


























Introduction
The UGC NET, also known as the NTA-UGC-NET, is an examination used to determine eligibility for assistant professorships and Junior Research Fellowships at Indian universities and colleges. The National Testing Agency administers the exam on behalf of the University Grants Commission.
Now we will look at some of the questions that came in UGC NET June 2012 Paper III.
Questions with Solutions
1. Consider the following pseudocode segment :
K:=0
for i1 := l to n
for i2 := 1 to i1
:
:
:
for im := 1 to im–1
K:= K+1
The value of K after the execution of this code shall be
(A) C(n + m – 1, m)
(B) C(n – m + 1, m)
(C) C(n + m – 1, n)
(D) C(n – m + 1, n)
Solution) C(n + m – 1, m)
Explanation)

2. What happens to weight in Delta Rule for error minimization?
(A) weights are adjusted w.r.to change in the output
(B) weights are adjusted w.r.to difference between desired output and actual output
(C) weights are adjusted w.r.to difference between input and output
(D) none of the above
Solution) Weights are adjusted w.r.to difference between the desired output and actual output
Explanation) The weights are modified based on the difference between the desired and actual production.
3. When the tasks are completed in stages, the pipelining approach is most successful in enhancing performance:
(A) require different amount of time
(B) require about the same amount of time
(C) require different amount of time with time difference between any two tasks being same
(D) require different amount with time difference between any two tasks being different
Solution) require about the same amount of time
Explanation)

