Get a skill gap analysis, personalised roadmap, and AI-powered resume optimisation.
Introduction
You must be familiar with supervised and unsupervised learning in data mining. In supervised learning, the model receives both input and output data. But, in unsupervised learning, the model receives only input data. Supervised learning aims to train the model to predict the outcome when new data is provided.
The K Nearest Neighbour algorithm is a type of supervised learning technique that is used for classification. This article will discuss the K-nearest neighbour algorithm in more detail.
Let’s get started.
Need for K-NN Algorithm
The k-nearest neighbours (KNN) algorithm is a data classification technique that estimates the likelihood that a data point belongs to one of two groups based on the closest data points.
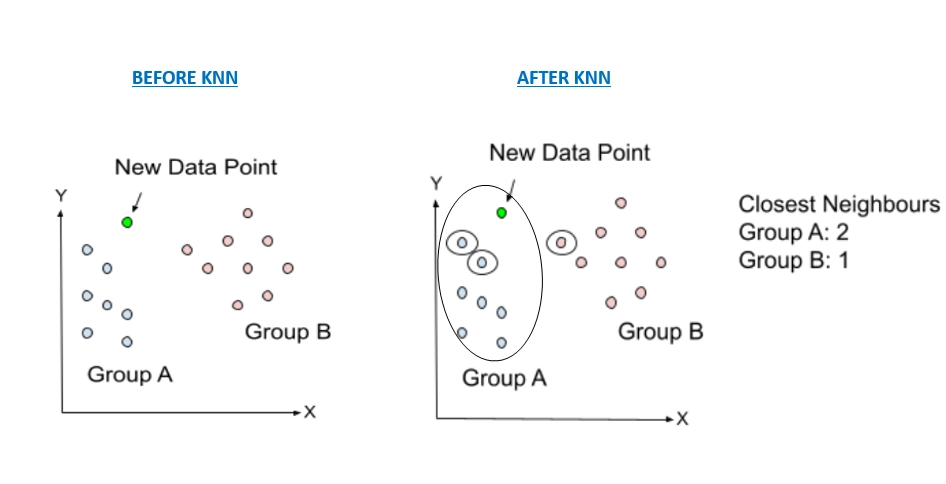
To understand it more clearly, suppose there are two groups, group A and group B containing several data points. Now, we get another new data point, and we are interested in knowing to which group this data point should belong. The most straightforward approach is to use the K-NN classification algorithm to solve this problem.
( Diagram showing the need for K-NN algorithm )
The image shows that the new data point is assigned to Category A based on the distance measure as criteria for classification. Below we will learn how the K-NN algorithm works.
Working
The KNN method is mainly employed as a classifier, as previously stated. Let's look at how KNN classifies unknown data points. Unlike artificial neural network classification, k-nearest neighbours classification is straightforward to understand and implement. It's suitable for scenarios with well-defined or non-linear data points.
Algorithm
The following algorithm can be used to describe how K-NN works:
Decide on the number of neighbours (K).
Determine the Euclidean distance between K neighbours.
Using the obtained Euclidean distance, find the K closest neighbours.
Count the number of data points in each category among these k neighbours.
Assign the new data points to the category with the greatest number of neighbours.
The model is completed.
Example
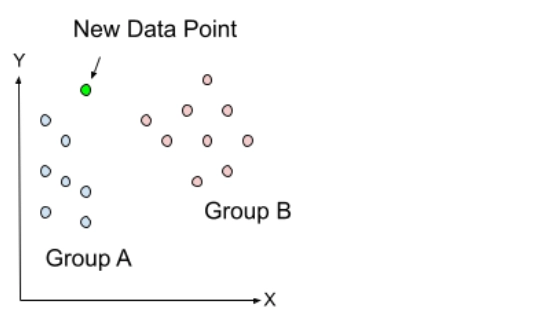
Let's assume we have a new data point that needs to be placed in the appropriate category.
Firstly, we will choose the number of neighbours (the value of k), so we will choose k = 3. We will then calculate the Euclidean distance between the data points. The Euclidean distance is the distance between two points that we learned in geometry. Suppose “m” and “n” are two points in a real line, and the distance between them can be calculated as:
(equation for the distance between two points)
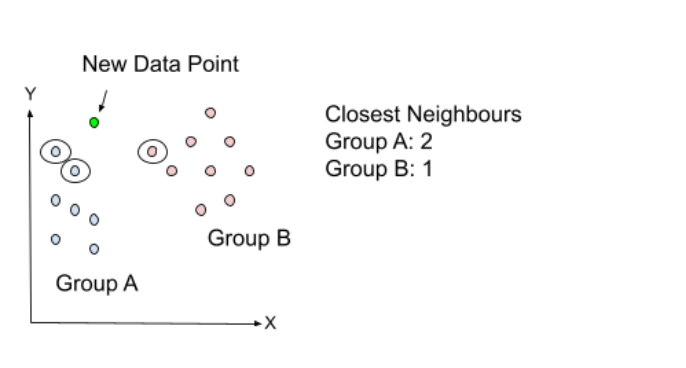
Suppose we found the closest neighbours by computing the Euclidean distance, which gave two closest neighbours in category A and one closest neighbour in category B.
