



























Introduction
This blog will cover the questions and solutions of GATE's previous year’s June 2014 paper III. We will also look at the explanations of each solution. Also, check out June 2014 paper III-Part 2 and June 2014 paper III-Part 3 here.
Questions with Solutions
1. Beam-penetration and shadow-mask are the two basic techniques for producing color displays with a CRT. Which of the following is not true?
I. The beam-penetration is used with random scan monitors.
II. Shadow-mask is used in raster scan systems.
III. Beam-penetration method is better than shadow-mask method.
IV. Shadow-mask method is better than beam-penetration method.
(A) I and II
(B) II and III
(C) III only
(D) IV only
Answer: C
Explanation: In CRT monitors, there are two major methods for producing color:
1. Beam Penetration
2. The Shadow-Mask Method
Beam Penetration vs. Shadow Mask: What's the difference?
| Beam Penetration | Shadow-Mask Method | |
| Used in | Color is displayed via the Random Scan System. | It displays color via a raster scan system. |
| Color | Red, Green, Orange, and Yellow are the only four colors available. | It may display a variety of colors. |
| Dependency on Color | Since the colors in Beam Penetration depends on the electron beam's speed, and fewer colors are accessible. | Since the colors of Shadow Mask are dependent on the type of ray, there are millions of options. |
| Cost | When compared to Shadow Mask, it is less expensive. | It is more costly than alternative methods. |
| Picture Quality | With the Beam Penetration Method, the picture quality is not good, i.e., poor. | Shadow Mask adds reality to any image with its shadow effect and millions of colors. |
| Resolution | It produces high-resolution images. | It produces a low-resolution image. |
| Criteria | Color display in the Beam Penetration method is determined by how far the electron excites the outer Red layer and then the Green layer. | There are no such criteria for producing colors in the Shadow Mask Method. It can be found in computers, color television, and other electronic devices. |
2. Line caps are used for adjusting the shape of the line ends to give them a better appearance. Various kinds of line caps used are
(A) Butt cap and sharp cap
(B) Butt cap and round cap
(C) Butt cap, sharp cap and round cap
(D) Butt cap, round cap and projecting square cap
Answer: D
Explanation: The line caps helps us in improving the appearance of the line by adjusting the shape of the line end.
There are three types of line caps:
- Butt Cap,
- Round Cap,
- Projection Square Cap
3. Given below are certain output primitives and their associated attributes. Match each primitive with its corresponding attributes:
List – I List – II
a. Line i. Type, Size, Color
b. Fill Area ii. Color, Size, Font
c. Text iii. Style, Color, Pattern
d. Marker iv. Type, Width, Color
Codes :
a b c d
(A) i ii iii iv
(B) ii i iii iv
(C) iv iii ii i
(D) iii i iv ii
Answer: C
Explanation:
Line - Basic attributes of a straight line segment are its type, its width, and its color. Therefore, a-iv.
Fill Area - We may fill a region with a variety of colors, styles, and patterns, thus, b-iii.
Text - Any text can be written in a variety of fonts, colors, and sizes, so, c-ii.
Marker - The color of the marker, the type of maker, and the size of the marker are the graphical properties, therefore, d-i.
4. Consider a window bounded by the lines :
x = 0; y= 0; x = 5 and y = 3.
