


























Introduction
We will be studying Linear Classification as well as Non-Linear Classification.
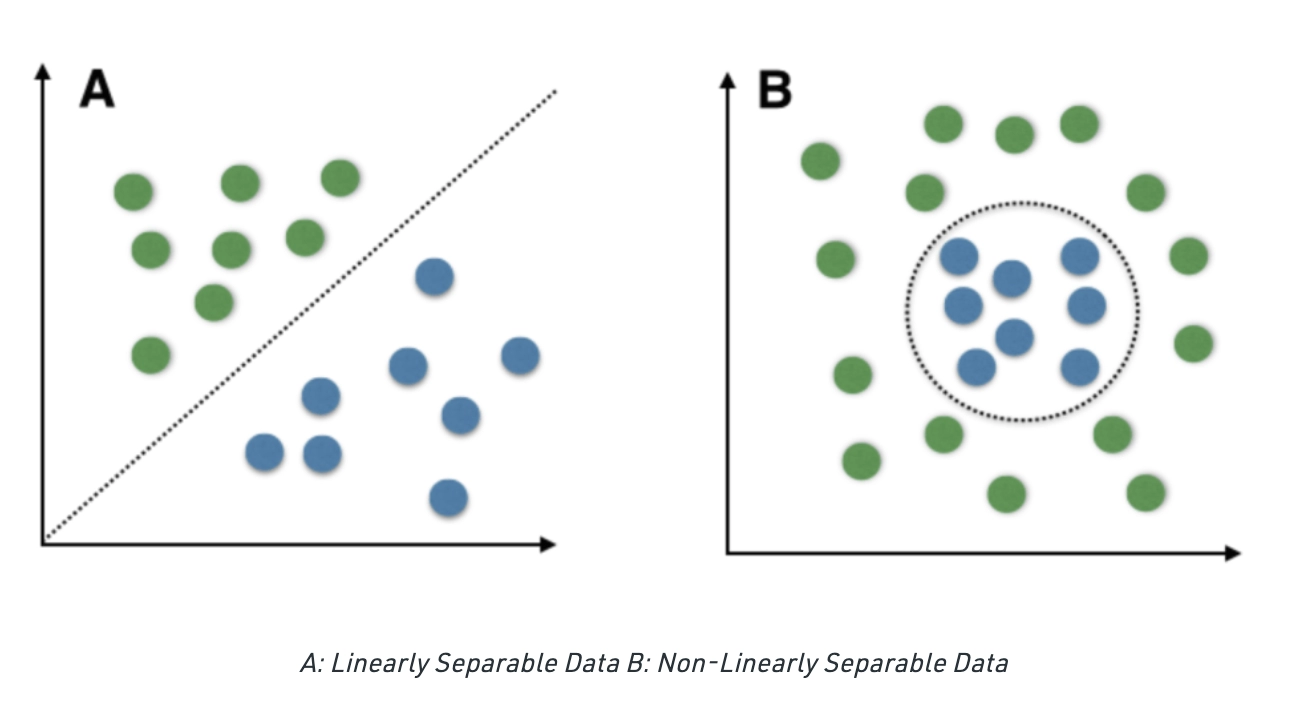
Linear Classification refers to categorizing a set of data points to a discrete class based on a linear combination of its explanatory variables. On the other hand, Non-Linear Classification refers to separating those instances that are not linearly separable.
A linear classifier is often used when classification speed is a priority as linear classifiers are known for being the fastest classifiers especially when the input data is sparse. It classifies large datasets quickly and accurately. On the other hand, Nonlinear classifiers are like detectives who can solve complex cases. It sorts data that doesn't follow straight patterns, like grouping things that don't fit on a simple line.
What is Linear Classification?
→ Linear Classification refers to categorizing a set of data points into a discrete class based on a linear combination of its explanatory variables.
→ Some of the classifiers that use linear functions to separate classes are Linear Discriminant Classifiers, Naive Bayes, Logistic Regression, Perceptron, and SVM (linear kernel).
