Do you think IIT Guwahati certified course can help you in your career?
Introduction
Iterative Deepening Search (IDS) and Iterative Deepening Depth First Search (IDDFS) are graph traversal algorithms used in artificial intelligence and pathfinding. They combine the benefits of Depth-first search (DFS) and Breadth-first search (BFS) by gradually increasing the depth limit. This allows for finding the optimal solution while avoiding the memory limitations of BFS and the potential incompleteness of DFS with infinite depth. In this article, we will see both of the algorithms and how they are different by showing proper code implementation in different languages.
The depth-first search (DFS) algorithm operates with the first node of the Graph and moves to go deeper and deeper until we find the target node or node with no children. The algorithm then reverses its path from the dead end to the most recent node that has not yet been fully explored. Stack is the data structure that is used in DFS.
The method is similar to the BFS algorithm. The edges that lead to an unvisited node in DFS are identified as discovery edges, while the edges that lead to an already visited node are known as block edges.
Breadth First Search Algorithm
The breadth-first search algorithm is a graph traversal algorithm that begins its traversal of the Graph at the root node and explores all of the nodes in its path. Then it chooses the closest node and explores all new nodes. The algorithm repeats the process for each nearest node until it reaches the goal. The breadth-first search algorithm is shown below.
The algorithm begins by inspecting node A and all of its neighbors. The neighbors of A's nearest node are explored in the following step, and the process continues in subsequent steps. The algorithm investigates all the nodes' neighbors and ensures that each node is visited exactly once and that no node is visited twice.
To learn more about BFS, try to get a better idea by solving this BFS problem.
Let's move to the main topic, i.e., Iterative Deepening Search(IDS)
Iterative Deepening Search
The iterative Deepening Search (IDS) algorithm is an iterative graph searching strategy that uses much less memory in each iteration while helping from the completeness of the Breadth-First Search (BFS) strategy (similar to Depth-First Search).
IDS acquires the desired validity by imposing a depth limit on DFS, which reduces the possibility of becoming stuck in an infinite or very long branch. It traverses each node's branch from left to right until it reaches the required depth. After that, IDS returns to the root node and investigates a branch similar to DFS.
Let’s use the DFS example again to see how IDS works
Pictorial Representation
In this Graph, we use the stack data structure S to keep track of the nodes we've visited.
Assume node 'A' is the source node.
Assume that node 'D' is the solution node.
S2 is now empty. Since no solution has been found and the maximum depth has not been reached, set the depth limit L to 1 and restart the search from the beginning.
S2:
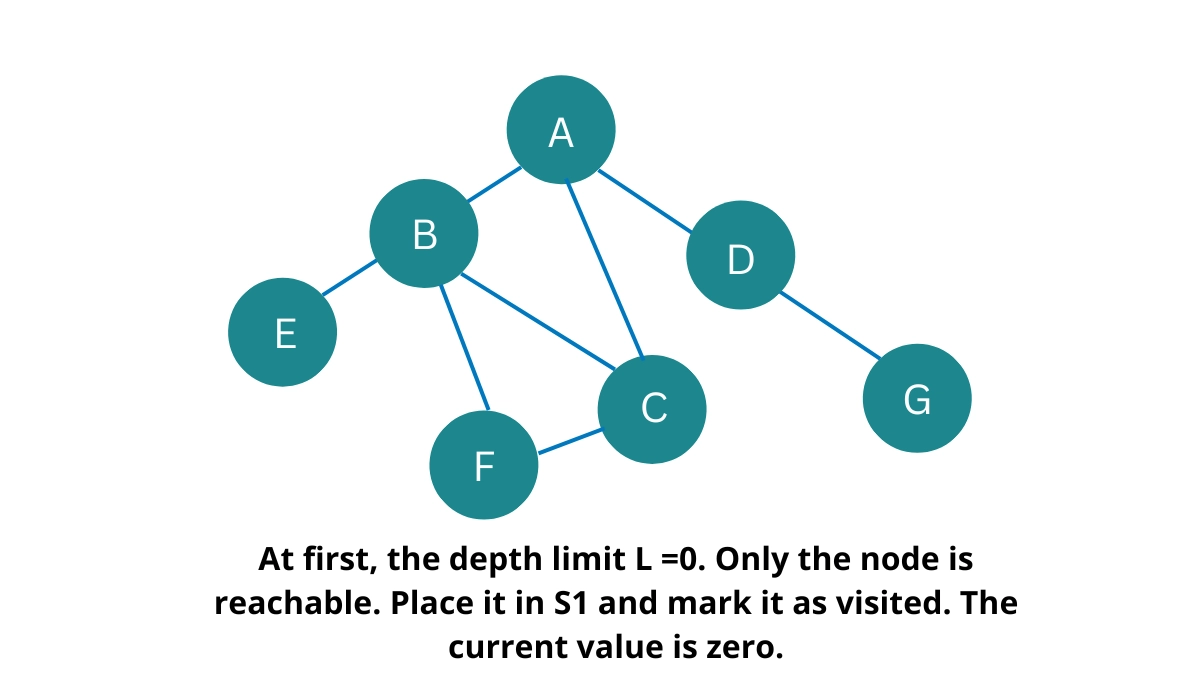
Initially, only node A is reachable. So put it in S2 and mark it as visited.
