Get a skill gap analysis, personalised roadmap, and AI-powered resume optimisation.
Introduction
Hello Ninjas! In this era of big data, extracting valuable insights and making accurate predictions have become crucial for businesses and researchers. That’s where Weka comes into play. So, today we will learn about Weka, an open-source software. We will also explore its use in data mining and machine learning.
Let’s start with the introduction to Weka.
Introduction to Weka
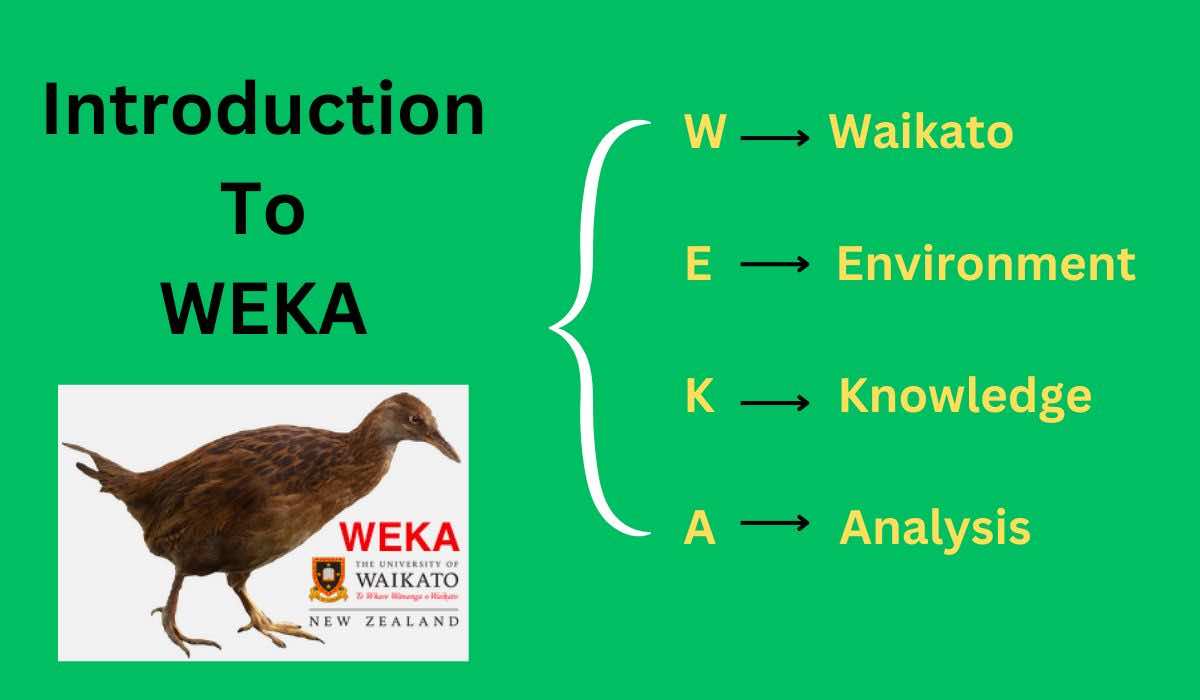
Weka stands for Waikato Environment for Knowledge Analysis. It is open-source software (i.e., we can access its source code or change it for free) developed in Java language. It was developed at the University of Waikato in New Zealand. The initial versions of Weka were written in C; around 1999 java based Weka was released.
Weka is a data mining software that uses a collection of machine learning and deep learning algorithms. It is a data mining workbench containing a collection of visualization tools and algorithms for data analysis and predictive modeling. It supports several data mining tasks like data preprocessing, regression, classification, clustering, and feature selection. We can call the algorithm directly to the data set or call from our code.
