Do you think IIT Guwahati certified course can help you in your career?
Introduction
Pandas is a Python library containing high-level data structures and tools created to help Python programmers perform powerful data analysis. The ultimate purpose of pandas is to help us quickly discover information in data. The development of pandas was begun in 2008 by Wes McKinney; it was open-sourced in 2009.
Pandas is currently supported and actively developed by various organizations and contributors. Pandas was initially designed with finance in mind, specifically with its ability around time series data manipulation and processing historical stock information. In this article, we will learn about Labels in Pandas Series.
Labels in Pandas Series
Each data point in the Pandas Series has a unique identifier or index the labels provide. These labels enable effective data retrieval, manipulation, and alignment when performing operations between multiple Series objects. Integers, strings, and other hashable objects can all be used as labels.
A fundamental data structure called a Pandas Series resembles a one-dimensional labeled array. It is a cornerstone of Python's data analysis architecture. A Series element each has a label that serves as an index. Series are adaptable for tasks involving data manipulation because they can hold various data types.
Several motives of Labels in the Pandas Series
The Importance of labels is as follows:
Efficient Data Retrieval: Labels allow the smooth retrieval of specific records factors inside a Series.
Data Manipulation: They facilitate modifying information by referencing factors and using labels.
Alignment: During operations related to multiple Series, facts alignment primarily based on labels ensures consistency and forestalls misalignment errors.
Clarity: Labels offer context, making it less complicated for information analysts and scientists to understand and paint with the information.
Creating Labels
We can create labels in a Pandas Series using various methods given below:
Manual Label Assignment
import pandas as pd
# Create a Pandas Series with data and labels
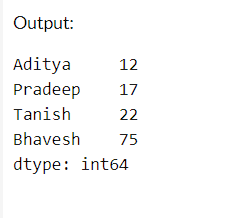
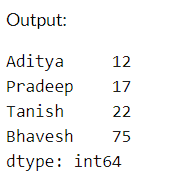
data = [12, 17, 22, 75]
labels = ['Aditya', 'Pradeep', 'Tanish', 'Bhavesh']
series = pd.Series(data, index=labels)
# Print the Pandas Series
print(series)
Output:
Explanation:
We create a Pandas Series with custom labels and data associated with them.
Using Default Numeric Index
import pandas as pd
# Create a Pandas Series with data
data = [12, 17, 22, 75]
# Create a Series using the data
series = pd.Series(data)
# Print the Pandas Series
print(series)
Output:
Explanation:
A Series is created with default numeric labels primarily based on the position of the data within the listing.
Date-based Labels
import pandas as pd
import datetime
# Create data and dates lists
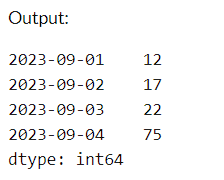
data = [12, 17, 22, 75]
dates = [datetime.date(2023, 9, 1), datetime.date(2023, 9, 2), datetime.date(2023, 9, 3), datetime.date(2023, 9, 4)]
# Create a Pandas Series with data and custom date indices
series = pd.Series(data, index=dates)
# Print the Pandas Series
print(series)
Output:
Explanation:
This Series uses dates as labels associated with the provided data.
Using Python Range
import pandas as pd
# Create data and labels lists
data = [12, 17, 22, 75]
labels = list(range(1, 5))
# Create a Pandas Series with data and custom numeric indices
series = pd.Series(data, index=labels)
# Print the Pandas Series
print(series)
Output:
Explanation:
Labels are created using a Python range, and those labels are connected to the data.
Converting a Dictionary to a Series
import pandas as pd
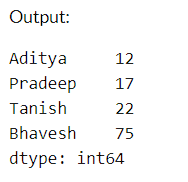
# Create a dictionary with names as keys and corresponding values
data_dict = {'Aditya': 12, 'Pradeep': 17, 'Tanish': 22, 'Bhavesh': 75}
# Create a Pandas Series using the dictionary
series = pd.Series(data_dict)
# Print the Pandas Series
print(series)
Output:
Explanation:
A Series is created by changing a dictionary, in which dictionary keys grow to be labels linked to their respective values.
Accessing Labels Using Label
Using Square Brackets ([ ])
import pandas as pd
# Create a dictionary with names as keys and corresponding values
data_dict = {'Aditya': 12, 'Pradeep': 17, 'Tanish': 22, 'Bhavesh': 75}
# Create a Pandas Series using the dictionary
series = pd.Series(data_dict)
# Access and print the value at the 'Aditya' index
value_at_Aditya = series['Aditya']
print(value_at_Aditya)
Output:
Explanation:
We access data in a Series by specifying a label inside square brackets, in this case, the records associated with 'Aditya.'
Using .loc[ ] Indexer
import pandas as pd
# Create a dictionary with names as keys and corresponding values
data_dict = {'Aditya': 12, 'Pradeep': 17, 'Tanish': 22, 'Bhavesh': 75}
# Create a Pandas Series using the dictionary
series = pd.Series(data_dict)
# Access and print the value at the 'Pradeep' label using .loc
value_at_Pradeep = series.loc['Pradeep']
print(value_at_Pradeep)
Output:
Explanation:
The .Loc[] indexer is used to get the right of entry to statistics by way of label, mainly retrieving the cost associated with the label 'Pradeep.'
Label-based Slicing
import pandas as pd
# Create a dictionary with names as keys and corresponding values
data_dict = {'Aditya': 12, 'Pradeep': 17, 'Tanish': 22, 'Bhavesh': 75}
# Create a Pandas Series using the dictionary
series = pd.Series(data_dict)
# Select a subset of the Series from 'Pradeep' to 'Bhavesh' using label-based slicing
subset = series['Pradeep':'Bhavesh']
# Print the subset of the Series
print(subset)
Output:
Explanation:
We slice the Series by using specifying various labels (''Pradeep'' to ''Bhavesh') and get a subset of the facts.
Conditional Selection with Labels
import pandas as pd
# Create a dictionary with names as keys and corresponding values
data_dict = {'Aditya': 12, 'Pradeep': 17, 'Tanish': 22, 'Bhavesh': 75}
# Create a Pandas Series using the dictionary
series = pd.Series(data_dict)
# Select values from the Series that are greater than 25
result = series[series > 25]
# Print the result
print(result)
Output:
Explanation:
Data is selected primarily based on a condition (values more than 25) the use of boolean indexing with labels.
Key/Value Objects as Series
import pandas as pd
# Create a dictionary with names as keys and corresponding values
data_dict = {'Aditya': 12, 'Pradeep': 17, 'Tanish': 22, 'Bhavesh': 75}
# Create a Pandas Series using the dictionary
series = pd.Series(data_dict)
# Print the Pandas Series
print(series)
Output:
Explanation:
A Pandas Series is created using a dictionary, in which keys come to be labels, and values end up the data within the Series.
Frequently Asked Questions
How can we reset the index of a Pandas Series?
The .reset_index() method allows the reset of a Series index. The old index will become a new column, and a new Series will be created with a default numeric index.
Can labels in a Pandas Series be non-unique?
Since they act as indices, labels in a Pandas Series should ideally be unique. Non-unique labels may cause unexpected behavior when accessing and manipulating data.
What are some common methods to handle missing labels in Pandas Series?
You can remove rows with missing labels using .dropna() and use .fillna() to replace missing values with specific ones.
Conclusion
In this article, we learn about Labels in Pandas Series. We also learn about Several motives of Labels in the Pandas Series. We concluded the article by Creating Labels, Accessing Labels Using Label and Key/Value Objects as Series.






























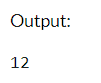





 8+ registered
8+ registered 