The current level is 0.
S2: A
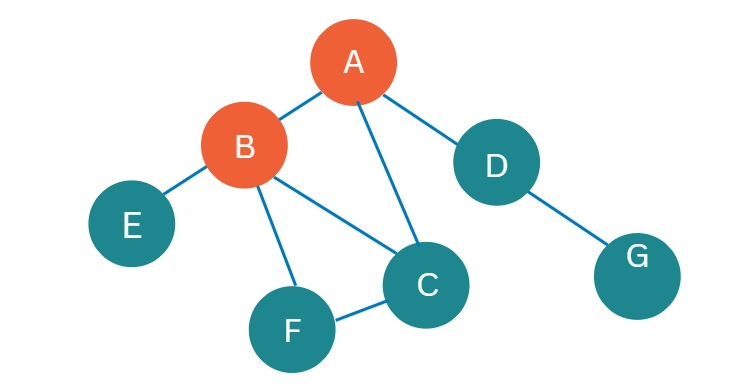
After exploring A, three nodes are now accessible: B, C, and D.
Assume we begin our exploration with node B.
B should be pushed into S2 and marked as visited.
The current level is one.
S2: B, A
Node B will be treated as having no successor because the current level is already the limited depth L.
As a result, nothing is reachable.
Take B from S2.
The current value is 0.
S2: A
Explore A once more.
There are two unvisited nodes, C and D, that can be reached.
Assume we begin our exploration with node C.
C is pushed into S1 and marked as visited.
The current level is one.
S2: C, A
Because the current level already has the limited depth L, node C is considered to have no successor.
As a result, nothing is reachable.
Take C from S2.
The current value is 0.
S2: A
Explore A once more.
There is only one unvisited node D, that can be reached.
D should be pushed into S2 and marked as visited.
The current level is one.
S2: D, A
D is explored, but no new nodes are found.
Take D from S2.
The current value is 0.
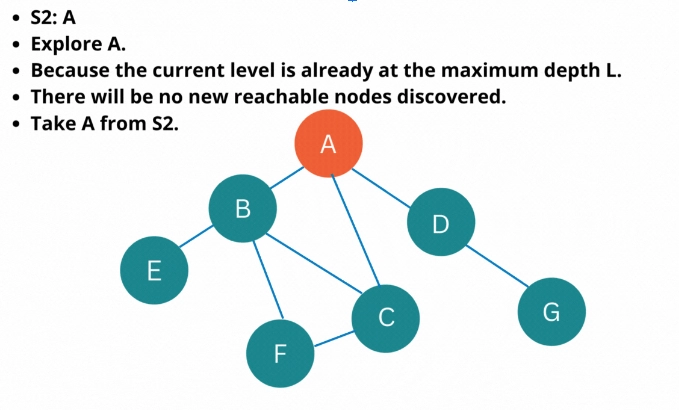
S2: A
Explore A once more.
There is no new reachable node.
Take A from S2.
Similiary at depth limit 2, IDS has already explored all the nodes reachable from a; if the solution exists in the Graph, it has been found.
Iterative Deepening Depth First Search(IDDFS)
From top to bottom, in the first search, you investigate each branch you enter totally before backtracking from it and going to the following. In iterative development, you don't go beneath the ongoing profundity and, consequently, don't investigate each branch you visit before backtracking.