The line segment joining (–1, 0) and (4, 5), if clipped against this window will connect the points
(A) (0, 1) and (2, 3)
(B) (0, 1) and (3, 3)
(C) (0, 1) and (4, 3)
(D) (0, 1) and (3, 2)
Answer: A
Explanation:
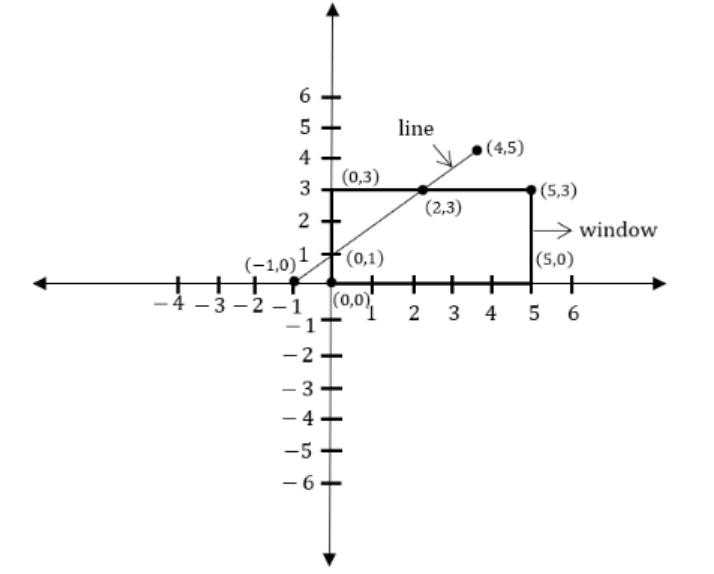
We will calculate the equation for combining line segments (1,0) and (4,5):
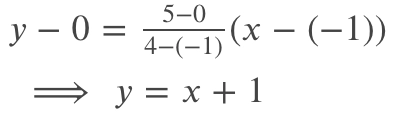
Only options A (0,1) and B (2,3) satisfy this requirement now. As a result, A is the answer.
5. Which of the following color models are defined with three primary colors?
(A) RGB and HSV color models
(B) CMY and HSV color models
(C) HSV and HLS color models
(D) RGB and CMY color models
Answer: D
Explanation: RGB (Red, Green, Blue) and CMY (cyan, magenta, yellow) are the two color models.
6. In a digital transmission, the receiver clock is 0.1 percent faster than the sender clock. How many extra bits per second does the receiver receive if the data rate is 1 Mbps?
(A) 10 bps
(B) 100 bps
(C) 1000 bps
(D) 10000 bps
Answer: C
Explanation: The receiver clock is 0.1% faster than the sender clock.
1000000 bits sent by the sender at 1 Mbps.
Extra bits received by the receiver = 1000000 * 0.1100 (because the receiver clock is 0.1% faster than the sender clock)
= 1000 bits
The total no. of bits received by the receiver clock = 1001000 bits.
Extra bit per second received by the receiver = 1000 bps.
As a result, Option(C) is the correct option.
7. Given U = {1, 2, 3, 4, 5, 6, 7}
A = {(3, 0.7), (5, 1), (6, 0.8)}
then ~A will be : (where ~ → complement)
(A) {(4, 0.7), (2, 1), (1, 0.8)}
(B) {(4, 0.3), (5, 0), (6, 0.2) }
(C) {(1, 1), (2, 1), (3, 0.3), (4, 1), (6, 0.2), (7, 1)}
(D) {(3, 0.3), (6.0.2)}
Answer: C
Explanation: Complement of a fuzzy set-
The complement of a fuzzy set A is a new fuzzy set A Complement, containing all the elements which are in the universe of discourse but not in A, with the membership function
Complement of µA(x) = 1 - µA(x)
Complement of a fuzzy set A is a new fuzzy set A complement. Since it is a fuzzy set, there will be two members in a singleton. The first member will be all the elements that are in the universe of discourse but not in A. The membership function will be 1- µA(x).
So, the complement of A will be
{(1,1),(2,1),(3,0.3),(4,1),(6,0.2),(7,1)}
The first is (1,1). The first 1 is in U but not in A, so it should be added in the complement. The second 1 is because the membership function is 1- µA(x). 1-0=1.
The same reason why you get (2,1).
The third one is (3,0.3) because it is (3,1-0.7)=(3,0.3).
Same reason why you have (4,1) and (7,1).
(6,1-0.8)=(6,0.2).
The member (5,0) is not included because, a singleton whose membership to a fuzzy set is 0, can be excluded.