Weka Installation
Weka can be easily installed on Windows, Mac, or Linux. Following are the simple steps for the installation of Weka:
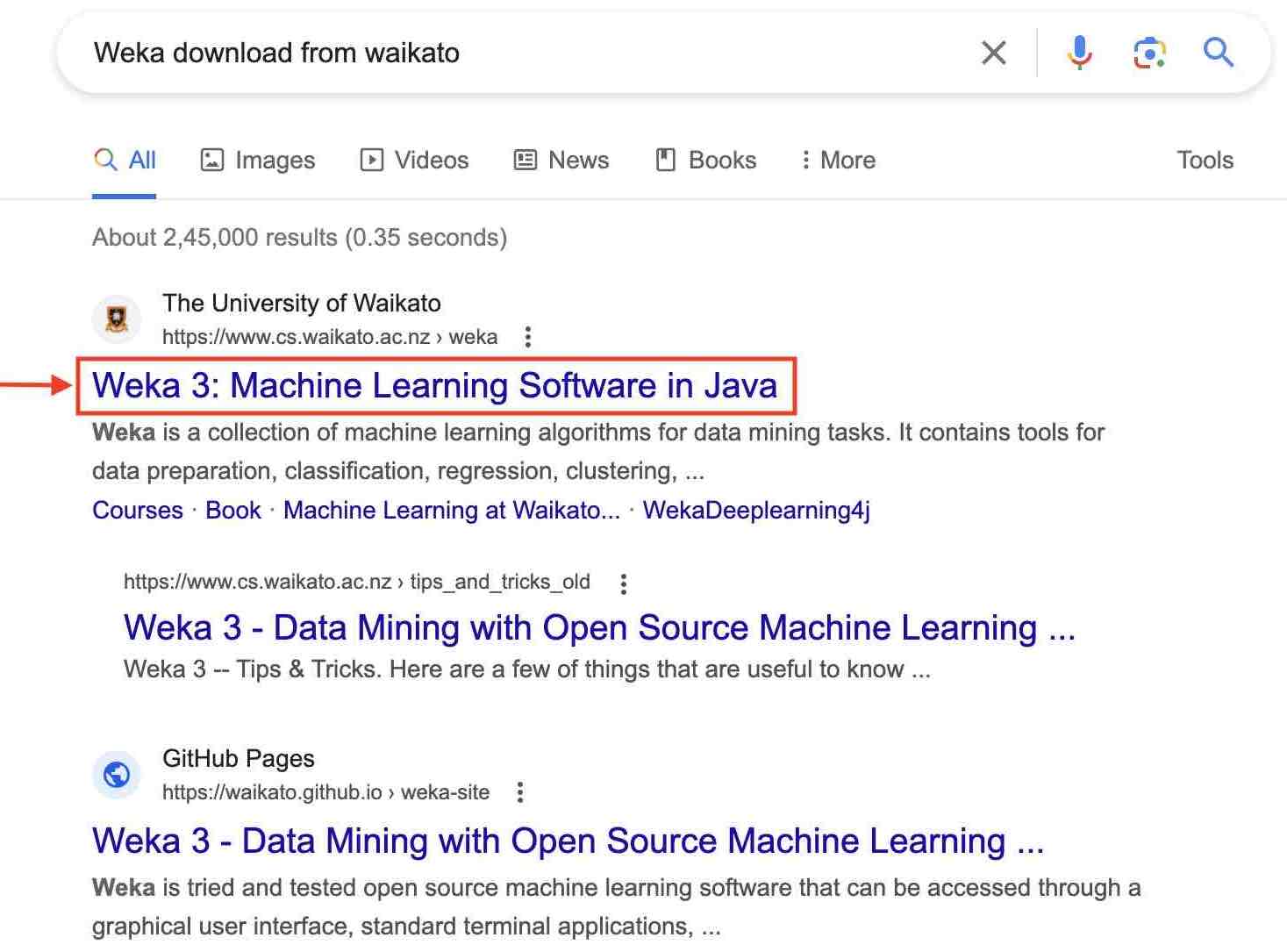
1. Search “Weka download from Waikato” on any search engine you prefer.
2. Select the first website to proceed toward the “Getting Started” section, and hit download.
