



























Introduction
A NoSQL database, which stands for "non-SQL" or "nonrelational," is a database that allows for data storage and retrieval. This information is represented in ways other than tabular relationships found in relational databases. Such databases first appeared in the late 1960s, but it wasn't until the early twenty-first century that they were given the name NoSQL. NoSQL databases are increasingly being used in real-time web applications and big data analytics. Not only is SQL a term used to stress the fact that NoSQL systems may support SQL-like query languages.
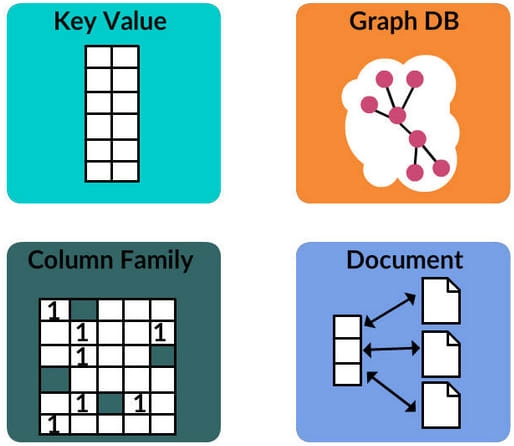
A NoSQL database offers design simplicity, horizontal scaling to clusters of servers, and greater control over availability. NoSQL databases employ different Data Structure than relational databases by default, allowing NoSQL to execute some tasks quicker.
The applicability of a NoSQL database is determined by the problem it is supposed to answer. NoSQL databases' data structures are sometimes seen to be more flexible than relational database tables.

Source: Giphy
Many NoSQL databases make trade-offs between consistency and availability, performance, and partition tolerance. The usage of low-level query languages, a lack of standardized interfaces, and large prior investments in relational databases are all barriers to the wider adoption of NoSQL storage. Although most NoSQL databases lack true ACID transactions (atomicity, consistency, isolation, and durability), a few databases, including MarkLogic, Aerospike, FairCom c-treeACE, Google Spanner (though technically a NewSQL database), Symas LMDB, and OrientDB, have made them a central part of their designs.
Most NoSQL databases have eventual consistency, which implies that changes to the database are propagated to all nodes over time. As a result, data searches may not immediately return updated data or may result in erroneous data being read, a condition known as stale reads. Lost writes and other data loss may occur in several NoSQL systems. Certain NoSQL systems include capabilities like write-ahead logging to prevent data loss. When doing distributed transaction processing across several databases, maintaining data consistency becomes much more complex.
Both NoSQL and relational databases struggle with this. Even today's relational databases don't provide cross-database referential integrity constraints. Few systems support both the X/Open XA standards and ACID transactions for distributed transactions.
You can also read about - Specialization and Generalization in DBMS and Checkpoint in DBMS.
Why is NoSQL required?
The concept of NoSQL databases gained traction among Internet behemoths such as Google, Facebook, Amazon, and others who deal with massive amounts of data. When you utilize RDBMS for large amounts of data, the system response time slows down.
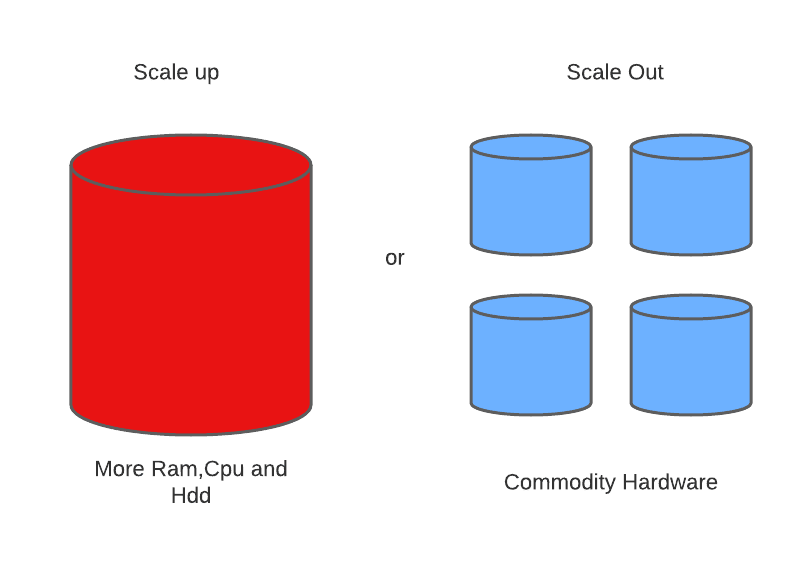
We could "scale up" our systems by updating our existing hardware to overcome this challenge. This procedure is costly.
When the load on the database grows, the option is to disperse it across numerous hosts. "Scaling out" is the term for this procedure. Because NoSQL databases aren't relational, they scale out better than relational databases because they're built for online applications.

 8+ registered
8+ registered 