How Does IDDFS Function?
IDDFS calls DFS for various profundities beginning from an underlying worth. In each call, DFS is limited from going past the given depth. So essentially, we do DFS in a BFS design.
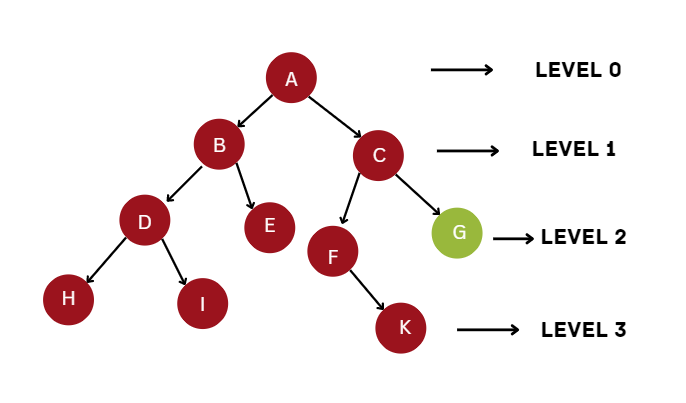
Let us see this with one example:
1'st repetition-----> A
2'nd repetition----> A, B, C
3'rdrepetition----->
A, B, D, E, C, F, G
4'th repetition------>A, B, D, H, I, E, C, F, K, G
The algorithm will find the goal node in the fourth iteration.
Algorithm
// Returns true if the target is reachable from
// src within max_depth
bool IDDFS(src, target, max_depth)
for limit from 0 to max_depth
if DLS(src, target, limit) == true
return true
return false
bool DLS(src, target, limit)
if (src == target)
return true;
// If reached the maximum depth,
// stop recursing.
if (limit <= 0)
return false;
foreach adjacent i of src
if DLS(i, target, limit?1)
return true
return false
int main() { int goal, limit; int n; cout<<"Enter no of nodes in graph "; cin>>n; map<int,vector<int>> adj; int edge; cout<<"Enter no of edge "; cin>>edge; for(int i=0;i<edge;i++) { int x,y; cin>>x>>y; adj[x].push_back(y); } cout<<"Enter the goal node: "; cin>>goal; cout<<"Enter depth limit: "; cin>>limit;
int res=DFS(0,goal,limit,adj);
if(res==-1) cout<<"Goal node not found !\n"; else cout<<"Goal node found within depth limit ";
return 0; }
You can also try this code with Online C++ Compiler
public class DepthLimitedSearch { static int DFS(int v, int goal, int limit, Map<Integer, List<Integer>> adj) { if (v == goal) { return 1; } if (limit > 0) { for (int nbr : adj.get(v)) { if (DFS(nbr, goal, limit - 1, adj) != -1) { return 1; } } } return -1; }
public static void main(String[] args) { Scanner scanner = new Scanner(System.in); System.out.print("Enter no of nodes in graph: "); int n = scanner.nextInt(); Map<Integer, List<Integer>> adj = new HashMap<>(); System.out.print("Enter no of edges: "); int edge = scanner.nextInt(); for (int i = 0; i < edge; i++) { int x = scanner.nextInt(); int y = scanner.nextInt(); adj.putIfAbsent(x, new ArrayList<>()); adj.get(x).add(y); } System.out.print("Enter the goal node: "); int goal = scanner.nextInt(); System.out.print("Enter depth limit: "); int limit = scanner.nextInt();
int res = DFS(0, goal, limit, adj);
if (res == -1) { System.out.println("Goal node not found!"); } else { System.out.println("Goal node found within depth limit"); } scanner.close(); } }
You can also try this code with Online Java Compiler
def DFS(v, goal, limit, adj): if v == goal: return 1 if limit > 0: for nbr in adj[v]: if DFS(nbr, goal, limit - 1, adj) != -1: return 1 return -1
def main(): n = int(input("Enter no of nodes in graph: ")) adj = {} edge = int(input("Enter no of edges: ")) for _ in range(edge): x, y = map(int, input().split()) if x not in adj: adj[x] = [] adj[x].append(y) goal = int(input("Enter the goal node: ")) limit = int(input("Enter depth limit: "))
res = DFS(0, goal, limit, adj)
if res == -1: print("Goal node not found!") else: print("Goal node found within depth limit")
if __name__ == "__main__": main()
You can also try this code with Online Python Compiler
class DepthLimitedSearch { static int DFS(int v, int goal, int limit, Dictionary<int, List<int>> adj) { if (v == goal) { return 1; } if (limit > 0) { foreach (int nbr in adj[v]) { if (DFS(nbr, goal, limit - 1, adj) != -1) { return 1; } } } return -1; }