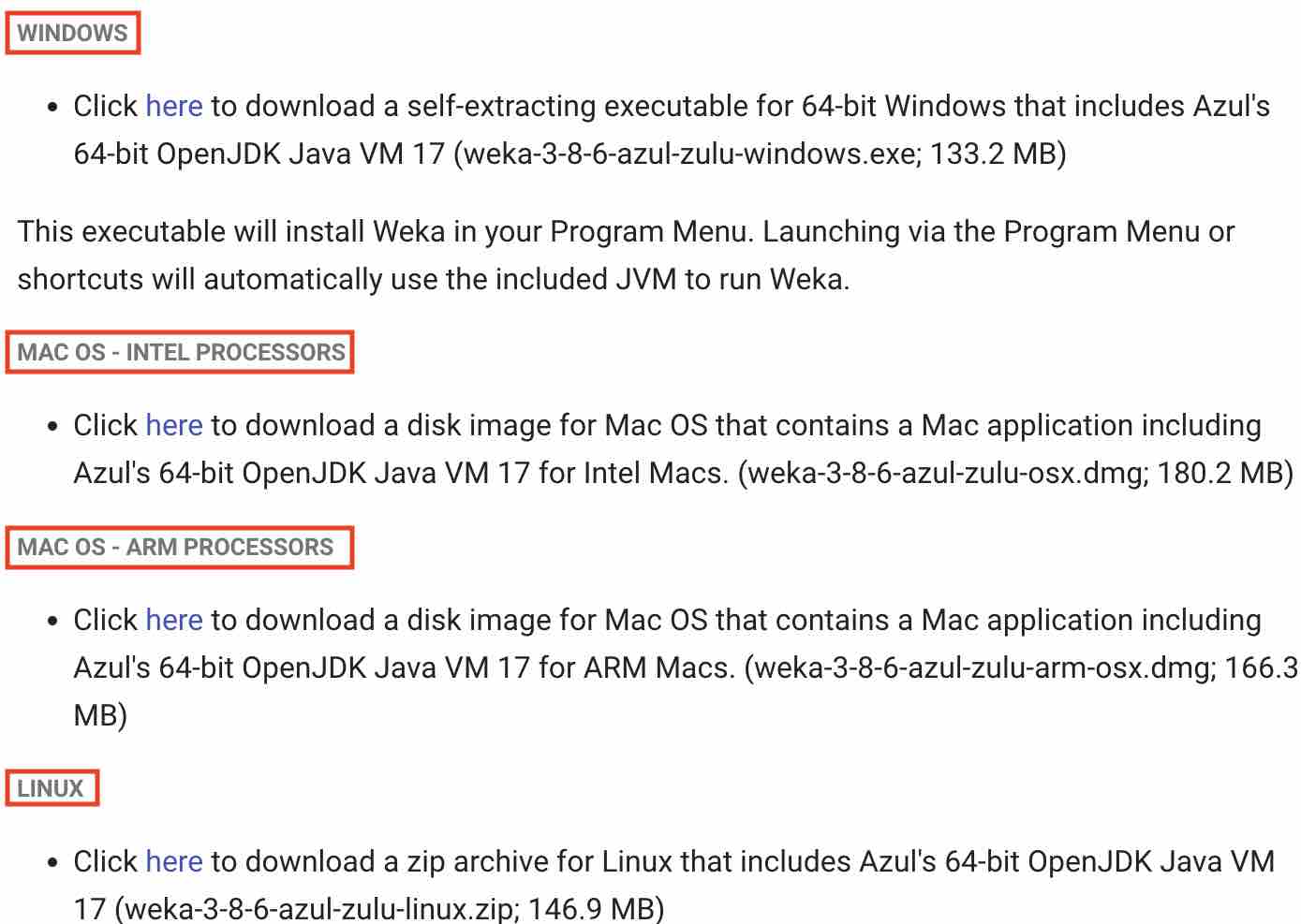
4. Download by clicking the suitable link for your system.
5. After downloading Weka, you will be redirected to an interface that looks as follows:
Weka Basics
You can notice on the right side the various sections, namely Explorer, Experimenter, Knowledge Flow, Workbench, and Simple CLI. Let’s look at these terms:
