Log and log records
- The log is a list of records. Each transaction's log is kept in some form of stable storage so that if a failure happens, it may be retrieved from there.
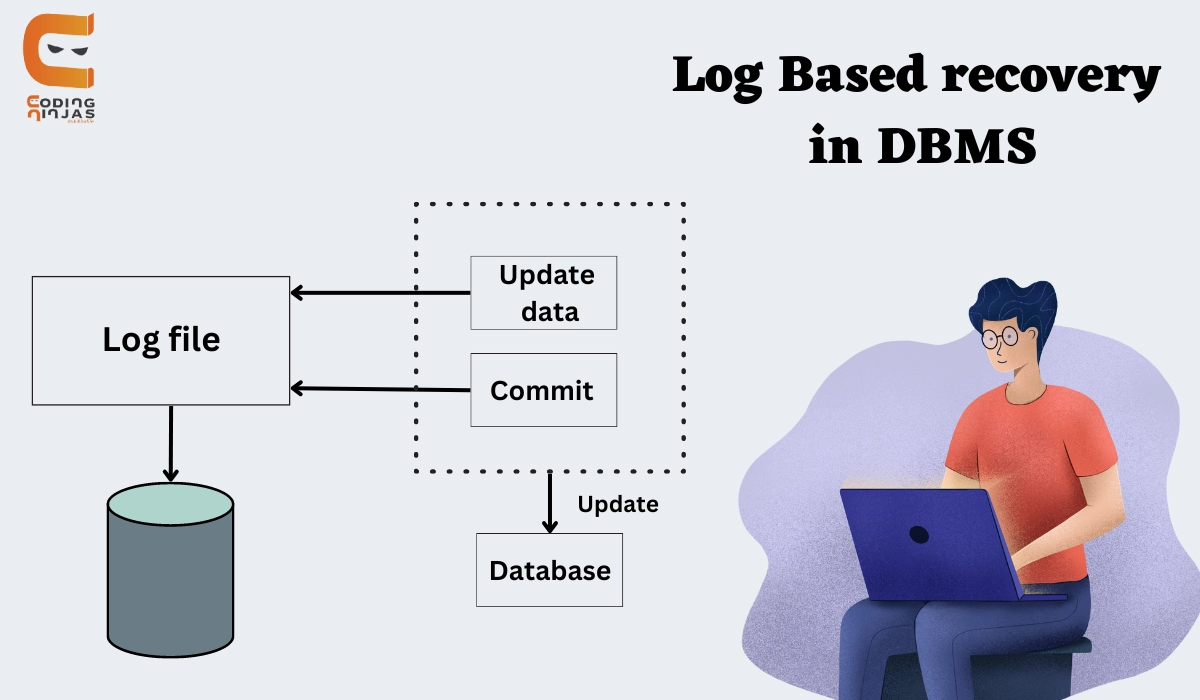
- If the user performs an operation on the database, it will be recorded in the log.
- However, the process of saving logs must be completed before the actual transaction is applied to the database.
The following fields are found in an update log record(represented as <Ti, Xj, V1, V2>):
- Transaction identifier: The transaction identifier is the unique identification of the transaction that performed the write operation.
- Data item: The data item's unique identifier.
- Old value: The value of a data item before the write operation.
- New value: The value of a data item after the write operation.
Other kinds of log records include:
- <Ti start>: This variable holds information about when a transaction Ti begins.
- <Ti commit>: This variable includes information about when a transaction Ti commits.
- <Ti abort>: It includes information about when a transaction Ti aborts.
Undo and Redo Operations
Because the generation of a log record must precede all database changes, the system has both the old value prior to data item modification and the new value that is to be recorded for data item accessible. This enables the system to do redo and undo operations as needed:
- Undo: Using a log record, the data item indicated in the log record is set to its previous value.
- Redo: Using a log record, a new value is assigned to the data item indicated in the log record.
There are two methods for modifying the database:
Deferred database modification
- This approach is used when a transaction does not affect the database until it has been committed.
- All logs are produced and placed in stable storage, and the database is updated when a transaction commits.
Immediate database modification
- This approach is used when a database is modified while the transaction is still ongoing.
- The database is changed instantly after each operation. It follows an actual database change.
Recovery using Log records
When the system crashes, it examines the log to determine which transactions must be undone and which must be redone.
If the log contains the records <Ti, Start> and Ti, Commit> or <Ti, Commit>, Transaction Ti must be redone.
If the log contains the record <Ti, Start> but not the records either <Ti, commit> or <Ti, abort>, then Transaction Ti must be undone.
Use of Checkpoints
When a system crash occurs, the user must review the log. In theory, this information would have to be found by searching the entire log. This method has two significant drawbacks:
- The search procedure takes a long time.
