Do you think IIT Guwahati certified course can help you in your career?
Introduction
This article aims to familiarise you with the KMP(Knuth Morris Pratt) string matching algorithm.
We will see how the KMP algorithm makes string search very efficient. Due to its efficiency and usefulness, we use it almost everywhere. Knowingly or unknowingly, we use the KMP algorithm every day.
Let’s see the problem statement in the next section.
What is KMP Algorithm?
The KMP Algorithm stands for Knuth-Morris-Pratt Algorithm. It was created in 1970 by three computer scientists: Donald Knuth, Vaughan Pratt, and James Morris. This algorithm is used to search for a smaller string, called a pattern, inside a larger string, called the text.
In simple words, the text is the full sentence or paragraph, and the pattern is the word or group of letters we want to find. For example, if you are looking for the word “code” in “learn to code fast,” then “learn to code fast” is the text and “code” is the pattern.
What makes KMP powerful is that it avoids checking the same letters again and again. It does this using a helper table called the LPS (Longest Prefix Suffix) array. Because of this smart step, the KMP algorithm runs in O(n + m) time, where n is the length of the text and m is the length of the pattern.
KMP is one of the fastest ways to search for text and is used in software like text editors, search tools, and bioinformatics.
Need for the KMP Algorithm
String-matching is a common task in programming. It is used in many applications like searching words in a document, finding keywords on web pages, or matching DNA sequences. To perform this, basic or naïve algorithms were used earlier, but they had several drawbacks.
Shortcomings of the Naïve String-Matching Algorithm:
Inefficient Backtracking: The naïve approach checks for the pattern at every position in the text. If a mismatch happens, it goes back and starts again from the next position, repeating some comparisons.
Redundant Comparisons: It rechecks characters that were already matched before the mismatch.
Slow on Large Inputs: When the text and pattern are long, the performance becomes poor.
High Time Complexity: It runs in O(n * m) time, where n is the length of the text and m is the length of the pattern.
Not Suitable for Real-Time Applications: Due to its inefficiency, it is not ideal for fast search operations like in search engines or large datasets.
Why KMP Was Introduced
To fix these issues, the KMP algorithm was introduced. It avoids rechecking characters by using a smart pre-processing step with the LPS array. This reduces unnecessary comparisons and runs in O(n + m) time, making it faster and more efficient than the naïve approach.
Problem Statement
We are given a target string “target” and a search string “search”. We have to find out all the possible locations of the search string in the target string. Then we have to return the index of all the occurrences of the search string in the target string.
Consider n= length(search) and m= length(target).
The overlapping of the answers is also allowed. See example 2 below for a clear understanding.
Note: Throughout this article, we will be using the term “KMP”, a short form for Knuth Morris Pratt and “Lps” which stands for the longest proper prefix which is also a suffix.
Now, let us see a few of the examples of the problem statement:
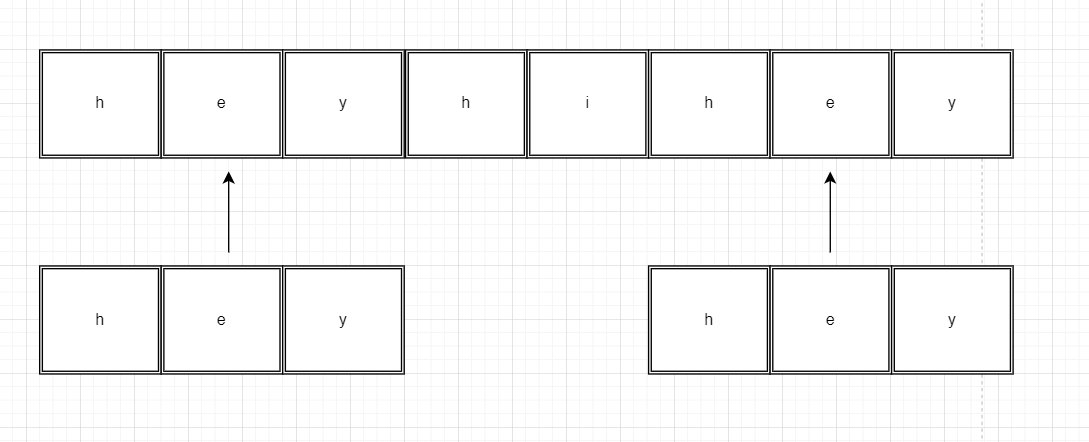
1. target= ”heyhihey” search=”hey”
Output: [1,6]
Explanation: The search key “hey” occurs twice in the target key. It appears on position 1 and position 6 of the target. Thus we have returned array [1,6]. See the below figure for a better understanding.