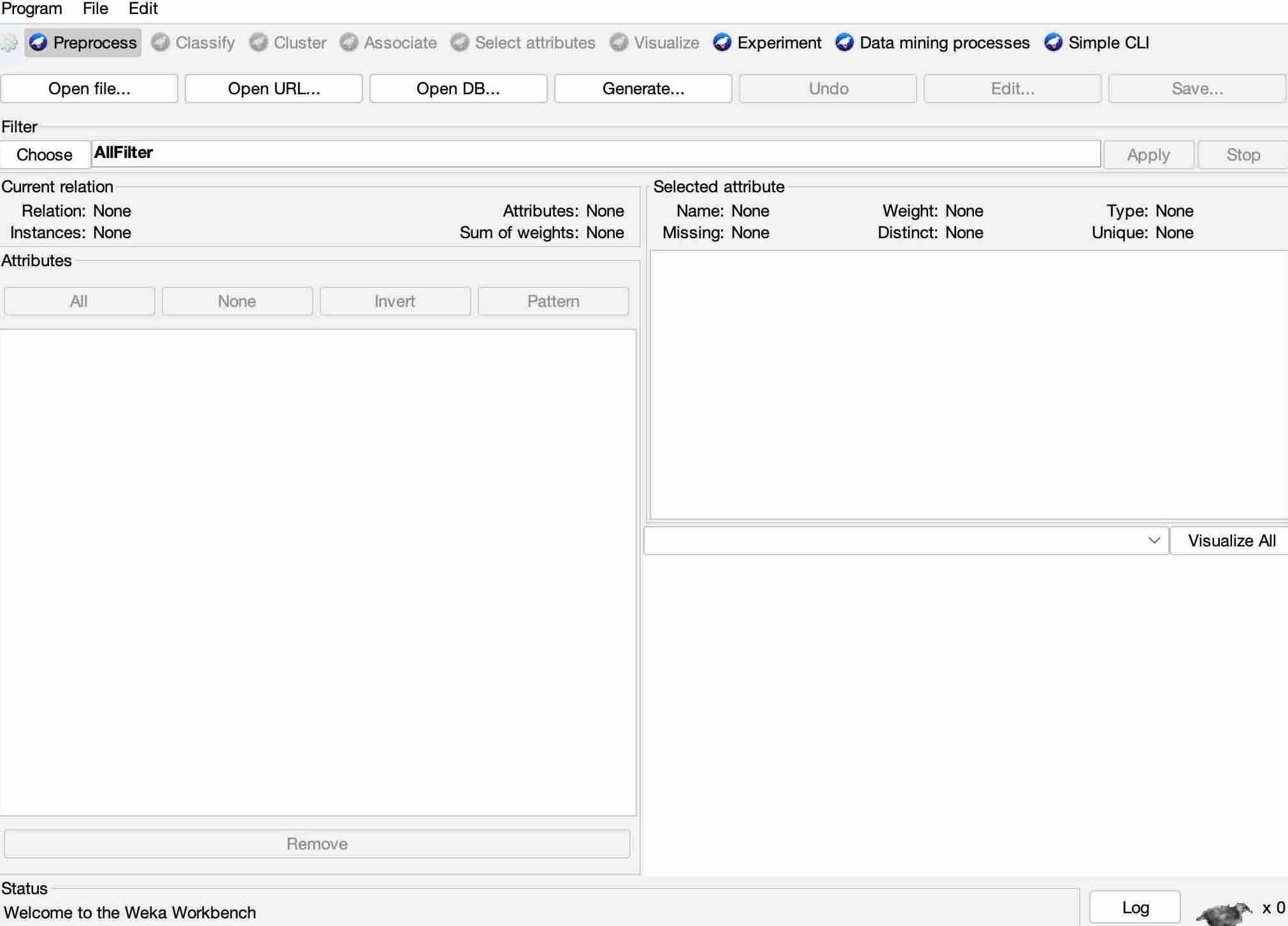
Explorer
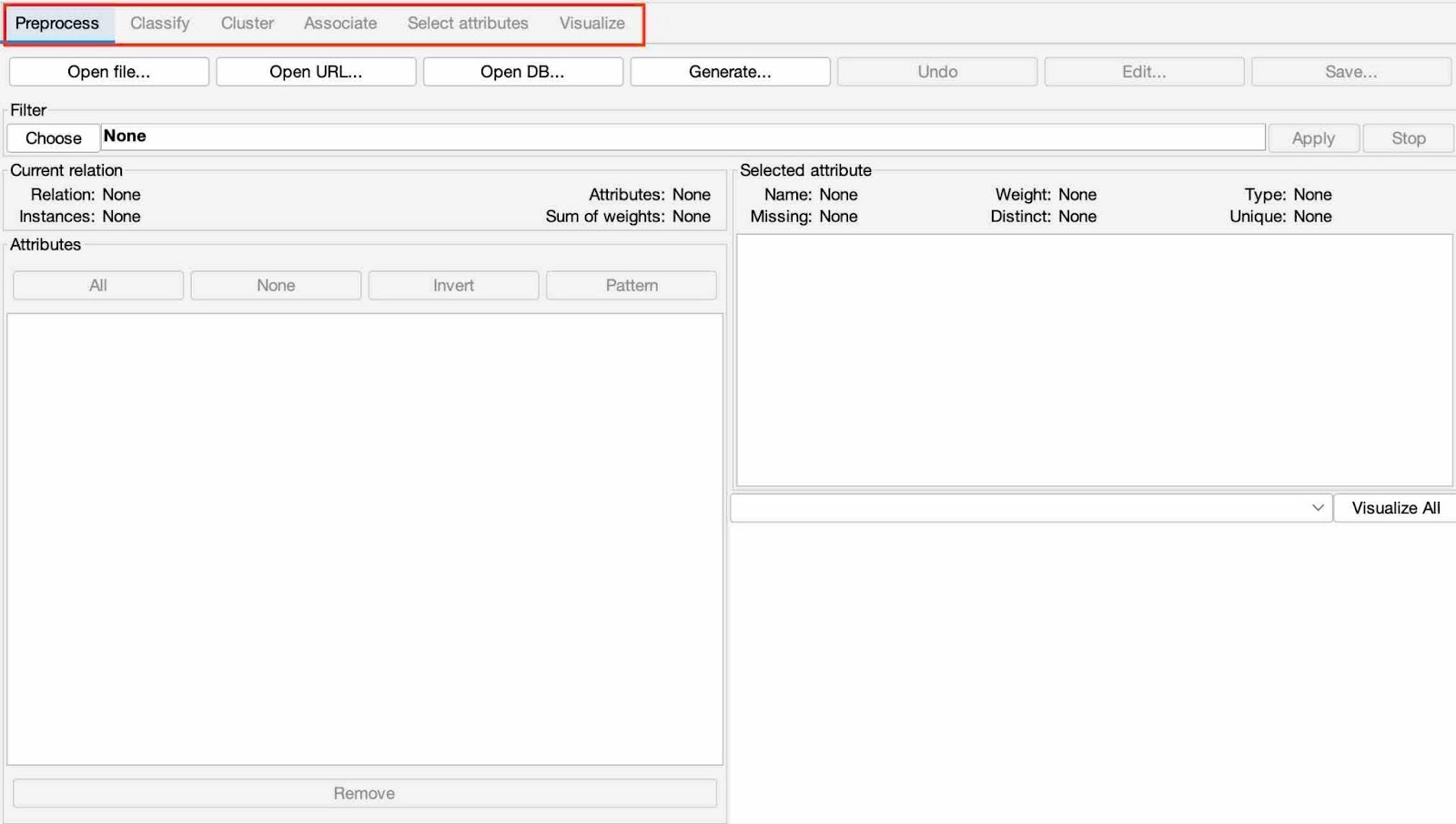
It is the essential part because it is the central panel where most data mining tasks are performed. There are a series of tabs across the top as:
Let’s look at each one of them:
PreProcessor
This is where we import the data and can include or exclude attributes, i.e., modify the data.