static void Main() { Console.Write("Enter no of nodes in graph: "); int n = int.Parse(Console.ReadLine()); Dictionary<int, List<int>> adj = new Dictionary<int, List<int>>(); Console.Write("Enter no of edges: "); int edge = int.Parse(Console.ReadLine()); for (int i = 0; i < edge; i++) { string[] input = Console.ReadLine().Split(); int x = int.Parse(input[0]); int y = int.Parse(input[1]); if (!adj.ContainsKey(x)) { adj[x] = new List<int>(); } adj[x].Add(y); } Console.Write("Enter the goal node: "); int goal = int.Parse(Console.ReadLine()); Console.Write("Enter depth limit: "); int limit = int.Parse(Console.ReadLine());
int res = DFS(0, goal, limit, adj);
if (res == -1) { Console.WriteLine("Goal node not found!"); } else { Console.WriteLine("Goal node found within depth limit"); } } }
function DFS(v, goal, limit, adj) { if (v === goal) { return 1; } if (limit > 0) { for (let nbr of adj[v]) { if (DFS(nbr, goal, limit - 1, adj) !== -1) { return 1; } } } return -1; }
function main() { rl.question("Enter no of nodes in graph: ", n => { const adj = {}; rl.question("Enter no of edges: ", edge => { let count = parseInt(edge); const edges = [];
function readEdge() { if (count === 0) { rl.question("Enter the goal node: ", goal => { rl.question("Enter depth limit: ", limit => { const res = DFS(0, parseInt(goal), parseInt(limit), adj); if (res === -1) { console.log("Goal node not found!"); } else { console.log("Goal node found within depth limit"); } rl.close(); }); }); return; } rl.question("", edge => { let [x, y] = edge.split(' ').map(Number); if (!adj[x]) adj[x] = []; adj[x].push(y); count--; readEdge(); }); } readEdge(); }); }); }
main();
You can also try this code with Online Javascript Compiler
Time Complexity: O(b^d), where b is the branching factor and d is the depth of the goal node or the depth at which the DFS function iteration terminates.
Space Complexity: O(d), where d is the depth of the goal node, accounting for the maximum call stack size in a recursive DFS.
Frequently Asked Questions
Under what conditions could we need to run BFS or DFS rather than IDDFS?
It is called DFS in a BFS design. The tradeoff here is that IDDFS is substantially more convoluted to execute, so it ought to possibly truly be utilized, assuming you are worried about restricted BOTH existence.
What are the benefits of IDS over DFS and BFS?
The extraordinary benefit of IDDFS is found inside the in-game tree looking, where the IDDFS search activity attempts to develop further the profundity definition, heuristics, and scores of looking through hubs to empower productivity in the pursuit of calculation.
What is the contrast between BFS and IDS?
Iterative Deepening Search (IDS) is an iterative diagram looking through a procedure that exploits the culmination of the Breadth-First Search (BFS) technique however involves considerably less memory in every cycle (like Depth-First Search).
Why does BFS take more memory than DFS?
The DFS needs less memory as it just needs to monitor the hubs in a chain from the top to the base, while the BFS needs to watch every one of the hubs on a similar level.
Why isn't a deep first search ideal?
DFS isn't ideal, meaning the number of moves toward arriving at the arrangement or the expense spent in coming at it is high.
Conclusion
In this article, we talked about Iterative Deepening Search (IDS) and Iterative Deepening Depth First Search (IDDFS). These are ways to search through graphs or trees by slowly increasing the depth limit. This approach combines the good parts of Depth First Search (DFS) and Breadth First Search (BFS). It helps find the best solution while avoiding the problems of using too much memory or getting stuck in endless paths.









































 9+ registered
9+ registered 

