Do you think IIT Guwahati certified course can help you in your career?
Introduction
Data structures and algorithms form the basic foundation of computer science. While data structures tell us how the data will be stored, algorithms provide us with an efficient way to store it.
In this article, we are going to discuss Trees which is one of the most important data structures. A tree in DSA is a non-linear Data Structure that allows us to store data hierarchically. We will understand its importance and different types of trees that exist.
Let us start this article- Introduction to Tree Data Structure by answering the following question:
What is Tree Data Structure?
A tree is a hierarchical Data structure made up of nodes. These nodes contain data and have zero or more child nodes, and each child node has one parent node (except for the root node, which has no parent).
Trees are commonly used to represent hierarchical relationships, such as the file system on a computer. The topmost node is called the root of the tree, and the bottommost nodes are called the leaves of the tree.
Let us take a look at the main keywords associated with a tree in DSA.
Root: The topmost node in the tree.
Child: A node that is directly connected to another node (its parent).
Parent: A node that has one or more child nodes.
Leaf: A node that has no children.
Sibling: Nodes that share the same parent.
Ancestor: A node higher in the tree and connected to the node by following the parent pointers.
Descendant: A node lower in the tree and connected to the node by following the child pointers.
Subtree: A tree that consists of a node and all its descendants.
Depth: The distance between a node and the root of the tree.
Height: The distance between a node and its furthest descendant leaf node.
Level: Count of edges on the path from a node to the root node.
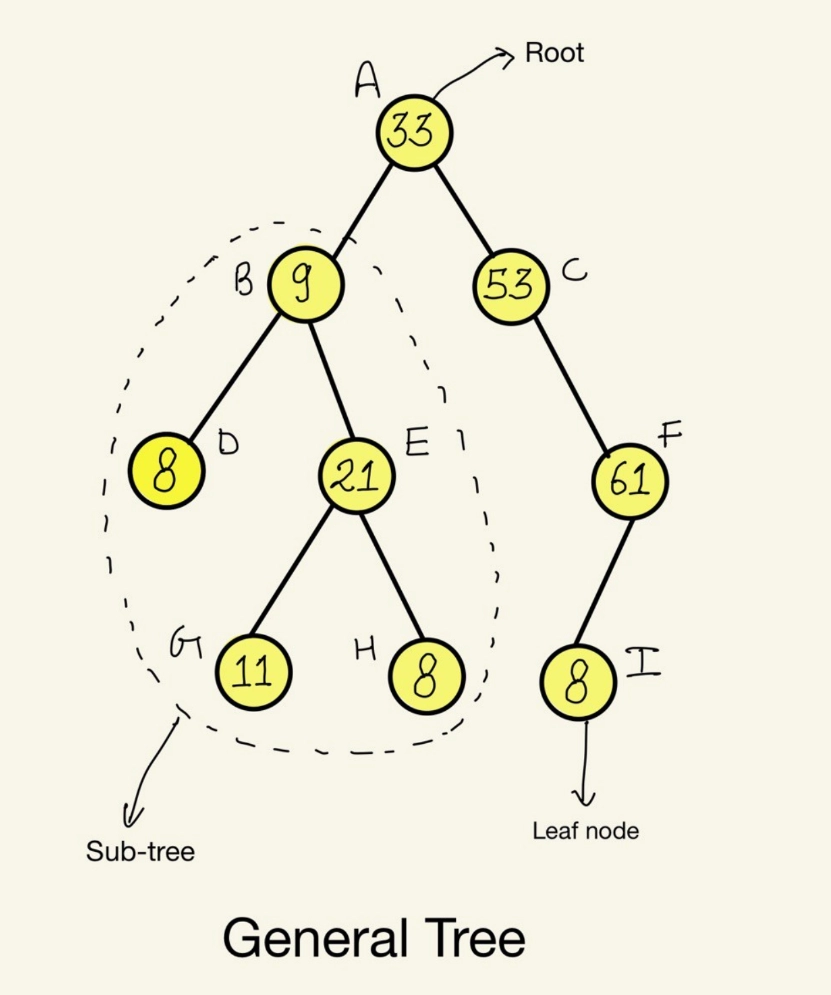
Here is a general tree consisting of 9 nodes. Node A is the root of the tree. Node C is the parent of Node F, and logically, F is the child of C. Nodes D,G,H,I are leaf nodes. Nodes D and E are siblings, since they have a common parent node B.
Node B is the ancestor of node H and H is the descendant of node B. The group of nodes B,D,E,G,H forms a sub tree.
The height of the node C is two, since its two edges away from its descendant leaf node. At the same time, the depth of the node C is one. Since it is just one edge away from the root node.
Note the total number of nodes and the total number of edges. You will find that the total number of edges is one less than the total number of nodes. This is simply because each edge ends with two nodes, one on each end.
Representation of Tree Data Structure
The tree data structure can be used to represent many data structures, such as:
Consider the following tree for reference:-
Linked list - In a linked list representation, each node in a tree contains a pointer to its parent node and a pointer to its first child node. The last child node in a linked list will have a pointer to NULL.