Underneath this tab, there is a list of buttons. These are the ways we can get data in. So we can open a file that we have on our computer, import from a URL, open a database or generate a data file.
Visualise
Here we can see a plot matrix, i.e., a 2-D representation of data.
Classify
This is where we can test out classifiers on our data. We can choose the algorithm we want to run here. Also, there are a few different ways that we can break up the data to test it.
Clusters
A Cluster is used to group data in the form of clusters. Weka has several clustering algorithms such as FilteredClusterer, HierarchicalClusterer, SimpleKMeans, etc.
Associate
It uses the apriori algorithm to mine out the data. This algorithm is majorly used for pattern mining.
Select Attributes
Here, the attributes are selected such as ClassifierSunsetEval, Principal Component, etc.
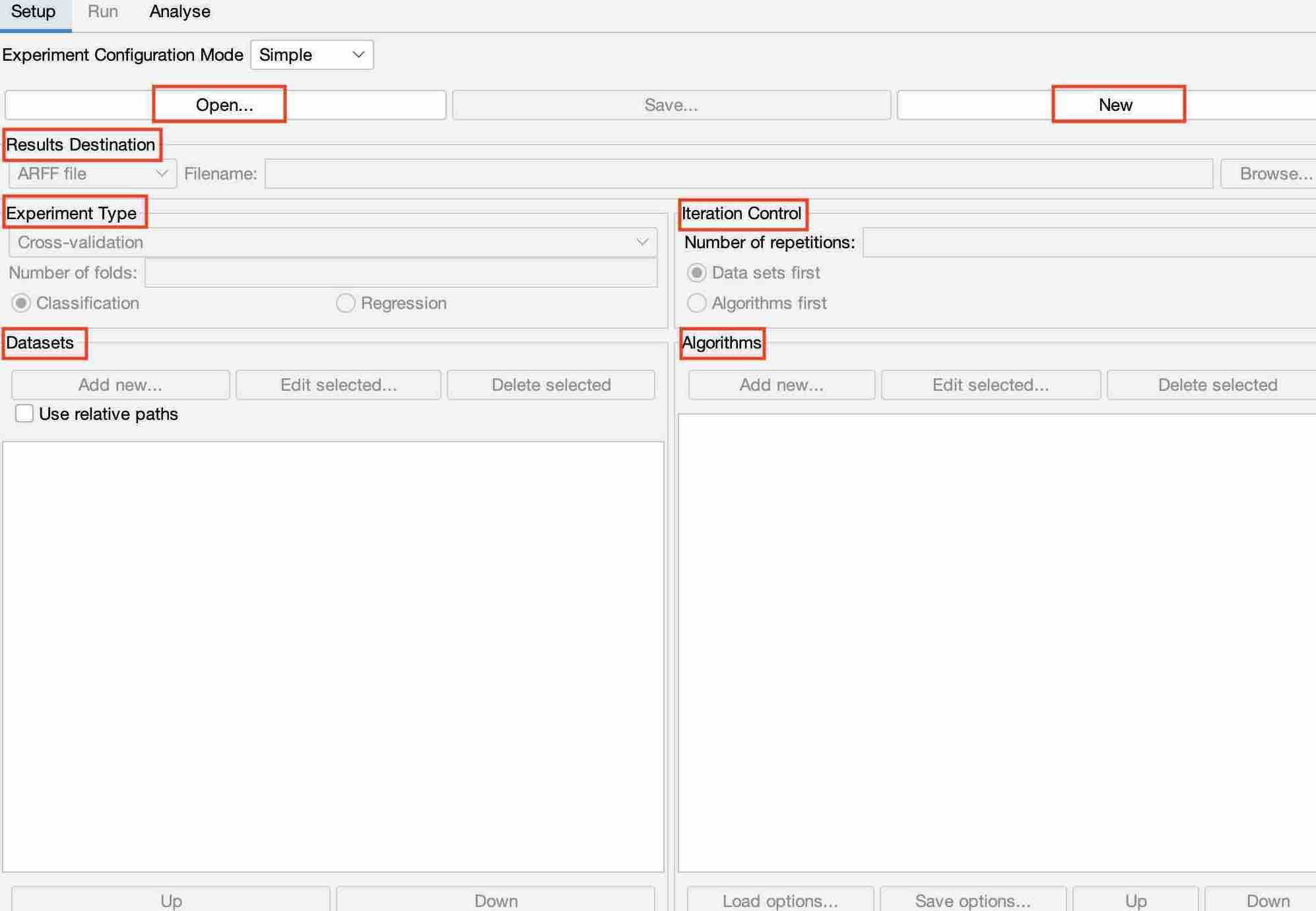
Experimenter
It helps to create, run, modify, and analyze experiments in a more convenient manner and then processes the schemes individually. This is the environment of Weka Experimenter:
Let’s look at these marked terms:
New / Open
We can set up a new experiment or open an already-existing experiment using these buttons respectively.
