K-means++
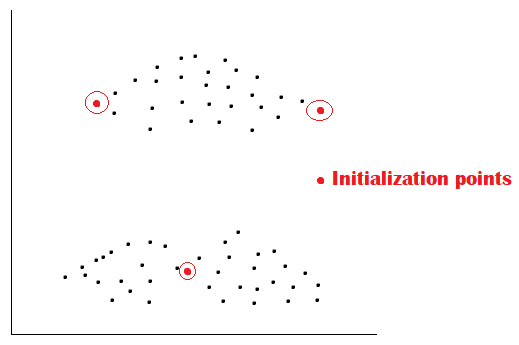
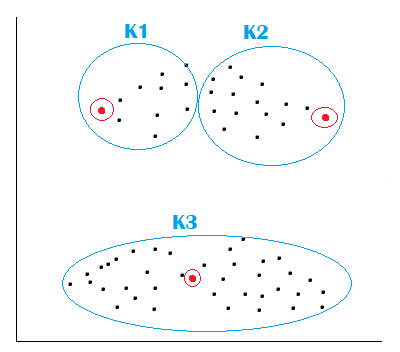
Different initialization points lead to other clusters; this is the problem with the K-means. So we have to choose a method to initialize the centroids better. The concept of K-means++ is introduced, which is used for initialization. The algorithm says that;
- Randomly select the first Centroid.
- For each data point, calculate the distance to the nearest Centroid.
- Select the next Centroid. The probability of choosing the next Centroid is directly proportional to the distance.
- Then Repeat steps 2 and 3 for K centroids.
Here the distance is Euclidean or Manhattan distance.
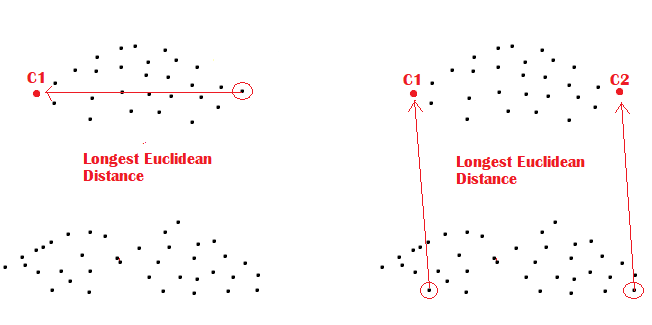
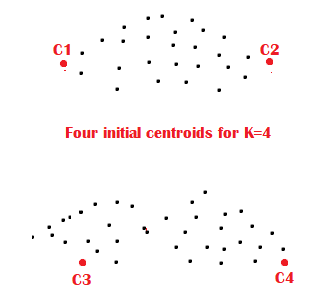
In this way, K-means++ chooses K initial centroids. After selecting the centroids, we can run K-means algorithms on the datasets.
Frequently Asked Questions
Q1) What is the Euclidean distance used in the K-means algorithm?
=>Euclidean distance is the distance measured between pairs of points in n-dimensional space. If there are n coordinates, then the distance between two points p and q is given by-
Euclidean distance = i=1n(pi-qi)2
Q2) What is the Manhattan distance used in the K-means algorithm?
=> Manhattan distance between two points p and q in space is their pairwise absolute difference. If there are n coordinates, then the distance between two points p and q is given by-
i=1n|pi-qi|
Q3) How do we calculate the centroid in the K-means algorithm?
=> For n data points, i th coordinate of centroid is given by
xi = 1npi , where p is individual data points.
Q4) What is the major issue in the implementation of K-means++?
=> K-means++ is computationally expensive to implement as compared to K-means. The run-time for convergence to optimum is drastically reduced for K-means++.
Q5) How does Outliers affect the K-means algorithm?
=>Outlier will cause the Centroid to be displaced from its actual position, or the Outlier might get their clusters instead of being ignored. So we should remove Outliers before clustering.
Key Takeaways
We come to the end of the discussion. There are various exciting clustering algorithms in Unsupervised learning. You can learn them in great detail with hands-on projects from- Link.
Don’t forget to check: Unsupervised Learning and, GCD Euclidean Algorithm.
THANK YOU





























 6+ registered
6+ registered 

