Do you think IIT Guwahati certified course can help you in your career?
Introduction
Can we imagine subjects like physics without mathematical tools? No, because without them we won’t be able to give solid conclusions and make concrete analysis on certain statements. Similarly, we cannot imagine Machine learning without statistical tools. It holds utmost importance especially in the field of Machine learning to understand the data and how various models perform .
Statistics plays a vital role in the field of Machine Learning to organise data, prepare, clean the data and analyse how a model is performing. The statistical discipline can be categorised into 2 types:
Descriptive statistics
This discipline of statistics deals with quantitatively analysing the dataset created from the information collected, by showing various plots, and graphs, etc. These visual tools help us get a bigger picture of how the data is and also how different models perform.
Inferential Statistics
This discipline of statistics deals with how we use different statistical techniques to manipulate the data and perform various tests to make inferences from them.
Use of Statistics on Data
Let’s see how we use statistics for handling different data types.
Handling Numerical Data
Numerical data includes values which are integers, floating values. For Handling Numerical data, if we see that the dataset contains continuous values or infinite values, we can apply concepts of binning/bucketisation.
Handling Categorical Data
Datasets can have parameters which have categorical values. We encode the categorical values to numerical values for training the dataset using different models.
Handling missing values
Missing values are very frequent in the datasets so we have to handle them accordingly. Therefore we use the concepts of statistics, i.e. Mean, Median, and Mode to perform imputations which handle the missing values. There are many techniques like undersampling, oversampling, using MICE imputations to handle missing values.
Use of Statistics to analyse the bias in the Data
It is one of the most important steps that one must not ignore which would later lead to biased results. At this juncture, Statistics comes to our rescue to give a proper mathematical analysis of how the dataset looks like. Following are ways how we can analyse our data:
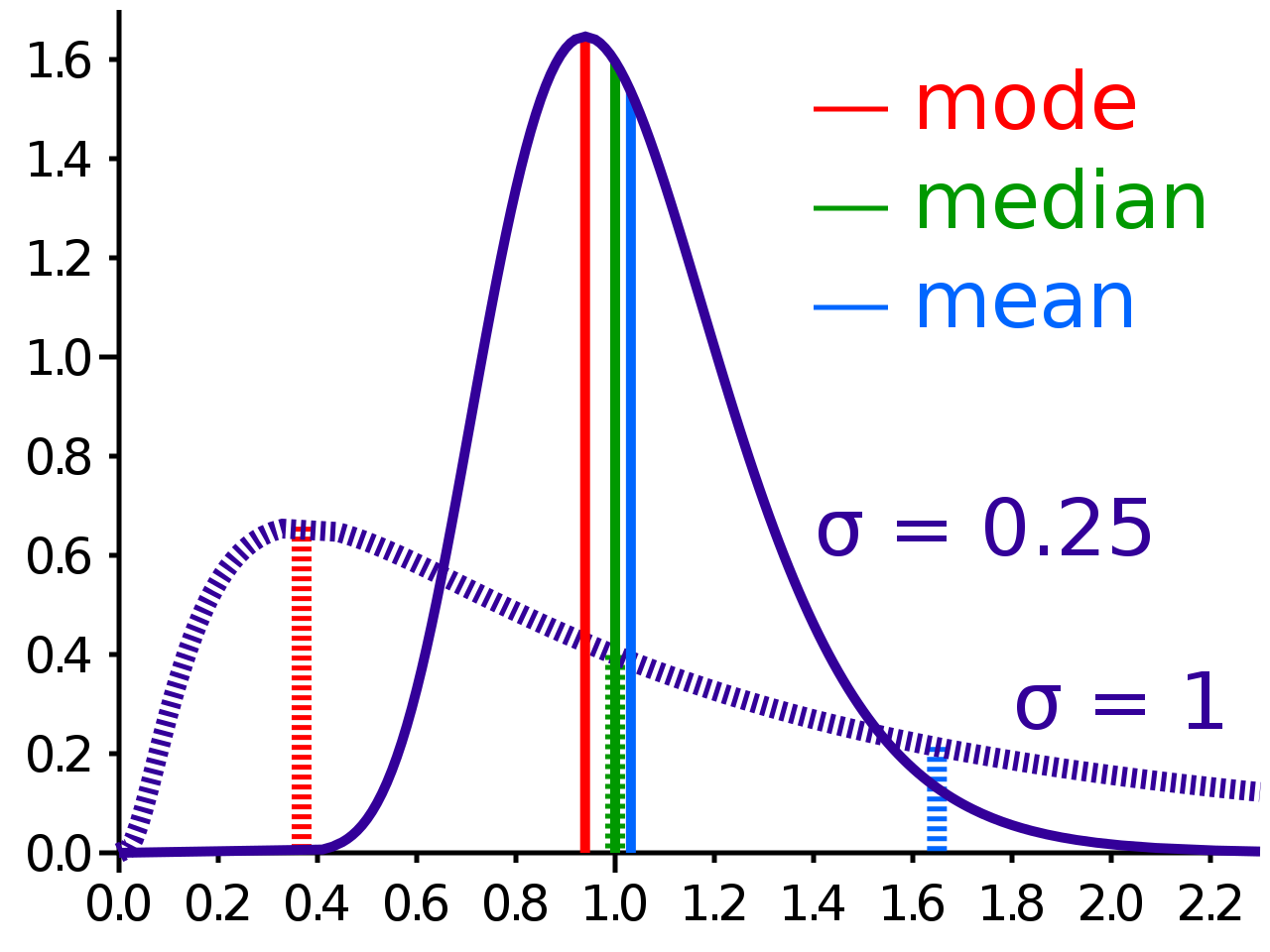
Mean
It is an informative statistical measure that gives us the average of the values of a particular dataset and to know how the whole dataset is spread.
Median