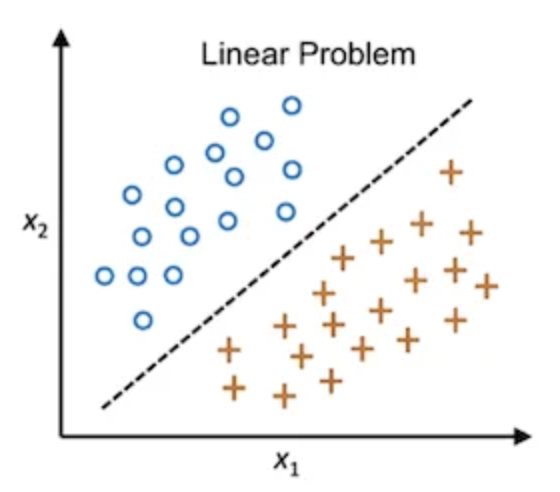
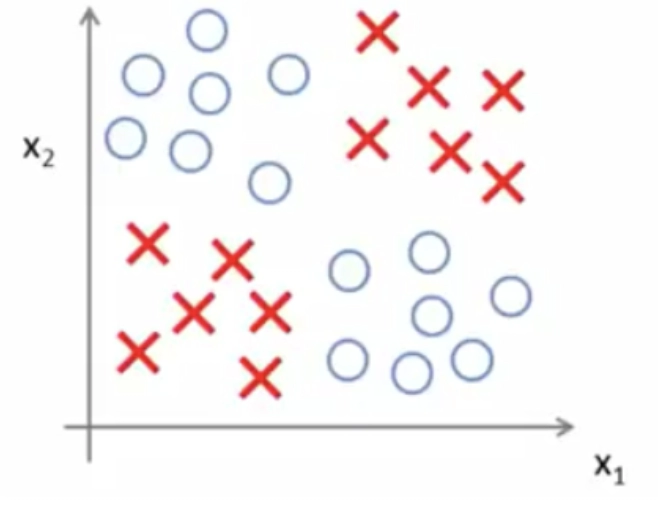
→ In the figure above, we have two classes, namely 'O' and '+.' To differentiate between the two classes, an arbitrary line is drawn, ensuring that both classes are on distinct sides.
→ Since we can tell one class apart from the other, these classes are called ‘linearly separable.’
→ However, an infinite number of lines can be drawn to distinguish the two classes.
→ The exact location of this plane/hyperplane depends on the type of the linear classifier.
Linear Discriminant Classifier
→ It is a dimensionality reduction technique in the domain of Supervised Machine Learning.
→ It is crucial in modeling differences between two groups, i.e., classes.
→ It helps project features in a high-dimensional space in a lower-dimensional space.
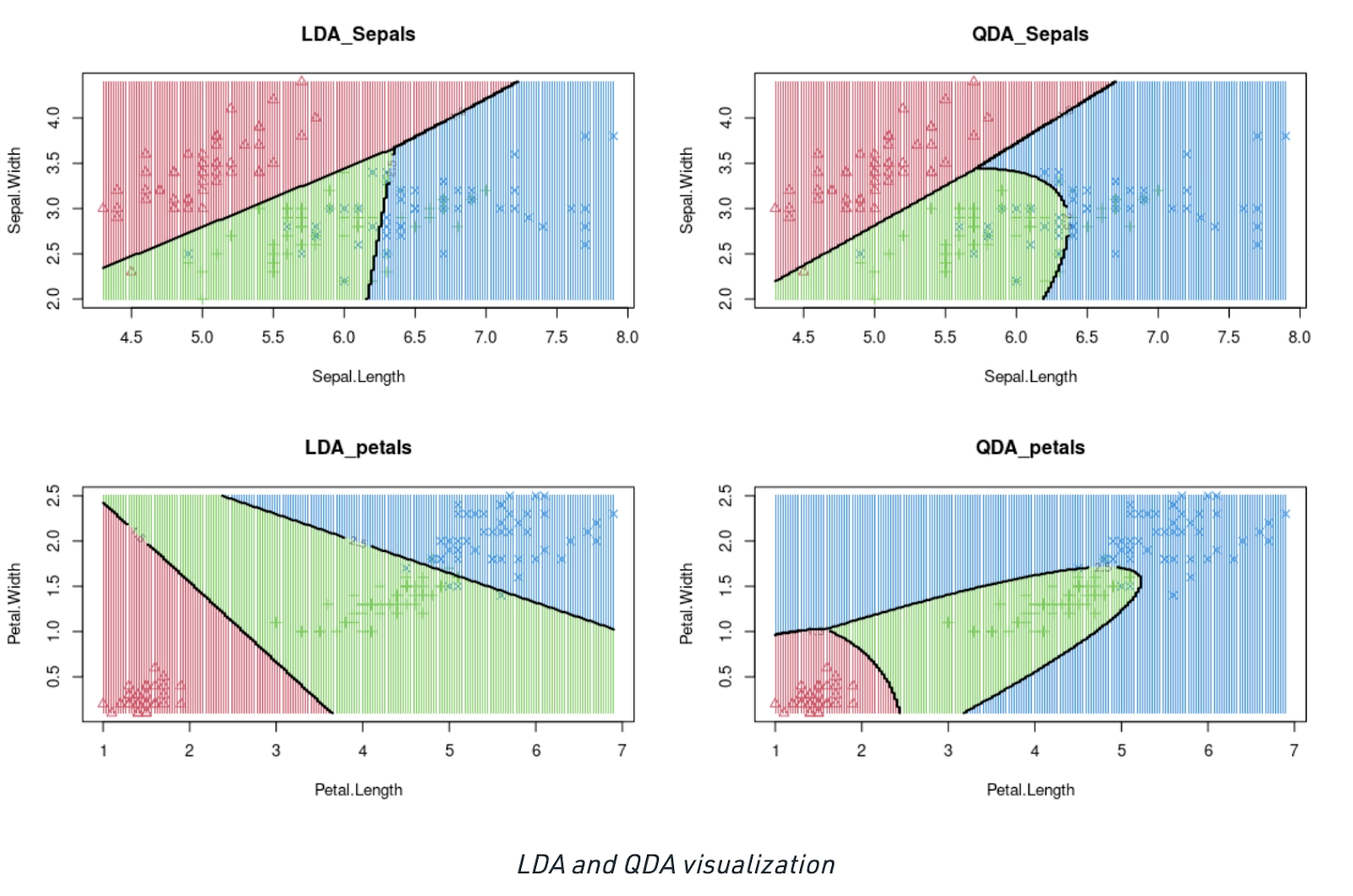
→ Technique - Linear Discriminant Analysis (LDA) is used, which reduced the 2D graph into a 1D graph by creating a new axis. This helps to maximize the distance between the two classes for differentiation.
