



























Introduction
UGC NET Exam is a very popular exam in India for people interested in research. Previous Year Questions are an excellent option to learn about the exam pattern. By solving the PYQs, you will get a basic idea about your preparation. You can evaluate your weak areas and work on them to perform better in the examination. In this article, we have given the questions of UGC NET 2013 June Paper-II. We have also explained every problem adequately to help you learn better.
Note: This article contains Q.No. 1 to Q.No. 25 out of the 50 questions asked in NET June 2013 paper II. The solution to Q.No. 26 to Q.No. 50 can be found in June 2013 Paper-II Part-2 article.
June 2013 paper II
-
COCOMO stands for
(A) COmposite COst MOdel
(B) COnstructive COst MOdel
(C) COnstructive COmposite MOdel
(D) COmprehensive COnstruction MOdel
Answer: B
COCOMO is used to estimate the cost of the software after gathering the requirements from the user. It was developed by Barry Boehm.
-
Match the following:
a. Good quality i. Program does not fail for a specified time in a given environment
b. Correctness ii. Meets the functional requirements
c. Predictable iii. Meets both functional and non-functional requirements
d. Reliable iv. Process is under statistical control
Codes
a b c d
(A) iii ii iv i
(B) ii iii iv i
(C) i ii iv iii
(D) i ii iii iv
Answer: A
Good quality software should meet the functional and non-functional requirements. In functional requirements, we define the expectations from the system, and in non-functional requirements, we specify how well the software performs its functions.
Correctness defines how the software behaves when used correctly. So, correctness meets the functional requirements.
Predictable means the process is under control.
Reliable means the program does not fail.
-
While estimating the cost of software, Lines of Code (LOC) and Function Points (FP) are used to measure which one of the following?
(A) Length of code (B) Size of software
(C) Functionality of software (D) None of the above
Answer: B
For the size-estimation of software, two things are considered. The first one is Line of Code (LOC) and the second one is Function Points (FP). A line of code is the number of lines of declarations or actual code logic excluding the comments and blank spaces. Function points measure the functionality from the user's point of view.
-
A good software design must have
(A) High module coupling, High module cohesion
(B) High module coupling, Low module cohesion
(C) Low module coupling, High module cohesion
(D) Low module coupling, Low module cohesion
Answer: C
Coupling is the measure of inter-dependency or the relationship between the models, i.e., how strongly two models are connected. Cohesion is the degree to which elements of a module are related to each other.
If two modules are strongly interconnected, the change in one module will also bring changes in the other module which is not good in software design. So, we want low module coupling.
If one element is following a particular functionality then we want other elements to also follow that functionality so that the task can be performed by the module. So we need a good relationship between the elements of a module. So, we want high cohesion.
-
Cyclometric complexity of a flow graph G with n vertices and e edges is
(A) V(G) = e+n-2
(B) V(G) = e-n+2
(C) V(G) = e+n+2
(D) V(G) = e-n-2
Answer: B
Cyclometric complexity is a metric of the complexity of a program and it is measured using the formula e-n+2. So, the correct answer is option B.
-
When the following code is executed what will be the value of x and y?
int x = 1, y=0;
y = x++;
(A) 2, 1 (B) 2, 2
(C) 1, 1 (D) 1, 2
Answer: A
In the post-increment operation, we first assign the value x in y and then increment the value of x. So the value of y will be 1 and the value of x will be incremented to 2.
-
How many values can be held by an array A(-1,m;1 ,m) ?
(A) m (B) m2
(C) m(m+l) (D) m(m+2)
Answer: D
Given array is a 2-D matrix
A[-1,m][1,m]
Number of rows = m -(-1) +1 = m+2
Number of columns = m -1 +1 = m
Number of cells = (rows) x (columns) = m(m+2)
-
What is the result of the expression
(1&2)+(3/4) ?
(A) 1 (B) 2
(C) 3 (D) 0
Answer: D
(1&2) is a bitwise operation which gives 0
(¾) = 0
So, (1&2) + (¾) = 0
-
How many times the word 'print' shall be printed by the following program segment?
for(i=1, i≤2, i++)
for(j=1, j≤2, j++)
for(k=1, k≤2, k++)
printf("print/n")
(A) 1 (B) 3
(C) 6 (D) 8
Answer: D
This is a nested loop, so we multiply the number of times each loop runs to get the final result. Here each loop runs 2 times. So the answer will be 2*2*2=8.
-
Which of the following is not a type of Database Management System?
(A) Hierarchical (B) Network
(C) Relational (D) Sequential
Answer: D
Sequential is not a type of DBMS.