8. Consider a fuzzy set old as defined below
Old = {(20, 0.1), (30, 0.2), (40, 0.4), (50, 0.6), (60, 0.8), (70, 1), (80, 1)}
Then the alpha-cut for alpha = 0.4 for the set old will be
(A) {(40, 0.4)}
(B) {50, 60, 70, 80}
(C) {(20, 0.1), (30, 0.2)}
(D) {(20, 0), (30, 0), (40, 1), (50, 1), (60, 1), (70, 1), (80, 1)}
Answer: D
Explanation: The cutoff value is known as the alpha cut. In the specified fuzzy set, the number of members with a value greater than or equal to will be considered present in the result. Now, in the set, OLD people with ages of 40, 50, 60, 70, and 80 have the membership values greater than or equal to 0.4, so they are considered members with value 1 and 20-30 people with values less than the cutoff are not members, so they are shown with value 0.
D is the answer.
9. Perceptron learning, Delta learning and LMS learning are learning methods which falls under the category of
(A) Error correction learning – learning with a teacher
(B) Reinforcement learning – learning with a critic
(C) Hebbian learning
(D) Competitive learning – learning without a teacher
Answer: A
Explanation: Error-Correction: The approach of comparing the system output to the desired output value is referred to as learning in supervised learning. This category includes learning methods such as perceptron learning, delta learning, and LMS learning.
10. Code blocks allow many algorithms to be implemented with the following parameters :
(A) clarity, elegance, performance
(B) clarity, elegance, efficiency
(C) elegance, performance, execution
(D) execution, clarity, performance
Answer: B
Explanation: Code blocks not only make it possible to construct various algorithms with clarity, elegance, and efficiency, but they also aid the programmer in comprehending the true nature of the routine.
11. Match the following with respect to the jump statements:
List – I List – II
a. return i. The conditional test and increment portions
b. goto ii. A value associated with it
c. break iii. Requires a label for operation
d. continue iv. An exit from only the innermost loop
Codes :
a b c d
(A) ii iii iv i
(B) iii iv i ii
(C) iv iii ii i
(D) iv iii i ii
Answer: A
Explanation:
Return: The return statement marks the end of a function's execution and returns control back to the calling function. The calling function continues execution at the place where the call was made. The calling function can also get a value via a return statement
Goto: In C programming, a goto statement jumps unconditionally from the 'goto' to a named statement in the same function. However, using this statement in a program is not recommended because it makes it difficult to trace a program's control flow, making it difficult to understand and alter.
Break: It can be used in two places in C-Language. When a break statement is reached within a loop, the loop is instantly ended, and program control is resumed at the next statement after the loop, or It can be used in a switch statement to end a case.
Continue: In C programming, the continue statement is similar to the break statement. Instead of terminating the loop, it compels the next iteration to begin, bypassing any code in the between.
12. The control string in C++ consists of three important classifications of characters
(A) Escape sequence characters, Format specifiers and Whitespace characters
(B) Special characters, White-space characters and Non-white space characters
(C) Format specifiers, White-space characters and Non-white space characters
(D) Special characters, White-space characters and Format specifiers
Answer: C
Explanation: The control string in C++ consists of three important classifications of characters -
- Format specifiers
- White-space characters
- Non-white space characters
13. Match the following with respect to I/O classes in object oriented programming:
List – I List – II
a. fopen() i. returns end of file
b. fclose() ii. return for any problem report
c. ferror() iii. returns 0
d. feof() iv. returns a file pointer
Codes:
a b c d
(A) iv i ii iii
(B) iii i iv ii
(C) ii iii iv i
(D) iv iii i ii
Answer: A
Explanation:
a. fopen() - iv. returns a file pointer
b. fclose() - i. returns end of file
c. ferror() - ii. return for any problem report
d. feof() - iii. returns 0
14. Which one of the following describes the syntax of prolog program ?
I. Rules and facts are terminated by full stop (.)
II. Rules and facts are terminated by semicolon (;)
III. Variables names must start with upper case alphabets.
IV. Variables names must start with lower case alphabets.
Codes :
(A) I, II
(B) III, IV
(C) I, III
(D) II, IV
Answer: C
Explanation: Variables in Prolog begin with an uppercase letter. The names of predicates, functions, and objects must all start with a lowercase letter and the rules and facts come to an end with a full stop (.).
