Do you think IIT Guwahati certified course can help you in your career?
Introduction👨🏫
A string is an essential topic of data structures in perspective to interviews in product-based companies. Advanced concepts related to strings such as suffix tree, Rabin-Karp, and suffix arrays are also asked during interviews frequently. One such exciting problem related to strings, i.e., Longest Common Prefix, can be solved in many ways.
Before moving on to the discussion of this problem, you need to understand the concept of the Suffix Array.
Let us learn its fastest solution in this article, which is implemented using the suffix array.
Given a string ‘S.’ Here we need to find the longest common prefix of any two substrings of string ‘S’ using the suffix array.
Example
Input: S = ”alfalfa”
Output: 4
Explanation: The longest common prefix is of substrings “alfa” and “alfalfa,” where the common prefix is “alfa,” which is of length 4.
Suffix Array
Suffix array of a string store all the integers that represent the starting indices of all the suffixes of the given string when all the suffixes are lexicographically sorted. We can implement the suffix array with the best complexity of O(N * log(N)), where ‘N’ is the string ‘S’ size.
Suppose SUF[] denotes the suffix array for the string ‘S.’
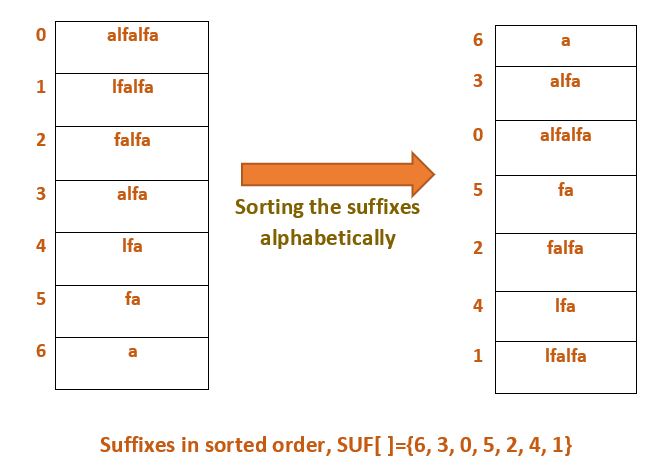
Example: S = “alfalfa”
Suffixes in sorted order are:
Let's solve the above problem with the help of the suffix array.
LCP Array
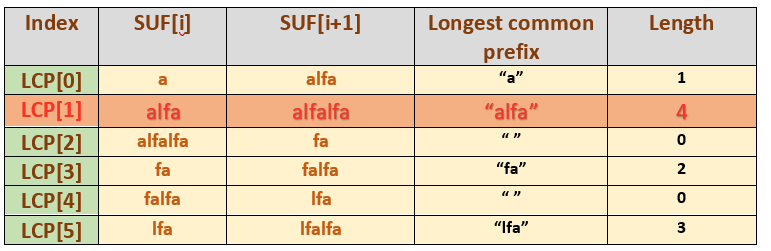
The LCP (Longest Common Prefix) array is an array of size ‘N’ (size of string ‘S’) where LCP[i], for ‘i’ from 0 to N - 1, contains lengths of the longest common prefix between the suffixes SUF[i] and SUF[i+1], in the suffix array.
For the above string S = “alfalfa,” suf[] = {6, 3, 0, 2, 4, 1}, so the LCP will be defined as follows:
LCP[0] = 1, the longest common prefix between strings “a” and “alfa” is “a”
LCP[1] = 4, the longest common prefix between strings “alfa” and “alfalfa” is “alfa”
LCP[2] = 0, the longest common prefix between strings “alfalfa” and “fa” is “”
LCP[3] = 2, the longest common prefix between strings “fa” and “falfa” is “fa”
LCP[4] = 0, the longest common prefix between strings “falfa” and “lfa” is “”
LCP[5] = 3, the longest common prefix between strings “lfa” and “lfalfa” is “lfa”
With the LCP array, just by finding the maximum element of the LCP array we can find the longest common prefix for the string ‘S.’ Thus, the longest common prefix for the string S = “afalfa” will be 4.
Let us understand the construction of the LCP array below.
Kasai’s Algorithm (Without Additional Memory)
For the suffix starting at index ‘i’, LCP is ‘len’. Now, the LCP for the suffix beginning at index ‘i +1’ will be at least ‘len - 1’ if ‘len’ is greater than zero. It is because we are removing the first matching character from both the suffix strings, which decreases the matching prefix characters for the suffixes by one.
For Example, in the above-mentioned string ‘S’ = “alfalfa”. For the suffix starting at index 0, which is “alfalfa”, the LCP is 4, and therefore for the suffix starting at index 1, which is “lfalfa”, the LCP will be ‘4 - 1’ i.e., 3.