Results Destination
We can save the results of an experiment and select the file from ARFF, JDFC, and CSV files.
Experiment Type
We can choose from cross-validation and train/test percentage split. Further, the user can choose between classifier or regression, depending upon the type of dataset and classifier used.
DataSet
By selecting the “Add New” Button, we can select the dataset and use a relative path for this.
Algorithm
Here, we can add multiple classifiers in order to check their performance.
Iteration
The default number of folds/ iterations is set to 10.
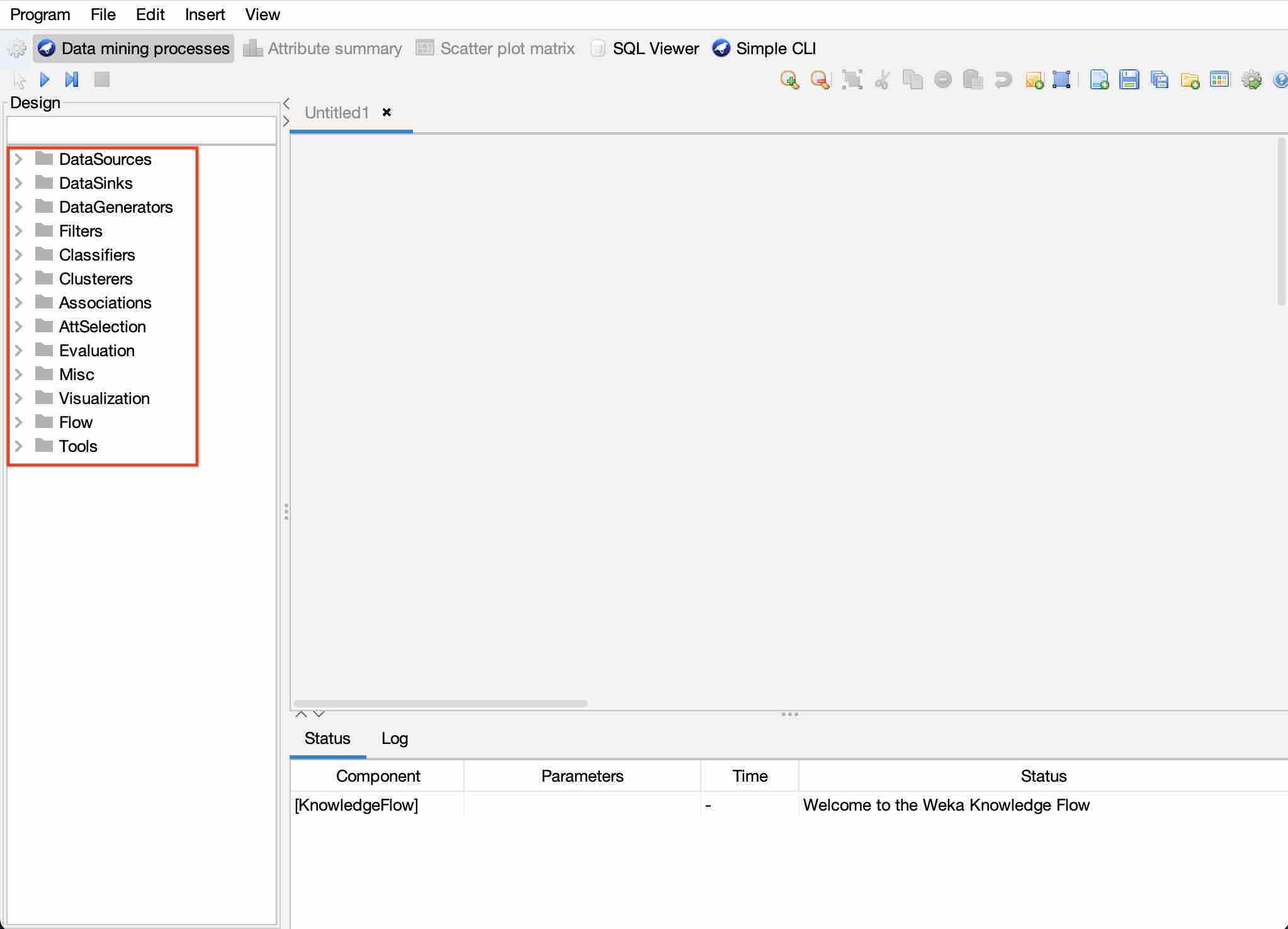
Knowledge Flow
This panel provides an interface to drag and drop components, connect them to form a knowledge flow and analyze the data and results.
The interface looks like this:
The data sources help to load files. The other components are: Datasavers, Filters, Classifiers, Clusters, Evaluation, and Visualization.
Simple CLI
This panel provides the command line interface to the user for different operations on the dataset. The interface of Simple CLI looks like:
In this, we write the command line starting with “java” followed by the arguments and path of the input file for which we want to perform the classification.
