sorted for sequential traversal and uses a hierarchical index to reduce disc reads
insertions and deletions are sped up by using partially filled blocks.
a recursive algorithm that keeps the index balanced
Efficient Operations: B-Trees provide O(log n) time complexity for search, insert, and delete operations, making them ideal for large datasets.
Self-Balancing Structure: They automatically balance themselves during insertions and deletions, ensuring consistent performance.
Optimized for Disk Access: B-Trees reduce the number of disk reads by storing multiple keys per node, making them suitable for databases and file systems.
Supports Concurrency: B-Trees can handle multiple read and write operations simultaneously, enhancing performance in multi-user environments.
These features make B-Trees ideal for scalable and reliable data storage.
Disadvantages of B-Trees
Complex Implementation: The logic for inserting, deleting, and rebalancing nodes is harder to implement than simpler trees like BSTs.
Inefficient for Small Datasets: B-Trees are overkill for small data sizes due to their overhead in node structure and memory usage.
Memory Overhead: Each node requires space for multiple keys and child pointers, increasing memory consumption.
Slower than Hashing for Simple Lookups: For exact key searches without range queries, hashing can offer faster performance.
Despite their power, B-Trees aren't always the best choice for simple or small-scale applications.
Frequently Asked Questions
What is B-tree?
A B-tree, is a tree data structure, that allows for logarithmic amortized searches, insertions, and removals while keeping data sorted.
Where is B-tree mainly used?
It's most typically found in database and file management systems.
What is the time-complexity of standard operations in B-tree?
The time-complexity of standard operations in B-tree is as follows:
Algorithm
Time Complexity
Searching
O(log n)
Inserting
O(log n)
Deleting
O(log n)
Conclusion
We learned that a B-tree is a tree data structure that keeps data sorted and permits logarithmic operations. We learned algorithms of standard operations for B-tree like searching, inserting, and deletion with examples, and then we learned applications of B-tree as well. Check out this problem - Largest BST In Binary Tree
































 9+ registered
9+ registered 