Algorithm
First, we will generate the suffix array with the help of the function genSuffixArr().
Then, we will implement the function kasaiAlgo() for the Kasai algorithm.
In function kasaiAlgo(), we will first find the LCP array with the help of the suffix array as discussed above in the ‘basis’ section.
Finally, we will find out the maximum element in the LCP array and print it as the longest common prefix of 2 substrings of the string ‘S.’
The implementation of the above algorithm.
Implementation in C++
// Program to find the longest common prefix with the help of the suffix array.
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int n, len;
// Defining the structure of a suffix element.
typedef struct sufElement
{
int idx;
int rank[2];
} suffix;
// Comparator for sorting the suffix array.
int compare(suffix &suf1, suffix &suf2)
{
return (suf1.rank[0] == suf2.rank[0]) ? (suf1.rank[1] < suf2.rank[1] ? 1 : 0) : (suf1.rank[0] < suf2.rank[0] ? 1 : 0);
}
// Function used to generate the suffix array.
vector<int> genSuffixArr(string &s)
{
// Array to be used for storing suffixes.
suffix suf[n];
// Storing the suffixes in the array.
for (int i = 0; i < n; i++)
{
suf[i].idx = i;
suf[i].rank[0] = s[i] - 'a';
suf[i].rank[1] = ((i + 1) < n) ? (s[i + 1] - 'a') : -1;
}
// Sorting the array of suffixes according to the first two letters.
sort(suf, suf + n, compare);
// Vector to get the index stored in SUF[] from the initial index.
vector<int> vec(n);
// Loop to sort the suffixes according to the first 4 characters, then 8 characters, and so on.
for (int len = 4; len < 2 * n; len = len * 2)
{
// First suffix initialization with rank 0.
int rk = 0, preRank = suf[0].rank[0];
suf[0].rank[0] = rk;
vec[suf[0].idx] = 0;
// Giving new ranks to suffixes.
for (int i = 1; i < n; i++)
{
// Assigning the same rank to the suffixes having both ranks equal to the previous suffix.
if (suf[i].rank[0] == preRank && suf[i].rank[1] == suf[i - 1].rank[1])
{
preRank = suf[i].rank[0];
suf[i].rank[0] = rk;
}
else
{
// Incrementing rank and assign to the current suffix.
preRank = suf[i].rank[0];
suf[i].rank[0] = ++rk;
}
vec[suf[i].idx] = i;
}
// With the help of VEC, assigning the next rank to all suffixes.
for (int i = 0; i < n; i++)
{
int nextIdx = suf[i].idx + len / 2;
suf[i].rank[1] = (nextIdx < n) ? suf[vec[nextIdx]].rank[0] : -1;
}
// Sort the suffixes according to the first k characters
sort(suf, suf + n, compare);
}
// Preparing the suffix array by storing indices of all sorted suffixes.
vector<int> sufArray;
for (int i = 0; i < n; i++)
sufArray.push_back(suf[i].idx);
// Finally returning the suffix array.
return sufArray;
}
// Function to return the LCP array with the help of Kasai Algorithm.
vector<int> kasaiAlgo(string &s)
{
// Generating the suffix array.
vector<int> suf = genSuffixArr(s);
// Vector to store the lcp array.
vector<int> lcp(n, 0);
// Storing the inverse of the suffix array to get the next suffix string from the suffix array.
vector<int> tmpSuf(n, 0);
for (int i = 0; i < n; i++)
tmpSuf[suf[i]] = i;
// Initialization of length of lcp.
len = 0;
// Calculating the lcp array with the help of the suffix array.
for (int i = 0; i < n; i++)
{
if (tmpSuf[i] == n - 1)
{
len = 0;
continue;
}
int idx = suf[tmpSuf[i] + 1];
while (i + len < n && idx + len < n && s[i + len] == s[idx + len])
len++;
lcp[tmpSuf[i]] = len;
if (len > 0)
len--;
}
// Finally returning the lcp array.
return lcp;
}
int main()
{
// Input string S.
string s;
cin >> s;
// Storing the size of string 'S'.
n = s.length();
// Storing the lcp array with the help of the Kasai algorithm.
vector<int> lcp = kasaiAlgo(s);
// Final answer storing the maximum element of the cp array.
int ans = *max_element(lcp.begin(), lcp.end());
// Output the answer.
cout << "The longest common prefix in the string is: " << ans;
return 0;
}
Input
alfalfa
Output
Complexity Analysis
Time Complexity
It is O(N * log(N)), where 'N' is the size of string 'S'
Explanation: The time complexity of the generation of suffix array with the help of genSuffixArr() function takes O(N * log(N)) total time, whereas, in the function kasaiAlgo(), the loop used to generate the LCP array takes a total of O(N) time. Thus the most time taking operation of the above algorithm is suffix array generation, concluding that O(N*log(N)) is the total time complexity.