- The majority of the transactions that need to be performed, according to our algorithm, have already written their updates into the database. Although redoing them will not cause any harm, it will make recovery time longer.
Checkpoints are used to reduce this sort of overhead. A checkpoint in the log is represented by a log record of the form <checkpt l>, where l is a list of transactions active at the moment of a checkpoint. When a checkpoint log record is added to the log, all transactions committed before the checkpoint have a <Ti commit> log record preceding the checkpoint record. Any database changes produced by Ti are written to the database either before the checkpoint or as part of the checkpoint itself. As a result, there is no need to do a redo operation on Ti during recovery.
Upon a system crash, the system searches the log to locate the most recent <checkpt l> record. Only transactions in l and any transactions that began execution after the record was recorded to the log need the use of the redo or undo operations. Let us refer to this collection of transactions as T. The same undo and redo rules apply to T as they do in the Recovery Using Log Records section.
It should be noted that the user simply has to review the segment of the log beginning with the last checkpoint log record to determine the set of transactions T and whether a commit or abort record appears in the log for each transaction in T.
Consider the collection of transactions T0, T1,..., T100. Assume the most recent checkpoint occurred during the execution of transactions T67 and T69, but T68 and any transactions with subscripts less than 67 finished before the checkpoint. As a result, only transactions T67, T69,..., T100 must be considered throughout the recovery scheme. Each one must be redone if it has been finished (that is, committed or aborted); otherwise, it was incomplete and must be undone.
How to Perform Log-Based Recovery in DBMS?
Log-based recovery in database management systems (DBMS) is a crucial mechanism for ensuring data integrity and consistency in the event of system failures or crashes. Here's a simplified explanation of how it works:
- Transaction Logging: In DBMS, every transaction that modifies the database is recorded in a log file before the actual changes are applied to the database itself. This log contains a record of all actions performed by transactions, including updates, inserts, and deletes.
- Transaction Commitment: When a transaction is committed, meaning it has successfully completed all its operations, a corresponding entry indicating the transaction's commitment is written to the log. This ensures that even if the system crashes before changes are permanently made to the database, the committed transactions can be identified.
- Checkpointing: Periodically, the system creates checkpoints in the log. A checkpoint is a record that indicates that all changes made up to that point have been permanently written to the database. This helps in reducing the time needed for recovery by limiting the portion of the log that needs to be replayed during the recovery process.
- Recovery Process: In the event of a system failure, the DBMS uses the information in the log to recover the database to a consistent state. It starts by analyzing the log from the most recent checkpoint backward, applying the changes recorded in the log to the database. This process is called "replaying" or "rolling forward" the transactions.
- Transaction Undo: If the recovery process encounters a transaction that was active but not yet committed at the time of the crash, it needs to undo the changes made by that transaction. This involves applying the inverse operations of the uncommitted transaction's actions to restore the database to a consistent state.
- Database Restoration: Once the recovery process completes, the database is restored to a consistent state as of the time of the most recent checkpoint, with all committed transactions applied and any uncommitted transactions undone.
You can also read about the Log based recovery and Checkpoint in DBMS.
Frequently Asked Questions
What is a log-based recovery in DBMS?
The log is a list of records. Each transaction's log is kept in some form of stable storage so that if a failure happens, it may be retrieved from there. If you conduct an operation on the database, it will be noted in the log.
What are a checkpoint and log recovery?
Checkpoint is a process that removes all previous logs from the system and stores them permanently on a storage device. Checkpoint specifies a point in time before which the DBMS was in a consistent state and all transactions had been committed.
Why recovery is needed?
The DBMS must not allow some transaction T actions to be applied to the database while others are not. This is what happens when a transaction fails after performing part of its actions but before completing all of them. Overlays are typically used in embedded systems due to physical memory limitations, internal memory for a system-on-chip, and the lack of virtual memory resources.
Conclusion
- Cheers if you reached here! In this blog, we learned about the Log Based Recovery in DBMS
- We have covered the need for Log Based Recovery and its definition.
- We have also seen it working with an example.
- Further, we saw its drawback and recovery using checkpoints.
On the other hand, learning never ceases, and there is always more to learn. So, keep learning and keep growing, ninjas!
Also Read - Cardinality In DBMS and Recursive Relationship in DBMS
If you need more practice in DBMS and SQL then try these Top 100 SQL Problems.
With this fantastic course from CodingNinjas, you can make learning enjoyable and stress-free.
Good luck with your preparation!






























 8+ registered
8+ registered 