-
Manager's salary details are to be hidden from Employee Table. This Technique is called as
(A) Conceptual level Datahiding
(B) Physical level Datahiding
(C) External level Datahiding
(D) Logical level Datahiding
Answer: C
We are hiding the data for a group of users so the technique used is External level Datahiding. It is at the highest level of database abstraction where only those portions of the database concerning to a user or application programme are included.
-
A Network Schema
(A) restricts to one to many relationship
(B) permits many to many relationship
(C) stores Data in a Database
(D) stores Data in a Relation
Answer: B
A network schema permits many-to-many relationships.
-
Which normal form is considered as adequate for usual database design?
(A) 2NF (B) 3NF
(C) 4NF (D) 5NF
Answer: B
2NF -> no partial dependency allowed.
3NF -> no transitive dependency
4NF (BCNF) -> higher version of 3NF but doesn’t give a guarantee about the functional dependencies.
3NF gives a guarantee on functional dependencies and lossless joins. So, it is adequate for a usual database design.
-
If D1, D2,…. Dn are domains in a relational model, then the relation is a table, which is a subset of
(A) D1+D2+…. +Dn
(B) D1x D2x… xDn
(C) D1U D2U….UDn
(D) D1- D2-….-Dn
Answer: B
The value of relation is the cartesian product of all the domains. Option B is the cartesian product of all the domains. So the right answer is option B.
-
Which of the following addresses is used to deliver a message to the correct application program running on a host?
(A) Port (B) IP
(C) Logical (D) Physical
Answer: A
It is the responsibility of the transport layer to identify the process to which the data is to be given in a particular system. To differentiate between the multiple processes, the port number is used by the transport layer which is a 16-bit integer.
-
In ________ substitution, a character in the plaintext is always changed to the same character in the ciphertext, regardless of its position in the text.
(A) polyalphabetic (B) monoalphabetic
(C) transpositional (D) multialphabetic
Answer: B
Monoalphabetic and Polyalphabetic are the two types of substitution cipher. In monoalphabetic substitution, a character in the plaintext is always changed to the same character in the ciphertext whereas, in polyalphabetic substitution, the same characters in plaintext can be changed to multiple different characters in the ciphertext.
-
In classful addressing, the IP address 190.255.254.254 belongs to
(A) Class A (B) Class B
(C) Class C (D) Class D
Answer: B
The range of class B is 128-191. And 190 of the given IP Address belong to this range only. So the given IP address belongs to Class B.
-
In hierarchical routing with 4800 routers, what region and cluster sizes should be chosen to minimize the size of the routing table for a three layer hierarchy?
(A) 10 clusters, 24 regions and 20 routers
(B) 12 clusters, 20 regions and 20 routers
(C) 16 clusters, 12 regions and 25 routers
(D) 15 clusters, 16 regions and 20 routers
Answer: D
In a three-layer hierarchy, first, there are regions, then clusters and then there are routers. To minimize the size of the routing table, we have to minimize the value of the below-given formula.
(clusters-1) + (regions-1) + routers
After putting the values of each option in the above formula, we get the minimum value from option D. So, the answer will be option D.
-
In IPv4 header, the ______ field is needed to allow the destination host to determine which datagram a newly arrived fragment belongs to.
(A) identification (B) fragment offset
(C) time to live (D) header checksum
Answer: A
The identification number helps the receiver to know that the newly arrived fragment belongs to which datagram.
Fragment offset helps to determine the order in which the fragments arrive.
Time to live determines the life of the fragment. If the time to live value is zero then the fragment is discarded.
Header checksum is used to verify the header only.
-
Given L1 = L(a*baa*) and L2 = L(ab*)
The regular expression corresponding to language L3 = L1/L2 (right quotient) is given by
(A) a*b (B) a*baa*
(C) a*ba* (D) None of the above
Answer: C
The right quotient of a language L1 with a language L2 is the language consisting of string w such that wx is in L1 for some string x in L2.
L1 = (a*baa*) = {ba, baa, aba, abaa, …}
L2 = (ab*) = {a, ab, abb, abbb, …}
L3 = L1/L2 = {b, ba, ab, aba, …} = (a*ba*)
So the correct answer is option C.
-
Given the production rules of a grammar G1 as
S1→AB | aaB
A→a | Aa
B→b
and the production rules of a grammar G2 as
S2→aS2bS2 | bS2aS2 | λ
Which of the following is correct statement?
(A) G1 is ambiguous and G2 is not ambiguous.
(B) G1 is ambiguous and G2 is ambiguous.
(C) G1 is not ambiguous and G2 is ambiguous.
(D) G1 is not ambiguous and G2 is not ambiguous.
