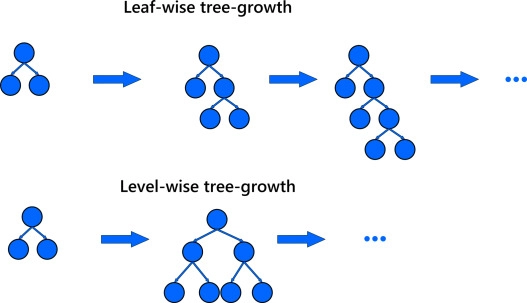
Leaf-wise vs Level-wise
There are two ways to compute the trees; the first is level-wise, and the other is leaf-wise. In the level-wise method, the tree grows level by level; here, each node splits the data prioritizing and nodes closer to the tree's root.
In the leaf-wise method, the tree grows by splitting the data at the nodes with the most tremendous loss change.
The primary difference between the two is that the Level-wise tree is balanced, whereas the leaf-wise tree is unbalanced.
Source: Link
LightGBM Architecture
The LightGBM grows the tree based on the leaf-wise technique. The leaf is chosen based on the maximum loss to grow. The leaf-wise algorithm has a lesser loss than the level-wise tree because the leaf is fixed. Therefore, the leaf-wise tree growth increases the model's complexity and sometimes leads to overfitting in small datasets.
The LightGBM algorithm targets to reduce the complexity with the help of two techniques, namely Gradient-Based One Side Sampling and Exclusive Feature Bundling.
GOSS(Gradient-Based One Side Sampling):
Gradient-Based One Side Sampling, as the name suggests, is the technique to downsample the instance based on the gradient. You would know that having a higher gradient means that samples are undertrained and those with low gradient are well trained. Therefore, the gradient-based one-sided sampling preserves the higher gradients cases and performs random sampling on instances with smaller gradients.

EFB(Exclusive Feature Bundling)
The LightGBM tree is formed by understanding the data and features. Therefore, to speed up the tree learning, LightGBM downsamples the element with the help of Exclusive Feature Bundling. It picks out the mutually exclusive features and bundles them into a single component to minimize the complexity.

Source: Link
Applications of LightGBM
- It can be used for classification and regression problems
- Cross-entropy using the log loss objective function
- LambdaRank- a method in which ranking is transformed into classification r regression problem
Advantages of LightGBM
- Fast training speed and higher efficiency
- Better accuracy than any other boosting algorithm
- Require less memory
- Compatible with large datasets
Frequently Asked Questions
How is LightGBM so fast?
LightGBM achieves the speed by downsampling the features and speeding up tree learning. It is done with the help of exclusive bunding features.
What is N_estimators LightGBM?
n_estimators are the Number of boosted trees to fit.
Is LightGBM better than XGBoost?
Light GBM is almost 7 times quicker than XGBOOST, hence a much better approach when dealing with large datasets in limited-time competitions.
Conclusion
LightGBM is a practical boosting framework that uses leaf-wise tree-based growth. This article gave an in-depth understanding of LightGBM, its architecture, the two methods by which it processes, its application, and its advantages. To build a career in Data Science? Check out our industry-oriented machine learning course curated by our faculty from Stanford University and Industry experts.






























 6+ registered
6+ registered 