WorkBench
The Weka workbench contains all the GUI in a single interface. The workbench interface looks like:
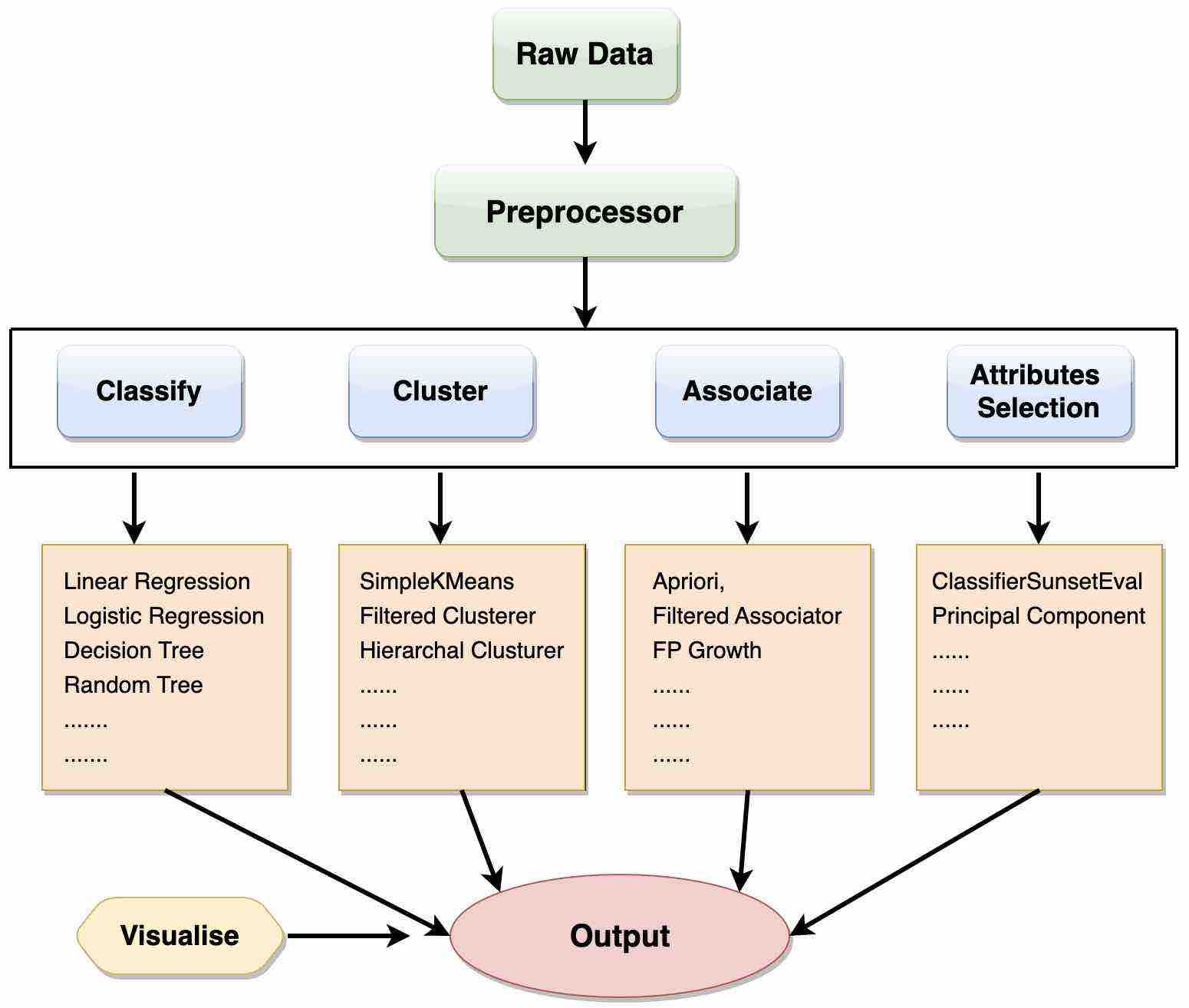
Weka for Machine Learning
The following are the stages that make big data suitable for machine learning:
Let’s learn about these stages one by one:
We start with raw data and collect it. This raw data may contain several null or irrelevant values.
The data is then cleaned with the help of data preprocessing tools existing in Weka. After cleansing, the pre-processed data is stored in local storage so that we can apply the machine learning algorithms.
Depending on the type of ML model we are trying to develop, we select one of the options, such as Classifier, Cluster, or Associate.
We take the help of the attribute section, which helps in reducing the dataset by automatically selecting the required features. Under each category, Weka provides the implementation of several algorithms. We can select any algorithm of our choice, set the desired parameters, and run it on our dataset. Then Weka returns the outputs of the model preprocessing.
It also provides a visualization tool to inspect the data. So various models can be applied to the same dataset.
Hence we can compare the output of different models and select the best that meets the purpose.