Space Complexity
It is O(N), where 'N' is the size of string 'S.'
Explanation: Vectors are used to store suffix arrays, and the LCP array consumes a total of O(N) space, whereas string 'S' also consumes a space of O(N). Thus the space complexity of the above algorithm is O(N).
For the given strings, we want to compute the longest common prefix (LCP) of two arbitrary suffixes with positions i and j. Here we will be discussing the Divide and conquer Approach. The method described here uses additional memory.
This approach is to divide the given array of strings into various subproblems and merge them to get the LCP(S1..SN).
Divide the provided array into two halves first. Then, in turn, divide the obtained left and right array into two parts and recursively divide them until no further division is possible.
Algorithm
To apply the observation above, we use the divide and conquer technique, where we split the LCP(Si… Sj) problem into two subproblems, LCP(Si… Smid) and LCP(Smid+1…Sj), where mid is (i + j)/2
We use their solutions lcpLeft and lcpRight to construct the solution of the main problem LCP(Si…Sj)
To accomplish this, we compare one by one the characters of lcpLeft and lcpRight till there is no character match.
The found common prefix of lcpLeft and lcpRight is the solution of the LCP(Si…Sj)
Implementation in C++
#include <algorithm>
#include <iostream>
#include <bits/stdc++.h>
using namespace std;
//Comparing the strings to find the common prefix
string CommonPrefixUtil(string Str1, string Str2)
{
string res;
int n = Str1.length(), m = Str2.length();
for (int i=0, j=0; i<=n-1 && j<=m-1; i++,j++)
{
if (Str1[i] != Str2[j])
break;
res.push_back(Str1[i]);
}
return (res);
}
/* Dividing the input string into low and high as per the divide and conquer rule */
string LongestCommonPrefix(string S[], int low, int high)
{
if (low == high)
return (S[low]);
if (high > low)
{
int mid = low + (high - low) / 2;
string Str1 = LongestCommonPrefix(S, low, mid);
string Str2 = LongestCommonPrefix(S, mid+1, high);
return (CommonPrefixUtil(Str1, Str2));
}
}
int main() {
//Scanning the input
string arr[3];
cout<<"Enter the elements:"<<endl;
for(int x = 0; x<3;x++)
{
cin>>arr[x];
}
cout<<"\nString array:\n";
for (int x = 0; x< 3; x++)
cout << arr[x] << "\n";
int len = LongestCommonPrefix(arr, 0, 2).length();
int arrSize = sizeof(arr)/sizeof(arr[0]);
cout <<"Longest Common Prefix in the strings is" <<LongestCommonPrefix(arr, 0, 2) <<" and length is "<<len<< endl;
return 0;
}
Input
Codingninjas
Coding
codingrangers
Output
Complexity Analysis
Time Complexity
O(K), where K is the sum of all the characters in all strings.
Space Complexity
O(M log N), as there are log N recursive calls, and each needs a space of M.
Frequently Asked Questions
What do you understand by suffix array?
Suffix array of a string store all the integers that represent the starting indices of all the suffixes of the given string when all the suffixes are lexicographically sorted.
What is the time complexity of Kasai's algorithm?
The time complexity of Kasai’s algorithm is O(N), where N is the length of the string. It takes linear time to create the suffix tree.
What do you mean by auxiliary space?
Auxiliary space is the additional space required by the program other than the input and output data space. It is one part of the entire space complexity of an algorithm.
What is the longest prefix array?
The longest common prefix(LCP) for an array of strings is the common prefix between the two most dissimilar strings.
Differentiate between "s" and 's'?
In C++, Single quotes are used to define single characters, and double quotes are used to define strings so the compiler will consider ‘s’ as a character and “s” as a string.
Conclusion
In the above article, we have learned to solve a significant problem, 'Longest Common Prefix', with the help of an advanced topic related to strings, 'Suffix Array'. We have also learned an important algorithm called 'Kasai's Algorithm' with the use of which we can find the LCP array for a given string 'S'.
Find more such exciting algorithms in our library section, and solve interesting questions on our practice platform Coding Ninjas Studio. Keep Learning.






























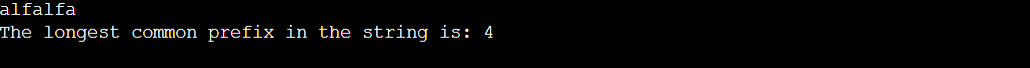



 9+ registered
9+ registered 

