Do you think IIT Guwahati certified course can help you in your career?
Introduction
This article will teach you how to reset the index in Pandas DataFrame. We will go through all of the possibilities for resetting the row index of a basic and multi-level DataFrame.
The tabular structure in the Python pandas package is DataFrame. The label indicates each row and column. A row label is referred to as an index, but a column label is referred to as a column index/header. So let's start with the Reset Index in pandas Dataframe.
Reset Index in Pandas Dataframe
pandas.reset_index is a pandas function that is used to reset the index of a dataframe object to its default indexing (0 to the number of rows minus 1) or to reset a multi-level index. As a result, the original index is changed to a column.
Reset the DataFrame's index and use the default one instead. This function can delete one or more levels if the DataFrame has a MultiIndex.
Parameters
Level
This parameter only removes the levels specified by int, str, tuple, or list (default None). By default, remove all levels.
Drop
bool, (default False). You can use this to not include the previous index in the dataframe. It adds by default.
Inplace
This is used to do the modifications in the current dataframe. object. bool, (default False)
col_level
int or str, (default 0) If indeed the columns have numerous levels, this indicates the level the labels are to be put at. It is put into the first level by default (0).
col_fill
object, (default ”). If indeed the columns have many levels, this object controls how the additional levels are named. If there is none, the index name is repeated.
Returns
If inplace=True, DataFrame with the new index or None
Reset Index to Starts at 0
How do you Reset Index in Pandas DataFrame
Build a pandas DataFrame
We may generate a DataFrame from a CSV or dict file.
Modify the DataFrame
When we change the DataFrame, such as removing duplicates or sorting values, we obtain a new DataFrame with the original row index.
df = df.drop_duplicates()
You can also try this code with Online Python Compiler
To reset the index of the modified DataFrame, we may use DataFrame.reset index(). By default, it adds the current row index to DataFrame as a new column named 'index,' and it creates a new row index as a range of numbers beginning at 0.
df = df.reset_index()
You can also try this code with Online Python Compiler
By default, DataFrame.reset index() adds the current row index to DataFrame as a new column. We can use the drop parameter if we do not want to add the new column.
df = df.reset index(drop=True)
You can also try this code with Online Python Compiler
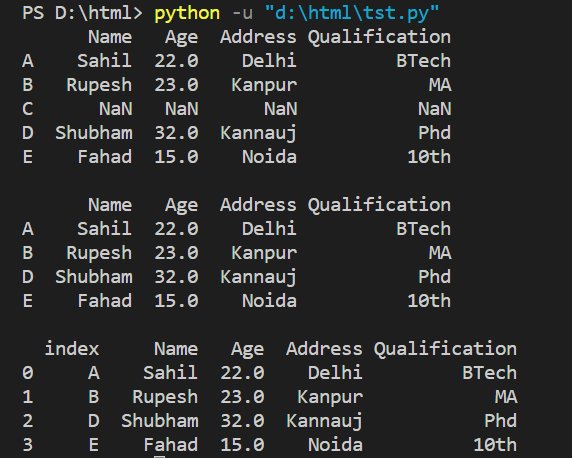
We have an employee DataFrame with row indexes 'A,' 'B,' and so on. It has a row with missing data that we wish to get rid of. Its row index remains the same after we eliminated it with the DataFrame.dropna() method. However, the index is no longer in the sequence.
In this situation, let's look at how to use DataFrame.reset_index() to reset the index to the series of integers.
# Import pandas package
import pandas as pd
import numpy as np
# Define a dictionary containing employee data
employee_data = {'Name':['Sahil', 'Rupesh', np.NaN, 'Shubham', 'Fahad'],
'Age':[22, 23, np.NaN, 32, 15],
'Address':['Delhi', 'Kanpur', np.NaN, 'Kannauj', 'Noida'],
'Qualification':['BTech', 'MA', np.NaN, 'Phd', '10th'] }
# create DataFrame from dict
employee_df = pd.DataFrame(employee_data, index=['A', 'B', 'C', 'D','E'])
print(employee_df, end='\n\n')
# drop NA
employee_df = employee_df.dropna()
print(employee_df, end='\n\n')
# reset index
employee_df = employee_df.reset_index()
print(employee_df)
You can also try this code with Online Python Compiler
Reset Index in Pandas Dataframe without New Column
By default, DataFrame.reset_index() adds the present row index to DataFrame as a new 'index' column. We can use the drop parameter if we do not want to add the new column.
If drop=True, the additional column of the present row index is not added to the DataFrame.
If drop=False, the default approach is to add a new column to the DataFrame based on the current row index.