It is another informative statistical measure and we get it by sorting the data and the middle value is the median. This is informative because it’s resilient to outliers.
Mode
It is a great informative term that we should always try to know so that we can handle missing values in a dataset and it is the most frequently occurring value in the dataset.
Mean absolute deviation gives the absolute average of how the data deviates from the mean. This gives an idea of how the dataset is spread.
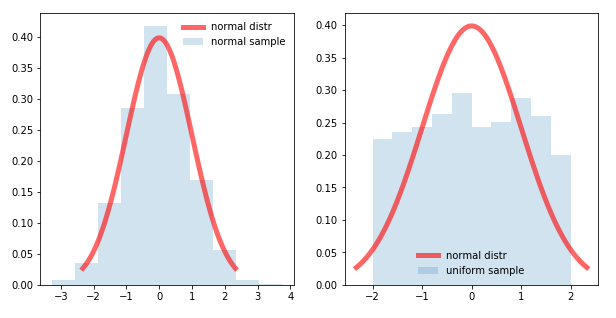
Normal distribution
This is one of the most important distributions we study in statistics. Basically Normal distribution is nothing but a bell curve which is followed by most of the real-life datasets. There are proofs for the same. Even if a particular distribution doesn’t follow the normal distribution we always try to transform them to a normal distribution as the models give great results in such cases.
There are 2 popular statistical methods by which we can know about the spread of the whole dataset. We use “Range” for finding what boundary does our data lie in. Secondly, we make use of “Percentiles” to know how much data falls under a particular percentile.
Why is statistics important for Machine Learning ? Statistics is a discipline that provides tools for analyzing any machine learning problem and the solution to its depth.
Why do we perform normalization? Normalization allows to use datasets which are very well suited for several machine learning models.
What is variance? Variance squared expectation of deviation of points from the mean and it tells us how spread the data is from the mean.
Key takeaways
This article gave a brief introduction of statistics with special emphasis on machine learning. It starts with why statistics plays a vital role in machine learning. We saw different types of data which we handle using statistical techniques and we can identify bias in the data.To dive deeper into machine learning, check out our industry-level courses on coding ninjas.
Live masterclass
Prompt Engineering: Must-have GenAI Skill for 30L+ Roles at Amazon
by Anubhav Sinha
16 Jul, 2026
12:30 PM
Using Netflix Data to Master Power BI
by Ashwin Goyal
13 Jul, 2026
12:30 PM
Top GenAI Skills to crack 30L+ CTC at Amazon & Google
by Sumit Shukla
14 Jul, 2026
11:30 AM
JioHotstar Sports Analytics using IPL Dataset
by Prerita Agarwal
15 Jul, 2026
12:30 PM
Prompt Engineering: Must-have GenAI Skill for 30L+ Roles at Amazon



























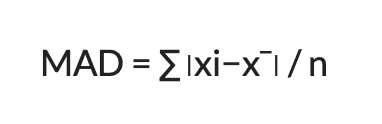

 8+ registered
8+ registered 