Figure I:”hey” matches at index 1 and at index 6.
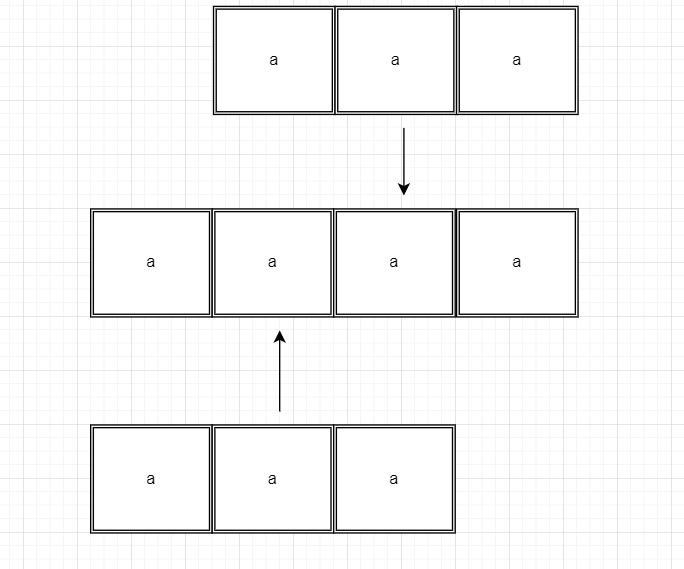
2. target=”aaaa” search = “aaa”
Output: [1,2]
Explanation: The search key occurs on index 1 and index 2. Here we have to note that the second “a” and the third “a” is counted twice. Thus the answers of index 1 and index 2 overlap, i.e. one character can be in more than one answer. See the below figure for better understanding.
Figure II: The positions of “aaa” in “aaaa”
3. target=”abcdefghij” search = “abcj”
Output: []
Explanation: The search string is not present in the target string.
You can see the naive approach for the string matching algorithm here but it is not efficient as the time complexity is O(n*m), where m=length(search) and n=length(target). Let us learn in this blog how with the help of the KMP algorithm, we can achieve a linear time complexity.
Approach
For the algorithm, we must first precompute the lps_array.
Then using the LPS array, we will search the “search” string in the “target” string. We do the following, Whenever a match is found, we move ahead and whenever a mismatch occurs, we find the last index of the search string which matches with the target string using the lps_array.
Steps to find LPS array
1. First, we make an LPS array of size m where m=length(search) to store integers. LPS[i] is used to get the last longest matching. The LPS array is initialised with 0.
2. We make previous = 0. The previous variable tells us the last longest proper prefix which was also a suffix.
3. As we are looking for the proper prefix we start searching from index 1 to the last index of the search array.
4. We compare search[current index] with the search[previous]. If they match we increment the previous and current index pointers and also update lps[current index] as previous+1.
5. If they don’t match we do the following:
i) If the previous variable is equal to 0, this means that there is no suffix that ends at search[current index] and is also a proper prefix in search. Thus we make lps[current index] = 0.
ii) If the previous variable is not equal to 0, this means that there was a previous match. Thus we make previous= lps[previous-1].
6. At last, we return the LPS array.
Note: LPS[i] means the longest proper prefix which is also a suffix for the substring search[0:i]. The whole string can’t be lps because we are looking for a proper prefix.
Let us write a code to find the LPS array in python.
def get_lps(search):
# lps array is the longest proper prefix which is also a suffix
lps_arr=[0 for i in range(len(search))]
# previous is the last longest proper prefix which is also a suffix
previous=0
# Here we are checking proper prefix so that we start with the index 1
# as the prefix can't be itself
curr_index=1
while curr_index<len(lps_arr):
if search[curr_index]==search[previous]:
"""This means that we have found a match for the last longest lps
and the current prefix
Thus we update the lps array"""
previous+=1
lps_arr[curr_index]=previous
curr_index+=1
elif previous==0:
"""This means that we have not found a match for the current prefix with the
last lps.
As previous=0 then there does not exist previous longest lps."""
# no lps[curr index] exist so lps[curr_index]=0
lps_arr[curr_index]=0
curr_index+=1
else:
# we replace current_index
previous=lps_arr[previous-1]
return lps_arr
search="abcdabcabcd"
answer=get_lps(search)
print(answer)
You can also try this code with Online Python Compiler
1. First, we get the lps_array by calling the function get_lps and passing search as an argument.
2. We then make two variables, namely search_iter and target_iter, for iterating search and target respectively.
3. Whenever search[search iter] equals target[target iter], we increment both of them for comparing further indices.
4. When search iterator equals search.length, this means that the search string is found in the target at target_iter- search_iter. Thus we print that the search is found in target at the found index.