Answer: B
For G1:
We can generate two parse trees for string aab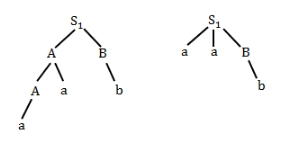
Source
For G2:
We can generate more than one parse tree for abab, baba, etc.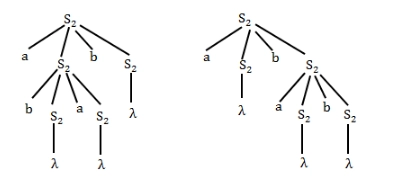
Source
Therefore, both G1 and G2 are ambiguous.
-
Given a grammar : S1→Sc, S→SA|A, A→aSb|ab, there is a rightmost derivation S1=>Sc =>SAC=>SaSbc. Thus, SaSbc is a right sentential form, and its handle is
(A) SaS (B) be
(C) Sbe (D) aSb
Answer: D
Right-Sentential Form is a sentential form that can be derived by a rightmost derivation.
The handle is a substring that matches the right-hand side of a production and represents 1 step in the derivation.
The given grammar is
S1 -> Sc
S -> SA | A
A -> aSb | ab
The right most derivation is
S1 -> Sc -> SAc -> SaSbc
In SaSbc, if we put aSb by A then we can reduce the step back to get SAc. So, aSb is the handle for the above sentential form.
-
The equivalent production rules corresponding to the production rules
S→Sα1|Sα2|β1|β2 is
(A) S→β1 | β2, A→α1A | α2A | λ
(B) S→β1 | β2 | β1A | β2A, A→α1A | α2A
(C) S→β1 | β2, A→α1A | α2A
(D) S→β1 | β2 | β1A | β2A, A→α1A | α2A | λ
Answer: D
The production rule is given as S→Sα1|Sα2|β1|β2
There is left recursion in S→Sα1 and S→Sα2 and no left recursion in S→β1 and S→β2. So, by removing the left recursion.
S→β1A | β2A | a
A→α1A | α2A | λ
Putting A= λ in S→β1A | β2A | a
S→β1A | β2A | β1 | β2 || S→β1 | β2 | β1A | β2A
A→α1A | β2A | λ || A→α1A | α2A | λ
So the correct answer will be
S→β1 | β2 | β1A | β2A, A→α1A | α2A | λ
-
Given a Non-deterministic Finite Automation (NFA) with states p and r as initial and final states respectively transition table as given below
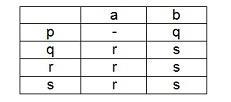
The minimum number of states required in Deterministic Finite Automation (DFA) equivalent to NFA is
(A) 5 (B) 4
(C) 3 (D) 2
Answer: B
Given NFA: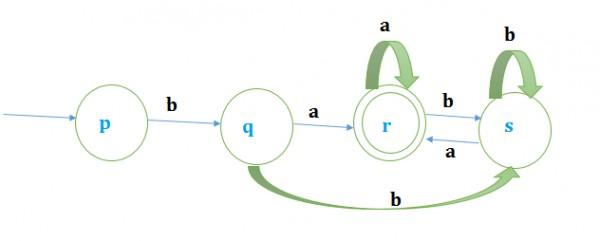
Source
Required DFA: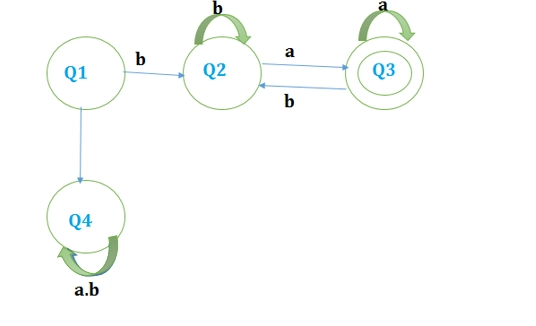
Source
Hence, the minimum number of states=4
So the correct option is B
-
Which is the correct statement(s) for Non Recursive predictive parser?
S1: First(α) = {t | α => * t β for some string β } => *tβ
S2: Follow(X) = { a | S => * αXa β for some strings α and β }
(A) Both statements S1 and S2 are incorrect.
(B) S1 is incorrect and S2 is correct.
(C) S1 is correct and S2 is incorrect.
(D) Both statements S1 and S2 are correct.
Answer: D
Statement-1:
( => *) means after some step
* represents an arbitrary number of steps and it is not part of the terminal
So, if α after some step has t as the first symbol in some sentential form, then first α must be {t}
So statement 1 is true
Statement-2:
α -> tβ Here First(α) = {*}
S -> *αXaβ
Follow(X) = {a}
So statement 2 is also true


 9+ registered
9+ registered 