Array - In an array representation, each node in the tree is stored in an array. The array is indexed in such a way that the parent node of a node is always stored at index 2i, and the first child node of a node is always stored at index 2i + 1.
File - This represents the tree data structure stored in a file. This is a good representation of trees too large to fit in memory.
In-memory - The tree data structure is kept in memory using this representation. The most effective representation, however, also requires the most memory.
Basic Operation Of Tree Data Structure
The basic operations of tree data structures are :
Create: it creates a new tree data structure.
Insert: it inserts a new node into a tree data structure.
Search: it searches for a node in a tree data structure.
Traverse: it traverses a tree data structure, visiting each node in the tree.
Delete: it deletes a node from a tree data structure.
Characteristics of a Tree in Data Structure
A Tree in DSA has many interesting properties. These properties exist because of the unique structure of the trees.
A tree is a non-linear data structure with a hierarchical structure.
Each node in a tree has a unique parent node, except for the root node, which has no parent.
A tree can have any number of children, but each node can have only one parent.
The number of edges in a tree is always one less than the number of nodes. This means that a tree with n nodes has n-1 edges.
The height of a tree is the longest path from the root to a leaf node.
A tree can be traversed using various algorithms such as pre-order, in-order, post-order, and level-order traversal.
The number of leaf nodes in a tree is always greater than or equal to the number of non-leaf nodes.
Depth of a node: It is the distance of a node from the root of the tree. The root node is at depth 0.
Degree of a node: It is the number of children a node has. The leaf node has a degree of 0.
A tree has no loops, circuits, or self-loops.
Application of Tree In DSA
As mentioned above, trees are one of the essential data structures. They have several applications which help us to achieve simple and complex tasks.
File systems: Trees are used to organize and store files in a hierarchical structure.
Decision-making: Trees are used to model decision-making processes, where each node represents a decision point, and each branch represents a possible outcome.
Expression parsing: Trees are used to represent mathematical expressions and can be used to evaluate them.
Huffman coding: Trees are used to compress data by representing frequently occurring data with shorter codes and less frequent data with longer codes.
Graph algorithms: Many graph algorithms, such as depth-first search and breadth-first search, are implemented using tree data structures.
Artificial Intelligence: Decision Trees and Random Forest are used in machine learning and AI as models.
Database indexing: Trees are used to index and organize data in databases for faster retrieval.
Network routing protocols: Trees are used to organize and optimize communication networks.
Compiler Design: Syntax trees are used in compilers to represent the syntactic structure of a program.
Game AI: Game AI often uses tree data structures to model game states and possible moves in a game and to evaluate them using game-specific metrics.
Types of Tree Data Structures
A Tree in DSA can be classified into various categories based on the parent node relationships and structure. Here are the main types of a tree in DSA.
1. General Tree: The standard tree structure has no restrictions on the number of child nodes. This means that a parent node can have any number of children.
2. Binary Tree: Each node in a binary tree has at most two children, which are referred to as the left and right child.
3. Binary Search Tree (BST): A binary search tree where the value of each node is greater than or equal to the values of all the nodes in its left subtree and less than or equal to the values of all the nodes in its right subtree. AVL trees and Red Black trees are examples of BSTs.
4. Balanced Tree: A balanced tree is a tree where the height of every node's left and right subtrees differ by at most one. This ensures that the tree is well-balanced and search operations are efficient. Examples of balanced trees include AVL trees and Red-Black trees.
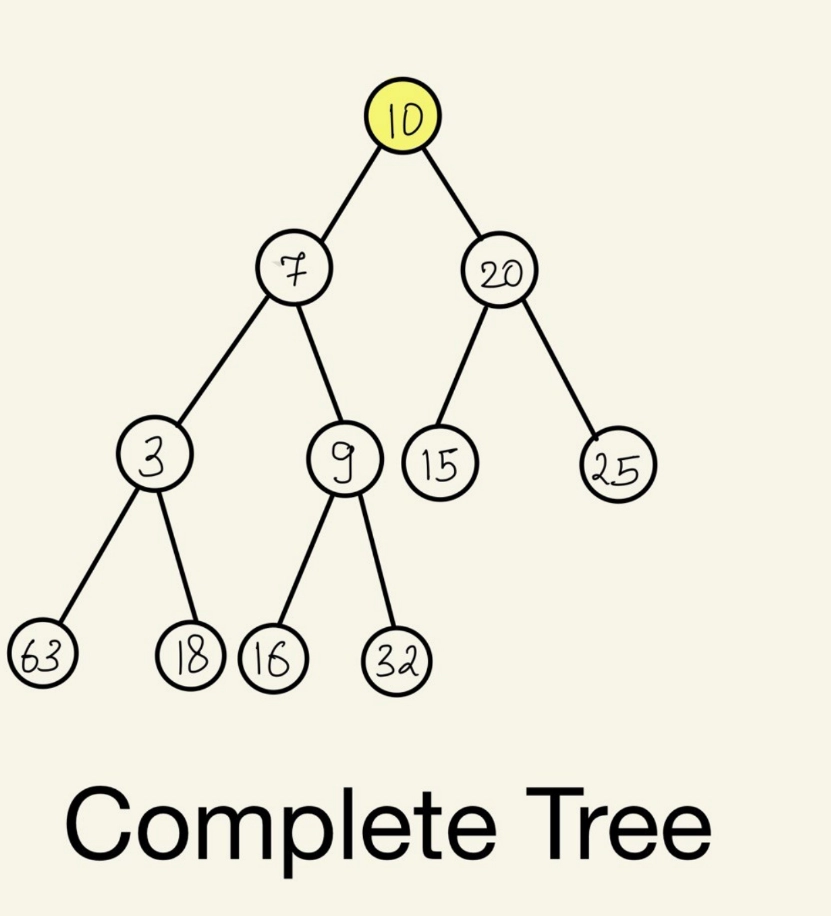
5. Complete Tree: A tree is a complete tree if all levels are completely filled except possibly the last level, and the last level has all keys as left as possible.