Example:
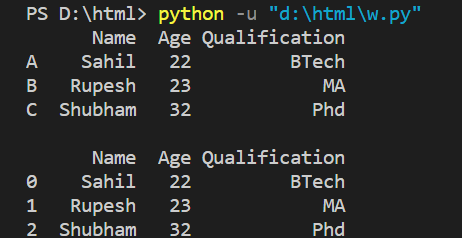
Let's look at how to reset the index without creating a new column.
import pandas as pd
employee_data = {'Name': ['Sahil', 'Rupesh', 'Shubham'], 'Age': [22, 23, 32], 'Qualification': ['BTech', 'MA', 'Phd']}
# create a DataFrame from a dict
employee_df = pd.DataFrame(employee_data, index=['A', 'B', 'C'])
print(employee_df, end='\n\n')
# Reset index without adding a new column
employee_df = employee_df.reset_index(drop=True)
print(employee_df)
You can also try this code with Online Python Compiler
Although the alteration is not in place, pandas built a new copy of DataFrame every time we performed the reset index operation in the preceding cases.
To reset the index in the existing DataFrame rather than making a copy, provide inplace=True.
If inplace=True, it modifies the existing DataFrame without returning anything.
If inplace=False, a new DataFrame with an updated index is created and returned.
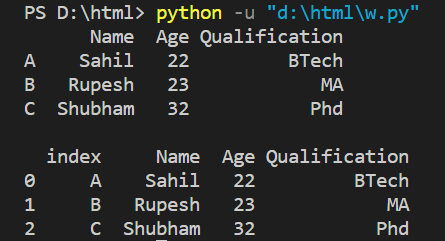
Example:
import pandas as pd
employee_data = {'Name': ['Sahil', 'Rupesh', 'Shubham'], 'Age': [22, 23, 32], 'Qualification': ['BTech', 'MA', 'Phd']}
# create a DataFrame from a dict
employee_df = pd.DataFrame(employee_data, index=['A', 'B', 'C'])
print(employee_df, end='\n\n')
# Reset index without adding a new column
employee_df.reset_index(inplace=True)
print(employee_df)
You can also try this code with Online Python Compiler
Assume we have a large dataset that has to be filtered. The original index remains after filtering the DataFrame. When we wish to reset the DataFrame's index so that the new index starts with 1, we may do it in two stages.
To reset the row index to 0, use DataFrame.reset_index().
Use the DataFrame's index parameter to re-assign the index by adding 1 to each row index of the resulting DataFrame.
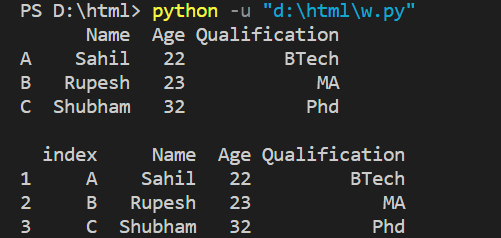
Example:
import pandas as pd
employee_data = {'Name': ['Sahil', 'Rupesh', 'Shubham'], 'Age': [22, 23, 32], 'Qualification': ['BTech', 'MA', 'Phd']}
# create a DataFrame from a dict
employee_df = pd.DataFrame(employee_data, index=['A', 'B', 'C'])
print(employee_df, end='\n\n')
# reset index
employee_df = employee_df.reset_index()
# add 1 to each index
employee_df.index = employee_df.index + 1
print(employee_df)
Output:
Frequently Asked Questions
What exactly is Pandas?
Pandas is a general-purpose Python toolkit that may be used for data analysis and manipulation, including aggregation, filtering, analyzing, and data processing. Pandas may be utilized in almost any process where you want to extract information from data using code.
What is Reset Index in Pandas Dataframe?
pandas.reset index is a pandas function used to reset a dataframe object's index to its default indexing (0 to the number of rows minus 1) or to reset a multi-level index. As a result, the original index has been converted to a column.
How to Reset index in Pandas Dataframe to start at 0?
First, Build a pandas DataFrame, then Modify the DataFrame, then Use the DataFrame.reset index() method, then Reset the index without adding any new columns. Lastly, In position index reset.
How to Reset index in pandas Dataframe without a new column?
DataFrame.reset_index() adds the present row index to DataFrame as a new 'index' column. We can use the drop parameter if we do not want to add the new column.
Conclusion
In this article, we learned about how to reset index in pandas dataframe and dry run with various examples to have a clear idea.
After reading about reset index in pandas dataframe, are you not feeling excited to read/explore more articles on the topic of Ruby? Don't worry; Coding Ninjas has you covered. To learn, see Multithreading in Python,Descriptors in Python, and BorderLayout in Java.

































 9+ registered
9+ registered 

