Get a skill gap analysis, personalised roadmap, and AI-powered resume optimisation.
Introduction
In today's world of new technology, data plays a critical role in improving the nature of products and their reach to customers. Information is critical in assisting with this factor. Companies have begun to rely on assessments advanced by their internal processes, business operations, and customers to explore new chances for progress and success in the ever-changing international economy. Such insights present a huge, complex set of data that must be produced, maintained, examined, and manipulated. It is efficient to utilise a columnar Database if you have a lot of data and it's diverse. It's incredibly customizable.
Columnar Database
The data in a columnar, or column-oriented database, is stored in rows, unlike the relational databases where data in each row of a table is kept together. Although this may appear to be a minor distinction, it is the most fundamental feature of columnar databases. It's simple to add columns, and you can do so row by row, giving you a lot of flexibility, performance, and scalability. In data warehouses, where corporations transfer huge amounts of data from many sources for BI analysis, columnar databases are used. Because the column design puts data closer, column-oriented databases have better query performance. This minimises seek time. Column-oriented database table storage is critical for analytic query performance since it dramatically reduces total disc I/O requirements and the quantity of data you must load from the disc.
Data Storage
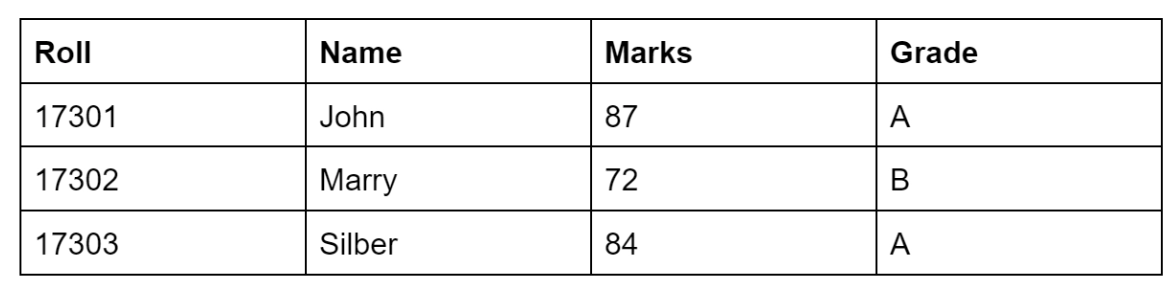
A relational database management system stores information in the form of a two-dimensional table with columns and rows. The data in columnar DBMS is stored column-wise, while in row-oriented DBMS, the data is stored row-wise. Consider the following table :
The data would be stored in a columnar DBMS like this:
17301,17302,17303;
John,Marry,Silber;
87,72,84;
A,B,A;
The data would be stored in a row-oriented DBMS like this:
The following are the significant characteristics of the Columnar Database:
Access time Columnar databases are faster than other database technologies at performing analytical queries. They can also conduct joins, which combine data from two tables in a relational database, quickly and efficiently. A join, despite being a standard method of merging data, can be wasteful and slow. A columnar database can swiftly connect any number of data sets and aggregate query results into a single output.
Compression Column data is of uniform type, there are various storage capacity optimization opportunities in column-oriented data that are not available in row-oriented data. A two-bit marker can be used to represent missing values and repeated values, which are common in clinical data. Columnar compression reduces disc space usage at the expense of retrieval efficiency. The higher the adjacent compression, the more difficult random access may become, as data may need to be decompressed before being read. As a result, column-oriented designs are sometimes supplemented with additional techniques to reduce the demand for compressed data access.
Self-indexing Columnar Databases uses self-indexing. Each of the index key's columns is indexed separately, which reduces the amount of data stored.
Limitations
Columnar Databases are simple to add columns, and you can do so row by row, giving you a lot of flexibility, performance, and scalability. Still, there are certain limitations to the Columnar Databases.
The data is loaded based on a trigger, which is a moment at which the data can be loaded more quickly. When another user adds data or when a specific time of day occurs. If the trigger is triggered, the database is loaded with the data up to the trigger point.
Column-oriented databases are also unsuitable for online transaction processing (OLTP) applications. They have superior concurrent processing and isolation features, and they utilise disc space more efficiently, row-oriented databases are better for OLTP applications.
Traditional databases, rather than columnar databases, are better for incremental data loading. Incremental data loading is a technique for loading a subset of data into a database instead of the entire database.
What is a Columnar Database? A columnar database is a type of database management system (DBMS) in which data is stored in columns rather than rows. A columnar database's goal is to reduce the time it takes to return a query by quickly writing and reading data to and from hard disc storage.
How do columnar databases minimise seek time? In a columnar database, the column design puts the data closer together, which has better query performance and minimises seek time.
What are the main characteristics of a Columnar Database? The main characteristics of a Columnar Database are Access time, Compression, and Self-indexing.
Conclusion
In this article, we have extensively discussed Columnar Database. The article explains the details of the Columnar Database, its characteristics, and its limitations. We hope that this blog has helped you enhance your knowledge regarding Columnar Database in big and if you would like to learn more, check out our articles on big data, Hadoop, MongoDB, Databases for development, and SQL vs. NoSQL. To practice and improve yourself in the interview, you can check out Top 100 SQL problems, Interview experience, Coding interview questions, and the Ultimate guide path for interviews. Do upvote our blog to help other ninjas grow.






























 9+ registered
9+ registered 