15. Let L be any language. Define even (W) as the strings obtained by extracting from W the letters in the even-numbered positions and even(L) = {even (W) | W ∈ L}.
We define another language Chop (L) by removing the two leftmost symbols of every string in L given by Chop(L) = {W | ν W ∈ L, with | ν | = 2}.
If L is a regular language then
(A) even(L) is regular and Chop(L) is not regular.
(B) Both even(L) and Chop(L) are regular.
(C) even(L) is not regular and Chop(L) is regular.
(D) Both even(L) and Chop(L) are not regular.
Answer: B
Explanation: Since the term obtained after removal belongs to the same language L in both cases, the language L is regular. As a result, ‘even’ and ‘Chop’ both define regular languages.
16. Software testing is
(A) the process of establishing that errors are not present.
(B) the process of establishing confidence that a program does what it is supposed to do.
(C) the process of executing a program to show that it is working as per specifications.
(D) the process of executing a program with the intent of finding errors.
Answer: D
Explanation: The process of executing the program or system to identify errors is known as software testing. It also includes any activity that analyzes a program's or system's attribute or capability and determines whether it achieves the desired goals. Software is similar to other physical processes in that it accepts inputs and produces outputs. The way software fails is where it varies from other types of software. Most physical systems fail in a predictable (and small) number of ways. Software, on the other hand, can fail in a variety of strange ways. Detecting all of the many software failure modes is often impossible.
17. Assume that a program will experience 200 failures in infinite time. It has now experienced 100 failures. The initial failure intensity was 20 failures/CPU hr.
Then the current failure intensity will be
(A) 5 failures/CPU hr
(B) 10 failures/CPU hr.
(C) 20 failures/CPU hr.
(D) 40 failures/CPU hr.
Answer: B
Explanation: Current Failure Intensity = Initial Failure Intensity X [1 – Experienced failures/Failures in infinite time]
= 20 X [1 – 100/200]
= 20 X (100/200)
= 10 failures / CPU hour
18. Consider a project with the following functional units :
Number of user inputs = 50
Number of user outputs = 40
Number of user enquiries = 35
Number of user files = 06
Number of external interfaces = 04
Assuming all complexity adjustment factors and weighing factors as average, the function points for the project will be
(A) 135
(B) 722
(C) 675
(D) 672
Answer: D
Explanation: FP = UFP*CAF, where CAF denotes the complex adjustment factor and F denotes the function point.
FP = [0.65+0.01 x ΣFi ], where Fi (i=1 to 14) are the degree of influence
UFP = Unadjusted Function Points = Σ Wij Zij (i=1 to 5)
Let us compute the function points:
0: no influence
1: incidental
2: moderate
3: average
4: significant
5: essential
Function points components and weights as below:
S/W Components Weighting Factors
Simple Average Complex
No. of user inputs 3 4 6
No. of user outputs 4 5 7
No. of user inquires 3 4 6
No. of files 7 10 15
No. of external interfaces 5 7 10
Now coming to the question,
UFP = Σ Wij Zij = 50 x 4+ 40 x 5+ 35 x 4+ 6 x 10 + 4 x 7 = 628 (As all weighting factors are avg)
CAF = (0.65 + 0.01 (14 x 3) = 1.07
FP = UFP * CAF = 628 x 1.07 = 672 (APPROX.)
Therefore, ans is D.
19. Match the following :
List – I List – II
a. Correctness i. The extent to which a software tolerates the unexpected problems
b. Accuracy ii. The extent to which a software meets its specifications
c. Robustness iii. The extent to which a software has specified functions
d. Completeness iv. Meeting specifications with precision
Codes :
a b c d
(A) ii iv i iii
(B) i ii iii iv
(C) ii i iv iii
(D) iv ii i iii
Answer: A
Explanation:
List – I List – II
a. Correctness ii. The extent to which a software meets its specifications
b. Accuracy iv. Meeting specifications with precision
c. Robustness i. The extent to which a software tolerates the unexpected problems
d. Completeness iii. The extent to which a software has specified functions
20. Which one of the following is not a definition of error ?
(A) It refers to the discrepancy between a computed, observed or measured value and the true, specified or theoretically correct value.