4. What is Granularity?
(A) The size of database
(B) The size of data item
(C) The size of record
(D) The size of file
Solution) The size of the data item
Explanation) Granularity is the size of the data item.
5. Assume that a 64-processor machine is used to run a particular application and that 70% of the application may be parallelized. Then, using Amdahl's rule, the projected performance improvement is
(A) 4.22
(B) 3.22
(C) 3.32
(D) 3.52
Solution) 3.22
Explanation)
In the case of parallelization, if P is the proportion of the programme that can be parallelized, then (1-P) is the fraction that cannot be parallelized, according to Amdahl's law. Then S(N)=1/(1-P)+P/N, where N is the number of processors and P is the proportion that may be parallelized, is the maximum speedup that can be achieved by employing N processors.
In the question above, no of processor, N=64
The proportion of the program that can be made parallel, P = 70%=0.7
So, substituting in the formula, we get, 1/(1-0.7)+0.7/64=1/0.3+0.0109375=1.0.310975
=3.215
=3.22
Therefore, the option is B.
6. Which degree of abstraction best describes the data in the database?
(A) Physical level
(B) View level
(C) Abstraction level
(D) Logical level
Solution) Logical level
Explanation) Physically, the conceptual level is higher than the physical level. It's also referred to as the logical level.
7. When a transaction updates a database object and then fails, this is known as the _______ problem.
(A) Temporary Select Problem
(B) Temporary Modify Problem
(C) Dirty Read Problem
(D) None
Solution) Dirty Read Problem
Explanation) When one transaction updates a database object and then fails for any reason, this is known as a dirty read problem.
8. To represent a 256 256 image with 256 grey levels in an image compression scheme, 16384 bits are used. What is this system's compression ratio?
(A) 1 (B) 2 (C) 4 (D) 8
Solution) 32
Explanation) (256 * 256 * 8) / (16384) = 32
9. What type of network is X.25?
(A) Connection Oriented Network
(B) Connection Less Network
(C) Either Connection Oriented or Connection Less
(D) Neither Connection Oriented nor Connection Less
Solution) Connection Oriented Network
Explanation) X. 25 is a connection-oriented protocol.
10. Which of the following techniques can be used to cluster data
(A) Single layer perception
(B) Multilayer perception
(C) Self organizing map
(D) Radial basis function
Solution) Self-organizing map
Explanation)
Self-organizing maps are a data visualisation tool that uses self-organizing neural networks to minimise the dimensions of data. It's an unsupervised learning method. The idea is to figure out what the data's underlying structure is.
11. Which strategy for overcoming a deadlock?
(A) Time out
(B) Time in
(C) Both (A) & (B)
(D) None of the above
Solution) Time out
Explanation) The use of timeout is one approach for avoiding deadlock in Java Multithreading. Assume that one thread holds a lock on one resource and is now waiting for a lock on another. If it can't get lock on resource 2 after a given amount of time, it should stop looking for lock on resource 2. It should also release the lock on resource 1. Deadlocks will be prevented as a result.
12. The parameter that may vary if the pixels of an image are shuffled is
(A) Histogram
(B) Mean
(C) Entropy
(D) Covariance
Solution) Covariance
Explanation) The covariance of two random variables is a measure of how much they fluctuate together.
13. The following is a property that both functional and logical programming languages share:
(A) Both are declarative
(B) Both are based on λ-calculus
(C) Both are procedural
(D) Both are functional
Solution) Both are declarative
Explanation) Prolog, Answer set programming (ASP.NET), and Datalog are three major logic programming language families. Rules are written in the form of clauses in all of these languages.
A Declarative Language is Prolog.
Functional programming is a declarative programming paradigm, which means that statements are replaced with expressions or declarations.
Prolog is a Declarative Language, according to both sources.
Functional programming is a declarative programming paradigm that falls under logic programming languages.
14. Given the following statements:
(i) Both deterministic and nondeterministic finite state machines have the same power.
(ii) The power of both deterministic and nondeterministic pushdown automata is the same.
Which of the following statement(s) is/are correct?
(A) Both (i) and (ii)
(B) Only (i)
(C) Only (ii)
(D) Neither (i) nor (ii)
Solution) Only (i)
Explanation) ALL Finite Automata have same expressive power
Determistic CFL(DCFL) is a proper subset of CFL
so DPDA < NPDA
So, B is Correct
15.Let Q(x, y) stand for "x + y = 0," and let there be two quantifications:
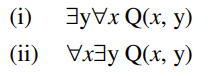
Where x and y are real numbers, Q(x, y). Then which of the following statements is correct?
(A) (i) is true & (ii) is false.
(B) (i) is false & (ii) is true.
(C) (i) is false & (ii) is also false.
(D) both (i) & (ii) are true.
Solution) (i) is false & (ii) is true.
Explanation)
16. Match the following :
(i) OLAP (a) Regression
(ii) OLTP (b) Data Warehouse
(iii) Decision Tree (c) RDBMS
(iv) Neural Network (d) Classification
(i) (ii) (iii) (iv)
(A) (b) (c) (a) (d)
(B) (b) (c) (d) (a)
(C) (c) (b) (a) (d)
(D) (c) (b) (d) (a)
Solution) (B)
Explanation) The words data warehousing and online analytical processing (OLAP) are occasionally used interchangeably to refer to distinct components of systems known as decision support systems or business intelligence systems.
In data mining and AI, decision trees are used to classify data.
Unsupervised learning, regression, and classification are all possible using neural networks.
OLTP There is detailed and current data in an OLTP database, and the entity model is the schema used to store transactional databases (usually 3NF).
as a result, i-b, 2-c, 3-d, and 4-a B is the answer.
17. Consider a R(A, B, C, D) schema with functional dependencies A, B, and C, D. The R1 (A, B) and R2 (C, D) decompositions are then performed.
(A) Dependency preserving but not lossless join
(B) Dependency preserving and lossless join
(C) Lossless Join but not dependency preserving
(D) Lossless Join
Solution) Dependency preserving but not lossless join
Explanation) Dependency Preserving Decomposition:
Decomposition of R into R1 and R2 is a dependency preserving decomposition if closure of functional dependencies after decomposition is same as closure of of FDs before decomposition.
A simple way is to just check whether we can derive all the original FDs from the FDs present after decomposition.
In the above question R(A, B, C, D) is decomposed into R1 (A, B) and R2(C, D) and there are only two FDs A -> B and C -> D. So, the decomposition is dependency preserving
Lossless-Join Decomposition:
Decomposition of R into R1 and R2 is a lossless-join decomposition if at least one of the following functional dependencies are in F+ (Closure of functional dependencies)
R1 ∩ R2 → R1
OR
R1 ∩ R2 → R2
In the above question R(A, B, C, D) is decomposed into R1 (A, B) and R2(C, D), and R1 ∩ R2 is empty. So, the decomposition is not lossless.
18. In an image-compression system, the quantizer is a
(A) lossy element which exploits the psychovisual redundancy
(B) lossless element which exploits the psychovisual redundancy
(C) lossy element which exploits the statistical redundancy
(D) lossless element which exploits the statistical redundancy
Solution) the lossy element, which exploits the psychovisual redundancy
Explanation) Quantization is a lossy compression technique used in image processing that compresses a range of values into a single quantum value. A stream gets more compressible when the number of discrete symbols in it is reduced.
19. What does a Data Warehouse provide?
(A) Transaction Responsiveness
(B) Storage, Functionality Responsiveness to queries
(C) Demand and Supply Responsiveness
(D) None of the above
Solution) Storage, Functionality Responsiveness to queries
Explanation) Data warehouses are designed to provide storage, functionality, and query response times that go beyond what today's transaction-oriented databases can give. Data warehouses are also used to increase database data access performance.
20. The A* method estimates the cost of moving from the original state to the goal state using the formula f' = g + h,' where g is a measure of the cost of moving from the beginning state to the current node and h' is an estimate of the cost of moving from the current node to the goal state.
We should establish a goal of finding a path with the fewest steps possible.
(A) g = 1
(B) g = 0
(C) h' = 0
(D) h' = 1
Solution) g = 1
Explanation) The most essential type of Best first search algorithm is the A* algorithm (greedy search which may move either depth wise or breadth wise as needed to get the best solution also known as OR graph)
f=g+h'
g is a measure of cost getting from initial state to the current node and the function
The cost of getting from the present node to the desired state is estimated by h'.
Now, if we want to identify a path with the fewest steps, we set the cost of travelling from a node to its successor (i.e. g) to a constant, usually 1.
21. The transform with the greatest 'energy compaction' attribute is
(A) Slant transform
(B) Cosine transform
(C) Fourier transform
(D) Karhunen-Loeve transform
Solution) Karhunen-Loeve transform
Explanation) The transform with the greatest 'energy compaction' attribute is Karhunen-Loeve transform.
22. Which prologue scripts below correctly implement "if G succeeds, then execute goal P; otherwise, execute goal?"
(A) if-else (G, P, θ) :- !, call(G), call(P). if-else (G, P, θ) :- call(θ).
(B) if-else (G, P, θ) :- call(G), !, call(P). if-else (G, P, θ) :- call(θ).
(C) if-else (G, P, θ) :- call(G), call(P), !. if-else (G, P, θ) :- call(θ).
(D) All of the above
Solution) if-else (G, P, θ) :- call(G), !, call(P). if-else (G, P, θ) :- call(θ).
Explanation)