5. If they do not match, we update the search_iter with the last index that matches with the target[target_iter] using the precomputed LPS array.
6. Thus, we print all the indices where the search is found in the target string in the above way.
Having understood the LPS array formation, we can easily understand the KMP algorithm.
Pseudocode for KMP algorithm
DEFINE FUNCTION get_lps(search):
lps_arr: array of length len(search) initialized with 0
previous=0
curr_index=1
WHILE curr_index is length than the length of (lps_arr):
IF search[curr_index] is equal to search[previous]:
previous+=1
set lps_arr[curr_index] as previous
curr_index+=1
ELSEIF previous==0:
lps_arr[curr_index]=0
curr_index+=1
ELSE:
previous=lps_arr[previous-1]
RETURN lps_arr
DEFINE FUNCTION kmp_algo(search,target):
we get lps array from get_lps function
i.e. lps= get_lps(search)
search_iter=0
target_iter=0
WHILE target_iter<lenght of the target:
IF search[search_iter] is equal to target[target_iter]:
search_iter+=1
target_iter+=1
IF search_iter is equal to the length of (search):
OUTPUT("Search found at index:",target_iter-search_iter+1)
search_iter=lps[search_iter-1]
ELSEIF target_iter is less than the length of (target):
IF target[target_iter]!=search[search_iter]:
IF search_iter!=0:
search_iter=lps[search_iter-1]
ELSE:
target_iter+=1
Code in Python
def get_lps(search):
# lps array is the longest proper prefix which is also a suffix
lps_arr=[0 for i in range(len(search))]
# previous is the last longest proper prefix which is also a suffix
previous=0
# Here we are checking proper prefix so that we start with the index 1
# as the prefix can't be itself
curr_index=1
while curr_index<len(lps_arr):
if search[curr_index]==search[previous]:
"""This means that we have found a match for the last longest lps
and the current prefix
Thus we update the lps array"""
previous+=1
lps_arr[curr_index]=previous
curr_index+=1
elif previous==0:
"""This means that we have not found a match for the current prefix with the
last lps.
As previous=0 then there does not exist previous longest lps."""
# no lps[curr index] exist so lps[curr_index]=0
lps_arr[curr_index]=0
curr_index+=1
else:
# we replace current_index
previous=lps_arr[previous-1]
return lps_arr
def kmp_algo(search,target):
lps=get_lps(search)
search_iter=0 # iterates indices over search
target_iter=0 # iterates indices over target
while target_iter<len(target):
if search[search_iter]==target[target_iter]:
search_iter+=1
target_iter+=1
# as they match we move to the next index
if search_iter==len(search):
# this means that whole of the search string is matched in target
# thus they match at target_iter-search_iter+1(1 added as we print 1 based indexing)
print("Search found at index:",target_iter-search_iter+1)
""" now as they matched we check for the last match of the target[target_iter] in the search string
This is because in some cases like search="aaa" target ="aaaa"
When the search is matched. Then for the next query we have to check for the last search that matches with the target.
This is because there are two answers i.e. [1,2].
So when search[2]=target[2] matches we have to again check for search[2] with target[3] for the next match.
"""
search_iter=lps[search_iter-1]
elif target_iter<len(target):
if target[target_iter]!=search[search_iter]:
if search_iter!=0:
# we update the lps to the last matched
search_iter=lps[search_iter-1]
else:
# if they don't match at all we move to the next index
target_iter+=1
target = "abcdabcabcd"
search = "abcd"
kmp_algo(search, target)
You can also try this code with Online Python Compiler
Check out this video for better conceptual knowledge and implementation of the code.
KMP Algorithm vs Naïve Algorithm
Performance Comparison
The KMP algorithm runs in O(n + m) time, where n is the length of the text and m is the length of the pattern. On the other hand, the Naïve algorithm runs in O(n * m) time in the worst case. This makes KMP more efficient, especially when working with large texts or patterns.
Unlike the naïve method, KMP avoids unnecessary backtracking by using the LPS (Longest Prefix Suffix) array. This helps skip repeated comparisons, making the algorithm faster.
Example:
Let’s say you want to find "abc" in the text "aaaabcabc".
Naïve will compare each character, even repeating checks after every mismatch.
KMP will skip matched characters intelligently using LPS.
This difference becomes noticeable when working with long strings or multiple patterns.