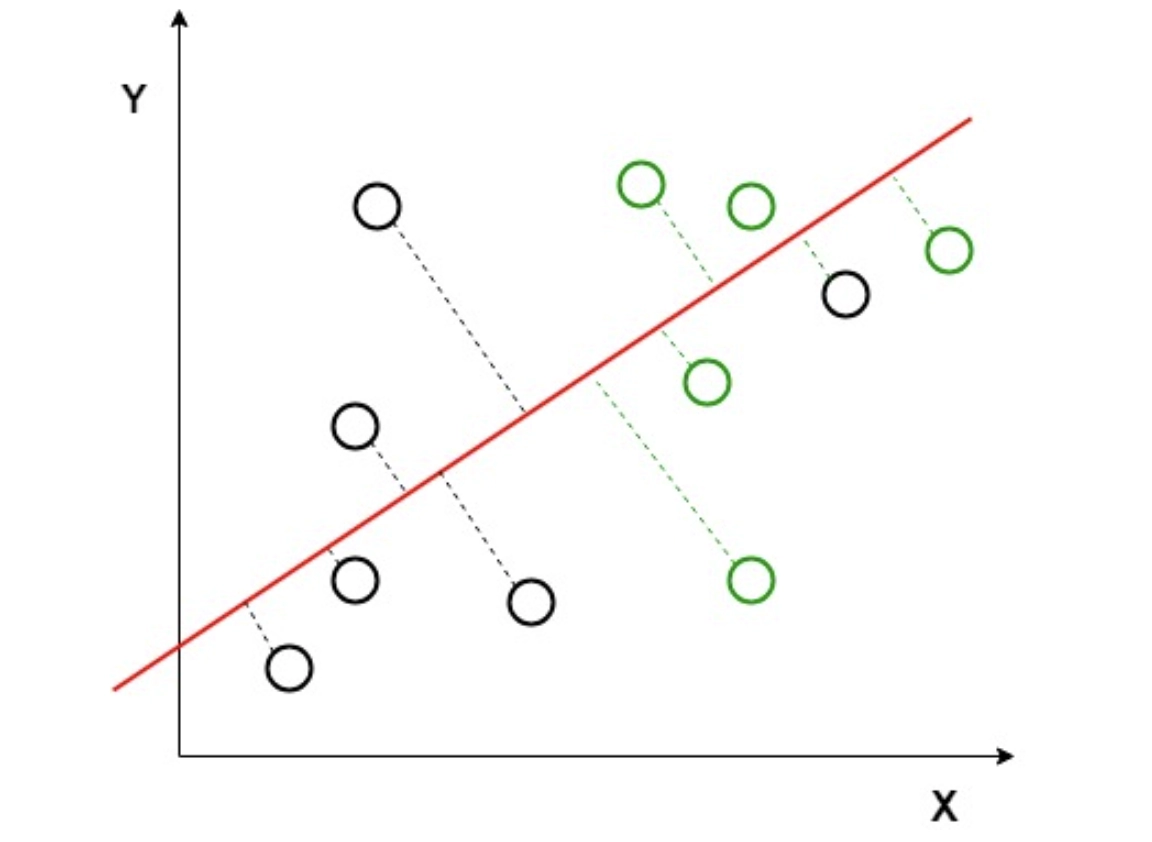
→ In the above graph, we notice that a new axis is created, which maximizes the distance between the mean of the two classes.
→ As a result, variation within each class is also minimized.
→ However, the problem with LDA is that it would fail in case the means of both classes were the same. This would mean that we would not be able to generate a new axis for differentiating the two.
Naive Bayes
→ It is based on the Bayes Theorem and lies in the domain of Supervised Machine Learning.
→ Every feature is considered equal and independent of the others during Classification.
→ Naive Bayes indicates the likelihood of occurrence of an event. It is also known as conditional probability.
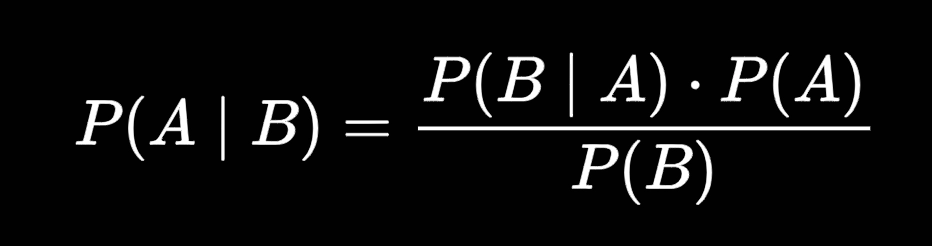
A: event 1
B: event 2
P(A|B): Probability of A being true given B is true - posterior probability
P(B|A): Probability of B being true given A is true - the likelihood
P(A): Probability of A being true - prior
P(B): Probability of B being true - marginalization
However, in the case of the Naive Bayes classifier, we are concerned only with the maximum posterior probability, so we ignore the denominator, i.e., the marginal likelihood. Argmax does not depend on the normalization term.
→ The Naive Bayes classifier is based on two essential assumptions:-
(i) Conditional Independence - All features are independent of each other. This implies that one feature does not affect the performance of the other. This is the sole reason behind the ‘Naive’ in ‘Naive Bayes.’
(ii) Feature Importance - All features are equally important. It is essential to know all the features to make good predictions and get the most accurate results.
→ Naive Bayes is classified into three main types: Multinomial Naive Bayes, Bernoulli Naive Bayes, and Gaussian Bayes.
Logistic Regression
→ It is a very popular supervised machine learning algorithm.
→ The target variable can take only discrete values for a given set of features.