23. The ______ memory allocation function changes the previously allocated space.
(A) calloc( )
(B) free( )
(C) malloc( )
(D) realloc( )
Solution) realloc( )
Explanation) The realloc( ) memory allocation function changes the previously allocated space.
24.Which statement(s) is/are not correct?
Every recursive context-sensitive language.
(ii) A non-context-sensitive recursive language exists.
(A) (i) is true, (ii) is false.
(B) (i) is true and (ii) is true.
(C) (i) is false, (ii) is false.
(D) (i) is false and (ii) is true.
Solution) (i) is true, and (ii) is true
Explanation)
- Every recursive language is context-sensitive. Correct
- The set of all non-recursively enumerable languages is countable.Incorrect
- Under union, the family of recursively enumerable languages is closed.Correct
- Reversal closes the families of recursively enumerable and recursive languages. Correct
25. The system that connects code and data while keeping them safe from the outside world is referred to as
(A) Abstraction
(B) Inheritance
(C) Encapsulation
(D) Polymorphism
Solution) Encapsulation
Explanation) The system that connects code and data while keeping them safe from the outside world is referred to as Encapsulation.
26. Identify the addressing modes of the below instructions and match them :
(a) ADI (1) Immediate addressing
(b) STA (2) Direct addressing
(c) CMA (3) Implied addressing
(d) SUB (4) Register addressing
(A) a – 1, b – 2, c – 3, d – 4
(B) a – 2, b – 1, c – 4, d – 3
(C) a – 3, b – 2, c – 1, d – 4
(D) a – 4, b – 3, c – 2, d – 1
Solution) a – 1, b – 2, c – 3, d – 4
Explanation) It is Immediate addressing since ADI stands for Add Immediate.
STA stands for copying the contents of the accumulator to a memory location, making it a direct addressing method.
CMA stands for supplement the accumulator's content. The Complement Accumulator (CMA) instruction sets the 1s complement of the 8 bits in the A register, that is, the 1s become 0s and the 0s become 1s. so it's assumed
Because SUB subtracts, it is register addressing.
27. Which one of the following is not a Greibach Normal grammar form? (i) S → a | bA | aA | bB A → a B → b
(ii) S → a | aA | AB A → a B → b
(iii) S → a | A | aA A → a
(A) (i) and (ii)
(B) (i) and (iii)
(C) (ii) and (iii)
(D) (i), (ii) and (iii)
Solution) (ii) and (iii)
Explanation) A context free Grammar is said to be Greibach normal form if all the productions have the form
A → ax
where a∈ T and x∈ v*
(ii)Eliminate due to production
S→AB
(iii)Eliminate Due to production
S→A
only(1) Satisfying the required conditions.
28. A multicast address is which one of the following IP address class.
(A) Class A
(B) Class B
(C) Class C
(D) Class D
Solution) Class D
Explanation) A multicast address is Class D IP address.
29. When unit testing a module, it was discovered that up to 90% of the code was tested alone for a given piece of test data, with a probability of success of 0.9. The module's dependability is high.
(A) atleast greater than 0.9
(B) equal to 0.9
(C) atmost 0.81
(D) atleast 1/0.81
Solution) atmost 0.81
Explanation) Code tested maximum 0.90%
probability of success is 0.9
So, reliability of the module atmost 0.9 * 0.9 =0.81
30.The upper bound on the time it takes to solve the m colouring decision issue is
(A) O(nm)
(B) O(nm)
(C) O(nmn)
(D) O(nmmn)
Solution) O(nmn)
Explanation) No explanation



 9+ registered
9+ registered 

