Do you think IIT Guwahati certified course can help you in your career?
Introduction
Parsing is one of the Phases of Compiler. In this blog, we are going to discuss types of parsing which are top-down parsers and bottom-up parsers. Then we will discuss LL Parser in Compiler Design and many more.
In computer science, a top-down parser for a constrained context-free language is known as an LL parser (Left-to-right, leftmost derivation). It performs the leftmost derivation of the sentence as it parses the input from Left to Right. Now, deep dive into this blog: LL Parser in Compiler Design.
Parser in Compiler Design
The data from the lexical analysis step is split into smaller parts using a part of the compiler called a parser. Parsing, also known as (syntax analysis), examines text made up of a series of tokens to ascertain its grammatical structure in relation to grammar. It takes tokens as input and outputs a parse tree.
There are two types of commonly used parsing.
Top-down parsing: Top-down parsing refers to the process where the parser builds the parse tree starting with the start symbol and then tries to transform the start symbol into the input.
Bottom-up parsing: Bottom-up parsing attempts to build the parse tree up to the start symbol by starting with the input symbols.
We will see about types of top-down parsing in detail.
Top-Down Parsing
The parse tree is built from the top down. Top-down parsing analyzes the input and builds the parse tree from the root to the leaf. To create a parse tree, the leftmost derivation is used.
Recursive descent parsing and LL parsing are two examples of top-down parsing algorithms. While LL parsing builds a predictive parsing table from a given grammar and uses it to parse the input, recursive descent parsing entails constructing a series of recursive algorithms to recognize the language of a grammar.
There are two types of recursive descent parsing in compiler design.
Back-tracking: The parser must go back to the production it chose if the derivation of the input string fails in one production of a non-terminal, then start constructing the string using a different production of the same non-terminal. Backtracking is the process's term for repeatedly reading through the input string.
Non- back-tracking: With or without employing backtracking, the recursive Descent Technique parses the input to create a parse tree. The associated grammar may employ non-backtracking if it is a left factor. Apredictive parserand an LL parser are examples of non-backtracking methods.
Now let us discuss the main topic; LL Parser in Compiler Design.
LL Parser in Compiler Design
LL parser in compiler design is a predictive parser implementation that uses an implicit stack and parsing table to determine the production that should be used for a non-terminal.
It searches a parsing table created from a specific grammar for the production that should be applied.
It will try to forecast the correct production to extend the non-terminal at the present derivation step if more than one production relates to the same non-terminal. As a result, to build a predictive parser, we need to know which production options to use, given the current input symbol and the non-terminal that has to be extended.
For example
Concerning the productions, the syntax is as follows:
stmt -> if expr then stmt else stmt | while stmt then stmt | begin stmt_list end
The keywords "if,""while," and "begin" then indicate which alternative may be successful if we are looking for a statement.
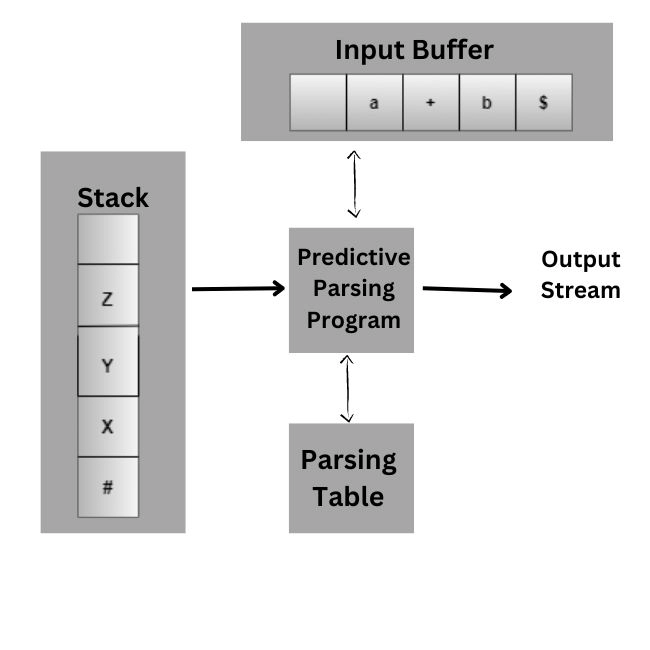
Model of LL Parser in Compiler Design
The three models of LL parser in compiler design are the following:
Input: This contains a string that will be parsed with the end-marker $.
Stack: A predictive parser sustains a stack. It is a collection of grammar symbols with the dollar sign ($) at the bottom.