The two closest neighbours are all from category A; hence this new data point must also be from that category.
Implementation
The code below uses the sci-kit-learn library to implement KNN on the iris dataset. Each species of Iris flower includes 50 samples in the Iris dataset (a total of 150). We have sepal length, width, petal length and width for each sample and a species name (class/label).
Step 1(Load the iris dataset and check the data)
First, we need to create an iris Bunch object using the load iris function from the sci-kit-learn datasets module. Then we have to print the data to check if the data has been loaded.
#program for knn classifier iris dataset using sklearn
import numpy as np
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
#importing iris dataset
from sklearn.datasets import load_iris
iris = load_iris()
print(iris.data)
Output
Step 2(Check for the features and target)
Now we can check for all the available attributes in the iris dataset. We have then printed the targets, which are integers representing the iris species:
0: Setosa
1: Versicolor
2: Virginica
In the end, we have printed the target names.
#names of the features
print(iris.feature_names)
#print the target
print(iris.target)
#names of the target_names
print(iris.target_names)
Output
Step 3(Split the dataset into training and testing data)
Because training and testing on the same data is an inefficient way for classification, we partition the data into two sets: training and testing. We use the “train test split” function to split the data. The optional parameter ' test-size determines the split percentage.' The 'random state' parameter ensures that the data is split in the same way each time the programme is executed. Because we're training and testing on distinct sets of data, the testing accuracy will better indicate how well the model will perform on new data.
#split the data into training and testing data
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=3)
#shape of train and test objects
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)
Output
Step 4(Training and Testing the Classifier)
In our example, we've created an instance (“knn”) of the class 'KNeighborsClassifier,' which means we've constructed an object called “knn” that knows how to perform KNN classification once the data is provided. The tuning parameter/hyperparameter (k) is the 'n neighbours' parameter.
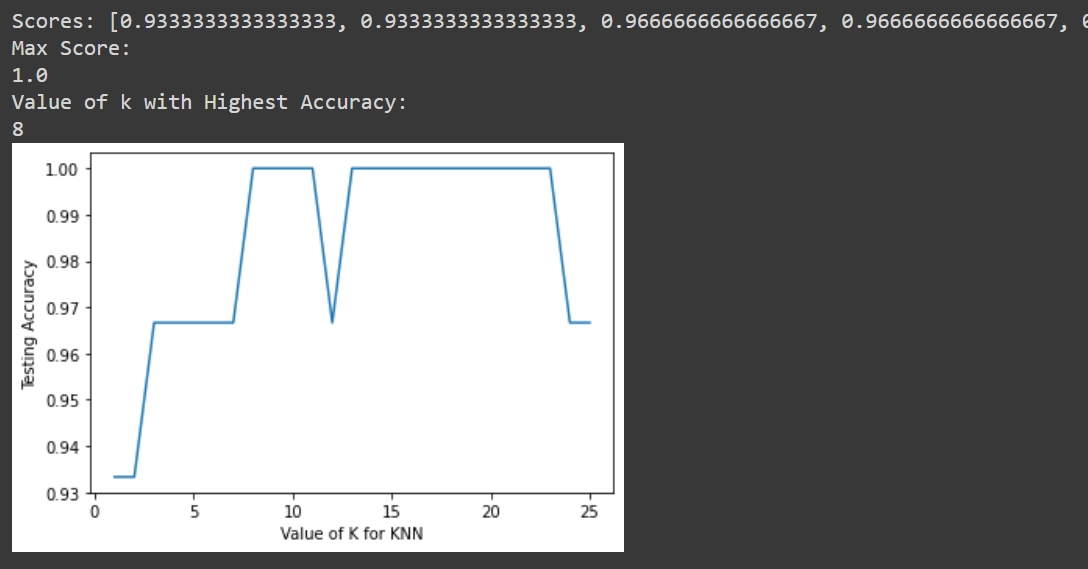
The 'fit' method is used to train the model using training data (X train,y train), while the 'predict' approach is used to test the model using testing data (X test). Because determining the best K value is crucial, we use a for loop to fit and test the model for various K values (from 1 to 25) and keep track of the K-NN's testing accuracy in a variable (scores).