→ The model builds a regression model to predict the probability of a given data entry.
→ Similar to linear regression, logistic regression uses a linear function and, in addition, makes use of the 'sigmoid' function.
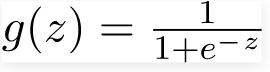
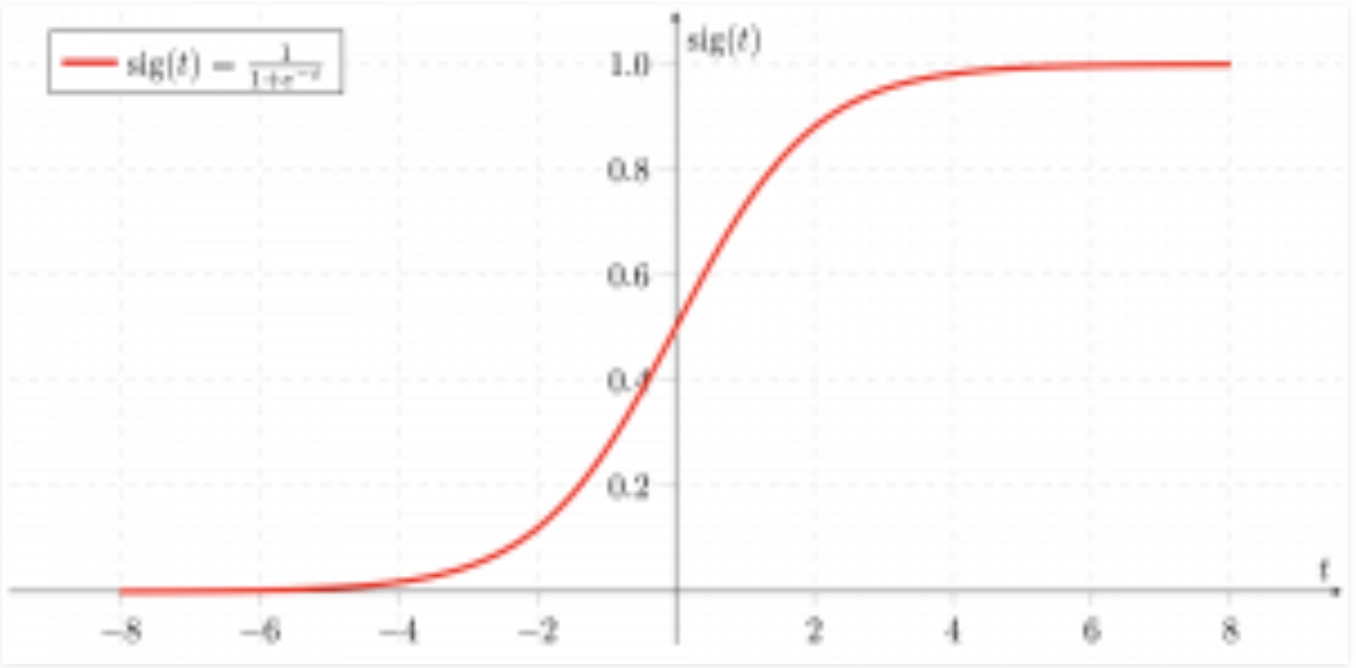
→ Logistic regression can be further classified into three categories:-
- Binomial - target variable assumes only two values since binary. Example: ‘0’ or ‘1’.
- Multinomial - target variable assumes >= three unordered values since multinomial. Example: 'Class A,' 'Class B,' and 'Class C.'
- Ordinal - target variable assumes ordered values since ordinal. Example: ‘Very Good’, ‘Good’, ‘Average, ‘poor’, ‘very poor’.
Support Vector Machine (linear kernel)
→ It is a straightforward supervised machine learning algorithm used for regression/classification.
→ This model finds a hyper-plane that creates a boundary between the various data types.
→ It can be used for binary Classification as well as multinomial classification problems.
→ A binary classifier can be created for each class to perform multi-class Classification.
→ In the case of SVM, the classifier with the highest score is chosen as the output of the SVM.
→ SVM works very well with linearly separable data but can work for non-linearly separable data as well.

 6+ registered
6+ registered 