Parsing table: M[A, S] is a two-dimensional array, where A is a non-terminal, and S is a terminal. With the entries in this table, it becomes effortless for the top-down parser to choose the production to be applied.
LL(1) PARSER
If an LL parser uses k look-ahead tokens to parse a sentence, it is called an LL(k) parser. Because LL grammars, especially LL(1) grammars, are simple to build as parsers, many computer languages are created to be LL(1). The 1 denotes using a single input symbol for forward-looking decisions during each phase of the parsing process.
When LL(k) parsers encounter a non-terminal, they must anticipate which production it will be replaced with. The fundamental LL algorithm begins with a stack comprising [S, $] (top to bottom) and performs the relevant action till finished:
If a non-terminal is at the top of the stack, choose one of its productions as the top by utilizing the following k input symbols (without changing the input cursor), and proceed.
Read the following input token if a terminal is at the top of the stack. Pop the stack and carry on if it's the same terminal. Otherwise, the procedure ends because the parse was unsuccessful.
The procedure is complete if the stack is empty because the parse was successful. (We presume the input's final $ EOF-marker is unique.)
Prime Requirement of LL(1)
The following are the prime requirements for the LL(1) parser:
The grammar must have no left factoring and no left recursion.
FIRST() & FOLLOW()
Parsing Table
Stack Implementation
Parse Tree
Algorithm to Construct LL(1) Parsing Table
Step 1: Verify the prime requirement of LL Parser before moving on to step 2.
Step 2: Perform First() and Follow() calculations on each non-terminal. Let us see these two calculations.
First(): The first terminal symbol is referred to as the First if there is a variable, and we attempt to derive all the strings from that variable.
Follow(): The terminal symbol that follows a variable throughout the derivation process.
Step 3. For each production, like A –> α.
Locate First(α) and enter A -> α for each terminal in First() in the table.
Locate Follow(A) and put an item in the table for each terminal in Follow(A) if First(α) contains epsilon as a terminal.
Make entry A-> ε in the table for the $ if First(ε) includes and Follow(A) contains $ as terminal.
The Non-Terminals will be in the table's rows, and the Terminal Symbols will be in the table's column. The Follow elements will cover all the Grammars' Null Productions, while the First set of elements will cover the rest of the productions.
Let us see an example of an LL(1) parser.
Example
The grammar is given below:
G --> SG'
G' --> +SG' | ε
S --> FS'
S' --> *FS' | ε
F --> id | (G)
Step 1: Each of the properties in step 1 is met by the grammar.
First
Follow
G --> SG'
{ id, ( }
{ $, ) }
G' --> +SG' | ε
{ +, ε }
{ $, ) }
S --> FS'
{ id, ( }
{ +, $, ) }
S' --> *FS' | ε
{ *, ε }
{ +, $, ) }
F --> id | (G)
{ id, ( }
{ *, +, $, ) }
Step 2: Determine first() and follow().
Step 3: The parsing table for the above grammar will be:
id
+
*
(
)
$
G
G -> SG’
G -> SG’
G’
G’ -> +SG’
G’ -> ε
G’ -> ε
S
S -> FS’
S -> FS’
S’
S’ -> ε
S’ -> *FS’
S’ -> ε
S’ -> ε
F
F -> id
F -> (G)
As you can see, all of the null productions are grouped under that symbol's Follow set, while the remaining creations are grouped under its First.
This was all about LL parser in compiler design and its most used types. Now it's time to discuss some frequently asked questions about LL parser in compiler design.
Frequently Asked Questions
What elements makeup parsing?
The grammar, parsing algorithm, and output scheme are a parser's three major building blocks. It has become vital to analyze and assess the benefits and drawbacks of various strategies due to the broad diversity of modern techniques utilized in the automatic syntactic parsing of natural languages.
What are the methods of parsing?
The three main categories of parsing approaches are universal parsing, top-down parsing, and bottom-up parsing, depending on how the parse tree is constructed. Top-down and bottom-up parsing are the two most widely used parsing methods.
What is a lazy parser?
Applications that deploy more code than they need can start up faster and use less memory, thanks to lazy parsing. To prepare both accurately (as per the spec) and rapidly, the preparser must be able to handle variable declarations and references effectively.
Conclusion
As we have come to the end of this blog, let us see what we have discussed so far. In this blog, we have discussed the parser in compiler design. Then we discussed the top-down parsing. After that, we discussed the LL parser in compiler design and its model. In the end, we discussed LL(1) parser, its prime requirements, and the algorithm to construct LL(1) parsing table.
If you like to learn more, you can check out our articles:































 9+ registered
9+ registered 