(B) It refers to the actual output of a software and the correct output.
(C) It refers to a condition that causes a system to fail.
(D) It refers to human action that results in software containing a defect or fault.
Answer: C
Explanation: The difference between the observed or approximately determined value and the true value of a quantity is known as error.
The term "error" refers to a human action that results in software with a defect or flaw.
Failure, on the other hand, is a circumstance that leads a system to fail.
As a result, the solution is C.
21. Which one of the following is not a key process area in CMM level 5 ?
(A) Defect prevention
(B) Process change management
(C) Software product engineering
(D) Technology change management
Answer: C
Explanation: CMM level 5 is also called ‘Optimized’. The software process is at CMM level 5, if there is continuous process improvement and if there is quantitative feedback from the process, and from piloting innovative ideas and technologies. The software processes are at CMM level 5, if there are any process change management, defect prevention and technology change management.
22. Consider the following relational schemas for a library database :
Book (Title, Author, Catalog_no, Publisher, Year, Price)
Collection(Title, Author, Catalog_no) with the following functional dependencies :
I. Title, Author → Catalog_no
II. Catalog_no → Title, Author, Publisher, Year
III. Publisher, Title, Year → Price
Assume (Author, Title) is the key for both schemas. Which one of the following is true ?
(A) Both Book and Collection are in BCNF.
(B) Both Book and Collection are in 3NF.
(C) Book is in 2NF and Collection in 3NF.
(D) Both Book and Collection are in 2NF.
Answer: C
Explanation: Since there is just one functional dependency "Title Author –> Catalog no" and {Author, Title} is the key for collection, the table "Collection" is in BCNF.
Although Catalog no is not a key, and there is a functional relationship "Catalog no –> Title Author Publisher Year", the book is not in BCNF.
Because non-prime attributes (Publisher Year) are transitively reliant on key [Title, Author], the book isn't in 3NF.
Since every non-prime attribute of the table is either reliant on the entire candidate key [Title, Author] or on another non-prime attribute, Book is in 2NF.
Candidate keys in a table book are {Title, Author}, and {Catalog_no}. Publisher, Year, and Place are non-prime attributes in table Book (attributes that do not appear in any candidate key).
23. Specialization Lattice stands for
(A) An entity type can participate as a subclass in only one specialization.
(B) An entity type can participate as a subclass in more than one specialization.
(C) An entity type that can participate in one specialization.
(D) An entity type that can participate in one generalization.
Answer: B
Explanation: Specialization Lattice stands for an entity type can participate as a subclass in more than one specialization.
24. Match the following :
List – I List – II
a. Timeout ordering protocol i. Wait for graph
b. Deadlock prevention ii. Roll back
c. Deadlock detection iii. Wait-die scheme
d. Deadlock recovery iv. Thomas Write Rule
Codes :
a b c d
(A) iv iii i ii
(B) iii ii iv i
(C) ii i iv iii
(D) iii i iv iii
Answer: A
Explanation:
List – I List – II
a. Timeout ordering protocol iv. Thomas Write Rule
b. Deadlock prevention iii. Wait-die scheme
c. Deadlock detection i. Wait for graph
d. Deadlock recovery ii. Roll back
25. Consider the schema R = {S, T, U, V} and the dependencies S → T, T → U, U → V and V → S
If R = (R1 and R2 ) be a decomposition such that R1 ∩ R2 = φ then the decomposition is
(A) not in 2NF
(B) in 2NF but not in 3NF
(C) in 3NF but not in 2NF
(D) in both 2NF and 3NF
Answer: D
Explanation:  denotes that R1 and R2 share a common attribute.
denotes that R1 and R2 share a common attribute.
If we choose a decomposition favourably, such as R1(S, T, U) and R2(U, V), we may claim that the decomposition is lossless because the common attribute is U and the LHS of each FD is a candidate key, so it is in both 2NF and 3NF.
Option (D) is the right answer.



 8+ registered
8+ registered 