Use Case Differences
The Naïve algorithm is simple and works well for short texts or patterns where performance is not a concern. It's great for basic string search tasks like small form validations or simple keyword checks.
But in cases where the text is long or the pattern search is repeated many times, KMP is a better choice. It saves time and system resources, especially in real-time applications.
Use KMP when:
You deal with large datasets (e.g., eBooks, logs).
The pattern is reused (e.g., repeated searches in text).
Industry Use Cases:
Search tools like Ctrl+F in text editors.
DNA pattern search in bioinformatics tools.
Syntax recognition in compilers and interpreters.
Spam filters matching text against known spam patterns.
Real-World Applications of KMP Algorithm
The KMP algorithm plays an important role in many real-world software applications that need fast and reliable text searching.
Text Editors (e.g., Sublime Text, Notepad++): KMP powers the "Find" or "Find and Replace" feature by quickly locating patterns within large documents.
Compilers (e.g., GCC): KMP helps match predefined tokens or keywords while scanning source code, improving the speed of lexical analysis.
Search Engines (e.g., Google, Bing): KMP allows fast scanning of text data, making it easier to match user queries with indexed content.
Bioinformatics (e.g., BLAST Tools): DNA and protein sequences often need to be matched with known patterns. KMP improves performance by avoiding repeated scans.
Plagiarism Detection and Spam Filters: Tools like Turnitin and spam filters use KMP-like techniques to match chunks of text against large databases in real time.
These examples show how the KMP algorithm helps make modern software faster and more efficient in handling large-scale pattern matching.
Frequently Asked Questions
Where is the KMP algorithm used?
The algorithm is used in Gmail, Microsoft word, google docs, Google sheets and browsers for string search, in various text editors and databases for string searching and matching. KMP is also inbuilt in python3.
What are the other similar algorithms?
KMP is a prefix search algorithm. Another algorithm, z-function, also searches text in a target string. Both of them have the same time and space complexity. But when we want to find the first occurrence of the search string in the target string, KMP uses less space than the z-algorithm. There are also algorithms like Boyer Moore and Rabin Karp. The space complexity for Rabin Karp is O(1).
Conclusion
The article helps us understand the KMP string matching algorithm in python3. You can also copy the code and run it on your system on multiple inputs to understand the approach better.
We precompute the LPS array. Then using that array, we search the search string in the target string.





























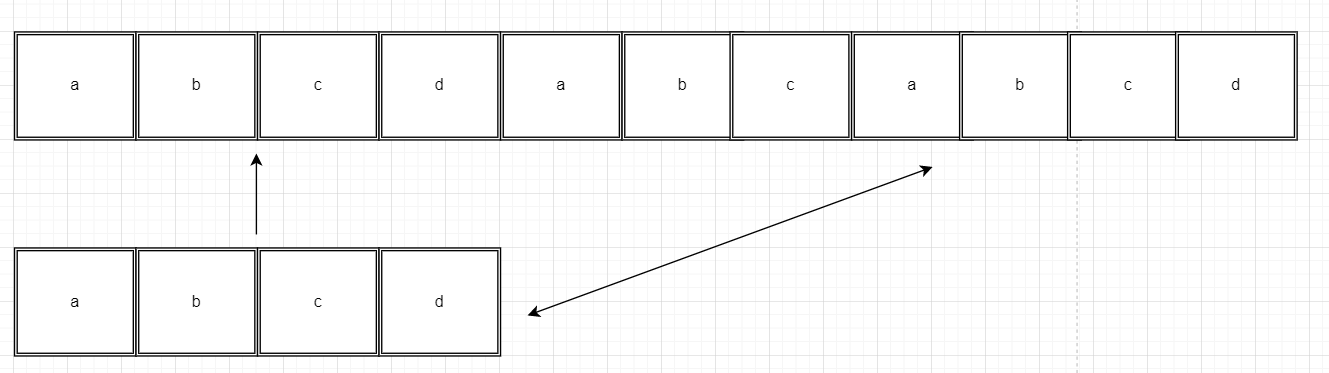
![search[0] = search[4].](https://files.codingninjas.in/article_images/kmp-string-matching-algorithm-2-1642483234.webp)
![search[0] = search[4] and search[1]=search[5].](https://files.codingninjas.in/article_images/kmp-string-matching-algorithm-3-1642483235.webp)
![search[7]=search[0]](https://files.codingninjas.in/article_images/kmp-string-matching-algorithm-4-1642483235.webp)


 9+ registered
9+ registered 