k_range = range(1,26)
scores = []
for k in k_range:
#create a knn classifier
knn = KNeighborsClassifier(n_neighbors=k)
#train the model
knn.fit(X_train, y_train)
#predict the response
y_pred = knn.predict(X_test)
#compute the accuracy of the model
scores.append(knn.score(X_test, y_test))
#print the accuracy
print('Scores:',scores)
#print the highest accuracy
print('Max Score:')
print(max(scores))
#print the value of k with the highest accuracy
print('Value of k with Highest Accuracy:')
print(scores.index(max(scores))+1)
#plot the accuracy
import matplotlib.pyplot as plt
plt.plot(k_range, scores)
plt.xlabel('Value of K for KNN')
plt.ylabel('Testing Accuracy')
plt.show()
Output
Real-World Application of KNN Algorithm
Some real-world applications of the KNN algorithm are:
Agriculture The KNN model is being used to classify the groundwater level dataset in order to forecast future test data records. It could be beneficial in analysing past groundwater levels and forecasting future levels.
Healthcare It is used in healthcare in various ways. For instance, it can predict whether a patient who has been admitted to the hospital for a heart attack will suffer another heart attack. The prediction will be based on the patient's demographics, diet, and clinical data. Using clinical and demographic data, it can determine the risk factors for prostate cancer.
Recommendation system KNN isn't ideal for high-dimensional data, but it's a great starting point for recommendation systems. Netflix, Amazon, YouTube, and a slew of other companies provide individualised recommendations to their customers.
Easy to Implement KNN is simple and intuitive to implement. It doesn’t require a complex model or training process, making it a great choice for quick prototyping or when interpretability is more important than performance.
No Training Required As a lazy learning algorithm, KNN doesn’t involve any training phase. The model simply stores the data and performs computations during prediction, which saves time upfront and makes it adaptable to new data.
Few Hyperparameters KNN has minimal hyperparameters to tune—primarily the value of k and the choice of distance metric. This simplicity reduces the complexity of model selection and tuning compared to other machine learning algorithms.
Flexible for Classification and Regression KNN is versatile and works well for both classification and regression problems. It makes predictions based on the nature of the problem, using the majority class for classification or averaging values for regression.
Disadvantages of the KNN Algorithm
Doesn’t Scale Well KNN becomes increasingly slow as the dataset grows because it calculates the distance from the query point to all other data points. This inefficiency makes it impractical for large-scale or real-time applications.
Curse of Dimensionality In high-dimensional spaces, the distance between points becomes less meaningful, which negatively affects KNN’s performance. It struggles to differentiate between near and far neighbors, leading to a drop in accuracy.
Prone to Overfitting When dealing with high-dimensional data, KNN may overfit by memorizing noise or irrelevant patterns. Without proper dimensionality reduction or feature selection, it may generalize poorly to new, unseen data.
Frequently Asked Questions
What does the letter "K" mean in the KNN Algorithm?
“K” is the number of nearest neighbours you want to use to predict the class of a given item from an unknown dataset.
When should we refrain from using KNN?
It does not perform well with high dimensions. KNN algorithms do not work well with high-dimensional data because calculating the distance between each dimension becomes more complex as the number of dimensions increases.
Are outliers a factor in KNN?
The existence of outliers in the experimental datasets is found to have a negative impact on the kNN algorithm's classification accuracy. An outlier score based on rank difference can be awarded to the points in these datasets by considering the distance and density of their local neighbourhood points.
What is the origin of the name "Lazy Learner" for the KNN Algorithm?
When the KNN algorithm receives the training data, it does not learn or build a model; instead, it simply stores it. Instead of using the training data to find a discriminative function, it uses instance-based learning and only uses the training data when it needs to predict unknown datasets.
Conclusion
In this article, we have extensively discussed the KNN Algorithm and its implementation in Python using the SK-learn library.
We discussed the need for the K-NN algorithm, its working principle, algorithm, and implementation in 4 steps as below:




























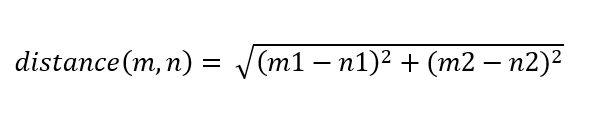





 9+ registered
9+ registered 

