Do you think IIT Guwahati certified course can help you in your career?
Introduction
Lexical analyzer generator or Lex is a program designed to generate scanners, also known as tokenizers, to recognize lexical patterns in text. It is intended primarily for Unix-based systems. Eric Schmidt and Mike Lesk initially developed the code for Lex.
A Lex(lexical analyzer generator) is a program that generates a lexical analyzer. We use it with the YACC(Yet Another Compiler Compiler) parser generator. The lexical analyzer is a program that converts an input stream into a stream of tokens. It reads the input stream and makes the source code as output by implementing the C program's lexical analyzer.
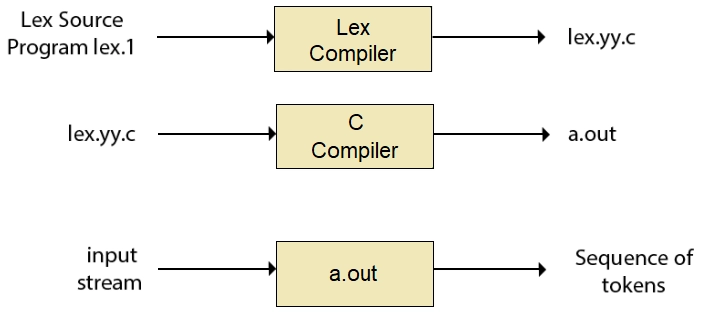
Firstly lexical analyzer makes a program lex.1 in the Lex language. Then Lex compiler runs the lex.1 program and makes a C program lex.yy.c. Finally, the C compiler runs the lex.yy.c program and produces an object program a.out. Here, a.out is a lexical analyzer that transforms an input stream into a sequence of tokens.
Lex file format
A Lex program is categorized into three sections by %% delimiters. The formal Lex source is as follows:
{ definitions } contains declarations of constant, variable, and regular definitions. The { rules } define the statement of form p1 {action1} p2 {action2} ... pn {action}. Pi represents the regular expression, and action1 describes the lexical analyzer's actions when pattern pi matches a lexeme.
{ user subroutines } are auxiliary procedures required by the actions. The subroutine can be packed with the lexical analyzer and compiled separately.
Conflict Resolution
We have indicated the two rules that Lex uses to decide on the proper lexeme to select when several prefixes of the input match one or more patterns:
Always prefer a longer prefix to a shorter prefix.
Pick the pattern listed first in the Lex program if the longest possible prefix corresponds to two or more patterns.
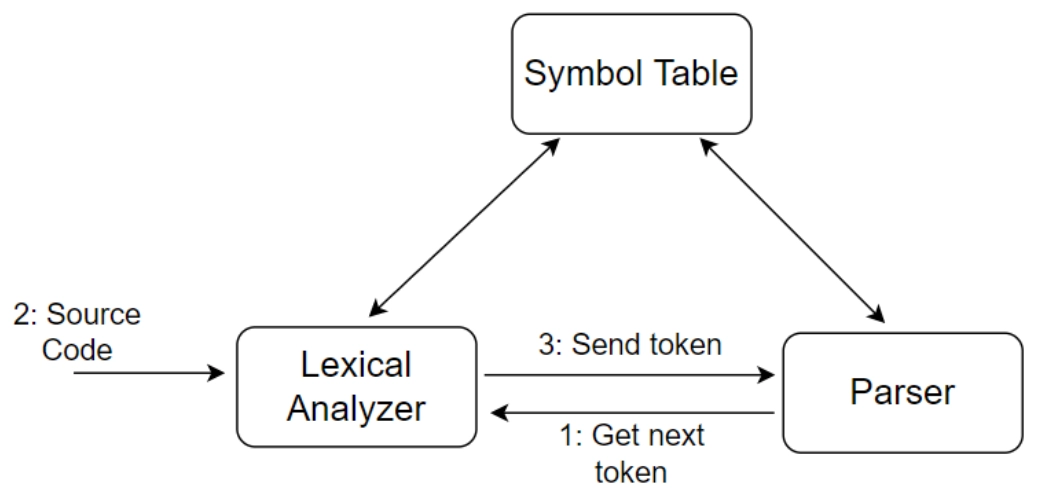
The lexical analyzer scans the whole source code and then identifies and processes all the tokens one by one. So here is the flow chart of the working of the lexical analyzer.
Lexical Analyzer Architecture
The Lookahead Operator
Lex automatically reads one character forth of the last character that creates the selected lexeme and then rejects the input, so only the lexeme itself gets consumed from the input. However, sometimes, we want a particular pattern to be matched to the input only when certain other characters follow it. Then, we may use a slash in a pattern to indicate the end of the part of the pattern that matches the lexeme. What follows is a different pattern than we must match before deciding that we noticed the token in question, but what matches this second pattern is not part of the lexeme.
For example:
The Lookahead operator is the addition operator read by lex to distinguish different patterns for a token. A lexical analyzer is used to read one character ahead of a valid lexeme and then retracts to produce a token.
In some languages, keywords are not reserved. So the statements
IF (A, B) = 10 and IF(condition) THEN
results in conflict whether to produce IF as an array name or a keyword. To resolve this, the lex rule for keyword IF can be written as,
IF/\ (.* \) {
letter }
Frequently Asked Questions
What is a lexer generator in compiler design?
Lexical analyzer generator or Lex is a program designed to generate scanners, also known as tokenizers, recognizing lexical patterns in text. It is intended primarily for Unix-based systems.
What does a lexer do?
The lexer turns a meaningless string into a flat list of things like "number literal", "string literal", "identifier" or "operator". It can do things like recognizing reserved identifiers (i.e., keywords) and discarding whitespace. Formally, a lexer recognizes some set of Regular languages.
What is the difference between lexer and parser?
When a lexer identifies a character sequence constituting a valid number, it can convert it to its binary value and store it with the "number" token. Similarly, when a parser recognizes an expression, it can compute its value and keep it with the "expression" node of the syntax tree.
What is lexer grammar?
A lexer is a recognizer that draws input symbols from a character stream. The lexer grammars result in a subclass of this object. A Lexer object uses simplified match() and error recovery tools in the interest of speed.
What is the difference between tokenizer, lexer, and parser?
A tokenizer splits a stream of text into tokens, usually by looking for whitespace (spaces, tabs, newlines).
A lexer is a tokenizer, but it usually attaches extra context to the tokens. This token is a number that is a string literal. The other token is an equality operator.
A parser takes the stream of tokens from the lexer and turns it into an abstract syntax tree(AST), usually representing the program represented by the original text.
Conclusion
This article teaches about Lexer and Lexer Generators. We also discussed the characteristics, benefits, and applications of the Lexer and Lexer Generators in compiler design.





























 9+ registered
9+ registered 