Weka for Data Mining
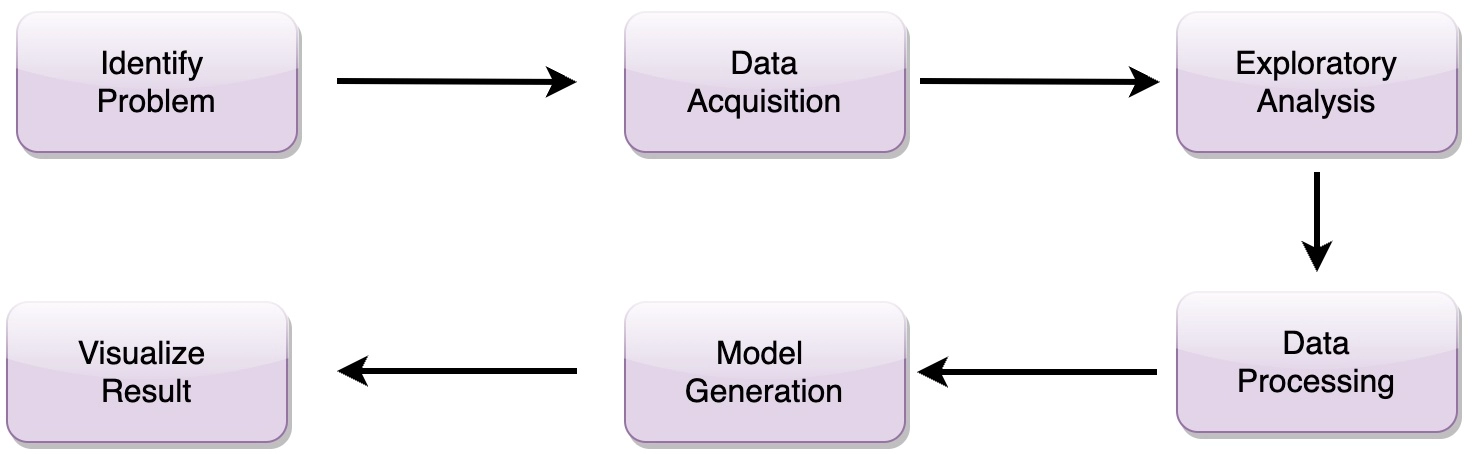
The following are the stages that make data suitable for data mining:
Let’s learn about these stages one by one:
Data analysis starts with Business Problem identification. In this stage, the data scientist should understand the problem statement and domain knowledge of the problem.
Then comes the data acquisition step, wherein all the data sources related to the problem statement are identified. Weka can easily import data from various sources.
The data scientist tries to analyze the key features using graphical plots or quantitative analysis.
Data processing is considered one of the most essential steps of data mining. Weka can efficiently handle the missing data and normalize data also.
The Weka allows the selection of a model from its extensive collection of algorithms. Model training and model evaluation are also a part of this phase.
Finally, Weka visualizes the result through graphs or any other tool and stores the chart for future use.
Features of Weka
The following are the features of Weka:
Weka supports both superfast and non-superfast machine learning algorithms. We can use 100+ regression and classification algorithms and 20+ clustering algorithms in data analysis.
Weka is a well-defined pre-processing tool. We can form our dataset and handle missing values very easily using Weka.
Weka has a well-managed import-export system for external files. The primary support file system is ARFF, JDFC, and CSV Files.
It contains a rich set of packages that allows us to solve various problems.
We can also integrate Weka into Java and Java-based environments.
It is free software licensed under the GNU general public license.
As it is entirely Java-based, it is platform-independent. Therefore it can run on Windows, Mac, or Linux.
Compared to other data analysis tools, say Pythor or R, Weka is much easier to use.
Applications of Weka
The major application domains of Weka are:
Customers are to be segregated in market analysis, which can be done using cluster analysis in Weka.
Any financial prediction can be made by Weka easily by regression analysis.
Fraud detection can also be done using the Weka tool.
We can predict cancer or many other diseases using predictive algorithms.
Accuracy is crucial in engineering; machine learning algorithms can detect, predict and rectify processes.
Another central area of application is corporate surveillance, as we can predict the data from the data stream.
We can also use Weka for scientific research.
Frequently Asked Questions
Is Weka suitable for beginners in data mining and machine learning?
Yes, Weka is beginner-friendly and has a user-friendly interface.
Can Weka be used for real-time data analysis?
Weka is not the ideal choice for real-time data analysis but can be used for real-time applications by integrating it with other frameworks or tools.
Can users add their algorithm to Weka?
Yes, users can extend its functionality by implementing their algorithms.
Is Weka suitable for handling large data sets?
Yes, it can handle data sets of various sizes, but its performance may be impacted.
Can Weka be integrated with existing users’ Java-based applications?
Yes, Weka provides APIs and libraries that allow seamless integration with Java-based applications.
Conclusion
In conclusion, we have learned about the introduction to Weka, i.e., is an open-source software designed for data mining and machine learning. We discovered how to install Weka and explored its various components. We learned how Weka could empower users to visualize and analyze model data efficiently, making it a valuable tool.
To learn more about Data Mining, we recommend reading the following articles:

































 8+ registered
8+ registered 

