


























Introduction
Data services and tools for organizing big data collect, verify, and assemble various big data elements into contextualized collections. Because big data is massive, methods for processing it efficiently and seamlessly have evolved. One of the most widely used techniques is MapReduce. To conclude, many of these organizing data services are MapReduce engines specifically designed to optimize the organization of large data streams.
In reality, organizing data services is just an ecosystem of tools and technologies used to collect and arrange data in preparation for further processing. As a result, the tools must provide integration, translation, standardization, and scaling. This blog goes into detail about some of the technologies of this layer.
Distributed file system
We frequently work with several clusters (computers) in Big Data. One of the primary benefits of Big Data is that it extends beyond the capacity of a single, compelling server with exceptionally high computational power. The entire concept of Big Data is to distribute data over several clusters and process information using the computing capabilities of each group (node).
A distributed file system (DFS) is spread over several file servers and locations.
- It enables applications to access and save discrete data in the same way they do in local files.
- It also allows the user to access files from other systems.
- It enables network users to communicate information and files in a controlled and authorized way. Despite this, the servers have total control over the data and allow users to access it.
- The primary purpose of DFS is to allow users of physically dispersed systems to exchange resources and information via the Common File System.
- It's a file system that is included with most operating systems. Its setup is a collection of workstations and mainframes linked by a LAN.
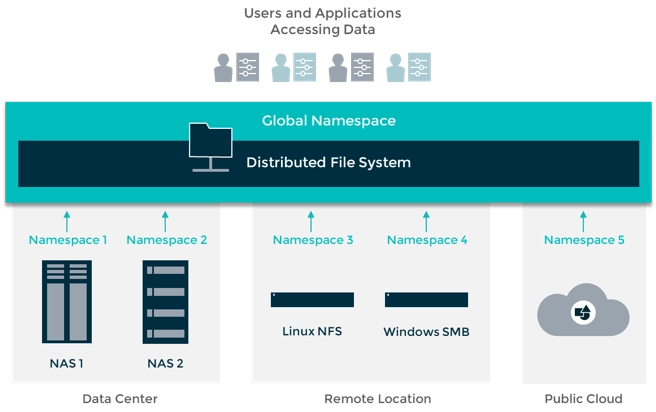
Source: DataCore
Advantages of Distributed File Systems
The following are the primary benefits of a distributed file system:
1. Scalability: By adding extra racks or clusters to your system, you can scale up your infrastructure.
2. Fault Tolerance: Data replication will aid in fault tolerance if the Cluster fails, the Rack fails or is unplugged from the network, or if a job fails or has to be restarted.
3. High Concurrency: Use each node's computational capability to process several client requests (in parallel) simultaneously.
Hadoop Distributed File System
HDFS is a DFS that runs on commodity hardware and manages massive data collections. It is used to increase the number of nodes in a single Apache Hadoop cluster to hundreds (or even thousands). HDFS is one of the three critical components of Apache Hadoop, along with MapReduce and YARN.
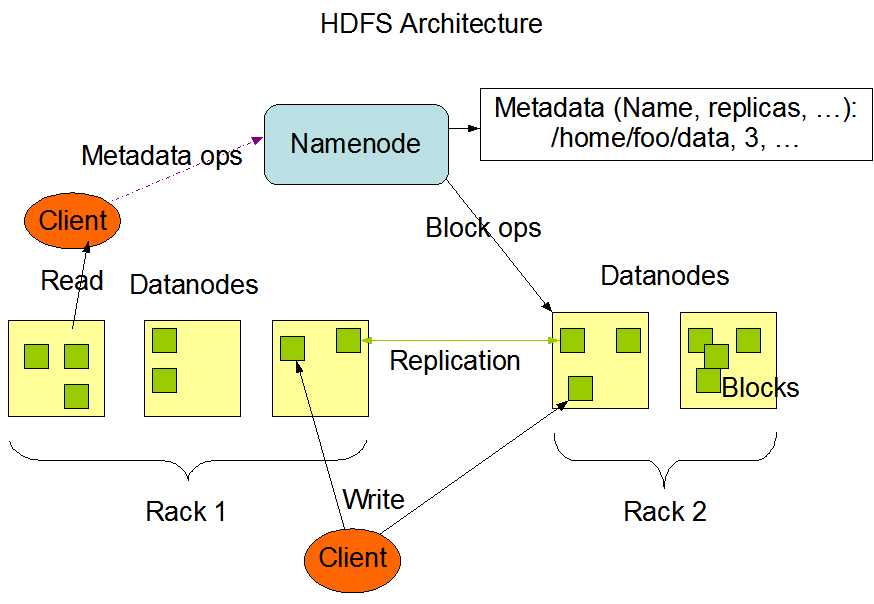
Source:Apache


 8+ registered
8+ registered 