6. Full Tree: A tree is a full tree if every node has either 0 or 2 children.
7. Perfect Tree: A tree is perfect if it is both full and complete.
8. AVL Tree: An AVL Tree is a self-balancing binary search tree where the difference between the heights of the left and right subtrees of any node is at most 1.
9. Red-Black Tree: A self-balancing binary search tree where each node has an additional attribute, the color (red or black), to ensure that the tree remains balanced.
10. Heap: A tree-based data structure where each parent node is either greater than or equal to (in a max heap) or less than or equal to (in a min-heap) each of its children.
Implementation of Tree in DSA
Till now, we have understood the definition of a tree in DSA and its various properties. Let us now learn about its implementation.
Implementation
C++
C++
#include <bits/stdc++.h> using namespace std;
// Creating an edge between vertices x and y void makeEdge(int x, int y, vector<vector<int>>& adj) { adj[x].push_back(y); adj[y].push_back(x); }
// Printing the tree void printTree(int root, vector<vector<int>>& adj) { // creating a queue queue<int> q; // creating a visited array vector<int> vis(adj.size() , 0); q.push(root); vis[root] = 1;
// this while loop runs until q is empty while(!q.empty()) { int sz = q.size(); for(int i=0; i<sz; i++) { int node = q.front(); q.pop(); cout<<node<<" "; for(auto it : adj[node]) { if(vis[it] == 0) { vis[it] = 1; q.push(it); } } } cout<<endl; } } // Driver code int main() { // Number of nodes int N = 7, Root = 1; // Adjacency list to store the tree vector<vector<int> > adj(N + 1, vector<int>()); // Creating the tree makeEdge(1, 2, adj); makeEdge(1, 3, adj); makeEdge(2, 4, adj); makeEdge(2, 5, adj); makeEdge(3, 6, adj); makeEdge(3, 7, adj); printTree(1, adj);
return 0; }
You can also try this code with Online C++ Compiler
We first create an adjacency list of vectors to store the nodes. Each node in an adjacency list holds a vector of nodes that are connected to it.
The next part is linking the nodes together according to their relationship with each other. We create edges between respective nodes using the makeEdge function. After connecting all the edges, our tree is complete.
Here, we print the tree using the printTree function. We pass the tree's root to the function and print the tree using a queue. This method of printing the tree is called Breadth-First Search. You can also print a tree in DSA using Depth-First Search.
Complexity Analysis
Time Complexity:O(N), Since we traverse every node exactly once, the time complexity is proportional to the number of nodes.
Space Complexity:O(N), Here N is the number of nodes in the tree.
Frequently Asked Questions
Why is Tree called a non-linear data structure?
A tree is called a non-linear data structure because it does not store data in a linear sequence like an array or a linked list. Instead, it organizes data hierarchically, with a parent-child relationship between nodes.
What is the difference between a binary tree and a binary search tree?
A binary tree is a tree where each node has at most two children. On the other hand, a binary search tree is a binary tree where the value of each node is greater than or equal to the values of all the nodes in its left subtree and less than or equal to the values of all the nodes in its right subtree.
What is the time complexity of searching for an element in a binary search tree?
The time complexity of searching for an element in a binary search tree is O(h), where h is the height of the tree. In the best case, the height of the tree is log(n) and the time complexity is O(log(n)), but in the worst case, the height of the tree is n and the time complexity is O(n).
Why trees are used in DSA?
Trees in DSA are used because they organize data like family trees, simplifying tasks. They help find, insert, delete, and sort data efficiently, which is important for various algorithms and problem-solving.
How many trees are there in DSA?
There are three types of trees in DSA: binary, ternary and generic(n-ary) tree.
Why is a Tree a Non-Linear Data Structure?
A tree is non-linear because its elements are arranged hierarchically, not sequentially. It follows a parent-child structure, allowing efficient data organization.
Conclusion
In this article, we discussed Tree in DSA. We understood the need to use the tree data structure as well as the characteristics of a tree. A simple implementation of this data structure followed.
We hope you enjoyed reading this article. If you wish to learn more about trees, you can refer to the following blogs.




































 8+ registered
8+ registered 

