Do you think IIT Guwahati certified course can help you in your career?
Introduction
Operations on an array of strings is an important area to master when it comes to programming. And in this blog, we will be discussing a trie-based solution to find the longest common prefix in an array of strings, which is one of the most frequently asked questions in coding interviews. You can practice the question at the Coding Ninjas Studio and return to this blog if you feel stuck.
Understanding the Problem
We are given an array consisting of ‘N’ strings. Our task is to find the longest common prefix among all these strings. If there is no common prefix, we can simply return an empty string.
But what does prefix actually mean?
A substring formed after eliminating some or all characters from the end of a string is referred to as a prefix. For example, “cod”, “coding”, ”co” are all prefixes of the string “codingninjas”.
Let’s take an example to understand better.
Given array = [“coding”, ”codezen”, ”codestar”, ”coders”]
We can observe that the substrings “c”, “co”, and “cod” appear as prefixes in all the strings, but the substring “cod” is the longest among these all. Hence, the longest common prefix for the above array of strings is “cod”.
Now let’s see how we can solve the problem.
Approach
In this method, we'll use Trie to store all of the strings and then utilize it to find the longest common prefix.
Before going into detail, let’s first discuss what a Trie is and what its structure is.
So a trie is a tree-like Data Structure that contains the following as its data members.
'VAL' is used to hold the character in the TrieNode class.
The ‘CHILD’ pointers corresponding to each character are stored in an array CHILD of size 26.
'CHILDCOUNT' counts the number of CHILD nodes.
'ENDOFWORD' is a variable that stores whether or not the character is the last character of the word.
Trie's nodes are made up of many branches. Each branch represents a different essential character. By setting 'ENDOFWORD' to true, we can identify the last node of each word.
But why are we using Tries?
To solve this problem using a naive technique, we'd have to match each word's prefix with the prefix of every other word in the dictionary and record the highest value. Now, this would be an expensive procedure as we are performing searches repetitively. Tries are a significantly more efficient technique to handle this problem as it does not perform searching repetitively.
.
Now let’s see how we are going to solve the problem using Tries.
At first, store all the given strings in the Trie using the insert() function (discussed below).
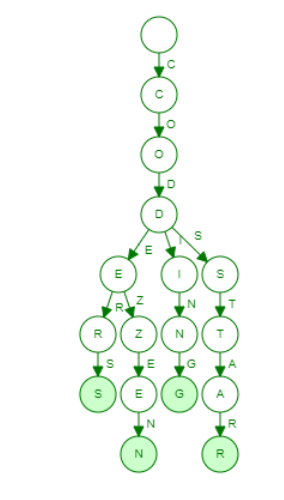
If we insert the strings, “coding”, ”codezen”, ”codestar”, ”coders” in the trie. The trie structure will look like this:
Visual Representation of Trie
To find the longest common prefix, we'll start with the Trie's root node and see if it has only one CHILD. If the node meets this requirement, it will be included in our longest common prefix, and we will move ahead in the trie. At any moment, if the node has more than one CHILD or the value of ‘'ENDOFWORD'’ is true, then we will stop.
Now, this all seems a bit confusing. How will we insert it? How to search for it? Don’t worry. We will discuss the complete algorithm in detail.
Algorithm
Defining TrieNode class:
A variable 'VAL' is used to hold the character in the TrieNode class.
The CHILD pointers corresponding to each character are stored in an array, CHILD of size 26. Initially, all the pointers will be set to NULL.
A 'CHILDCOUNT' is a variable that counts the number of CHILD nodes. Initially set 'CHILDCOUNT' to zero.
The 'ENDOFWORD' is a variable that stores whether or not the character is the last character of the word. By default, set the value of 'ENDOFWORD' to False.
insert(root, word) function definition:
Declare a variable, ‘CURR’, and initialize it with root.
Iterate the string, word using variable 'IDX' from 0 to (word length - 1):
Set the difference between word['IDX'] and ‘a' to ‘DIFF’ (variable for storing difference).
If the character word['IDX'] does not already exist as a CHILD in the currentword ('CURR'->CHILD[diff]==NULL), add it and increase the currentword's 'CHILDCOUNT' by one.
Set currentword to be currentword's CHILD[diff].
Set currentword’s 'ENDOFWORD' to true.
longestCommonPrefix() function:
Declare a root TrieNode.
Using the insert() function that accepts an array ‘ARR’’ as a parameter, fill the Trie with all the strings from the array ‘’.
Create a string, answer to keep track of the longest common prefix.
Make a string prefix declaration. arr[0] is the prefix to use.
We shall attempt to determine whether or not a prefix is a frequent prefix.
Iterate ‘'IDX'’ from 0 to prefix length -1:
If the root's ‘'CHILDCOUNT'’ equals one.
prefix['IDX'] should be added to the answer.
Set the difference between the prefix['IDX'] and ‘a' to diff.
Set root as the root's CHILD[diff].
Otherwise, if the root's ‘'CHILDCOUNT'’ is not equal to 1,
We're going to break the cycle.
If the root's ‘'ENDOFWORD'’ is true,
the search is complete, and the loop will be broken.
Return answer corresponding to the longest common prefix.
After this overwhelming algorithm, it’s time to implement the above words into code. So let’s see the code for the above problem in C++.
Program
#include <iostream>
#include<vector>
using namespace std;
class TrieNode
{
public:
char val;
vector<TrieNode*> child;
int childCount;
bool endOfWord;
TrieNode(char val)
{
this->val = val;
child.resize(26, NULL);
childCount = 0;
endOfWord = false;
}
~TrieNode()
{
for(int i = 0; i < 26; i++)
{
if(child[i] != NULL)
{
delete child[i];
}
}
}
};
void insert(TrieNode* root, string &word)
{
TrieNode* cur = root;
for(int idx = 0; idx < word.size(); ++idx)
{
int diff = word[idx] - 'a';
// If the child[diff] of cur is an empty node.
if (cur->child[diff] == NULL)
{
cur->child[diff] = new TrieNode(word[idx]);
cur->childCount += 1;
}
cur = cur->child[diff];
}
// Marking the endOfWord of the last character as true.
cur->endOfWord = true;
}
string longestCommonPrefix(vector<string> &arr, int n)
{
// Declaring the Trie's root node.
TrieNode* root = new TrieNode(' ');
// Inserting each word into Trie.
for(int i = 0; i < arr.size(); i++)
{
string word = arr[i];
insert(root, word);
}
// A string to store the longest common prefix.
string answer = "";
// We will check if string prefix is common in all strings or not.
string prefix = arr[0];
for(int idx = 0; idx < prefix.size(); idx++)
{
// Check if root has only one child.
if (root->childCount == 1)
{
answer += prefix[idx];
int diff = prefix[idx] - 'a';
root = root->child[diff];
}
else
{
break;
}
// Check if endOfWord of root is true.
if (root->endOfWord)
{
break;
}
}
delete root;
return answer;
}
int main() {
int n;
cin >> n;
vector<string>arr(n);
// Taking the input.
for(int i=0; i<n; i++)
cin >> arr[i];
// Printing the answer.
cout<< longestCommonPrefix(arr, n);
return 0;
}
You can also try this code with Online C++ Compiler
O(M * N), where ‘N’ is the number of strings in the array, and ‘M’ is the maximum length of the string present in the array.
We will insert all the strings into the trie, and each insertion takes O(M) time. So the total time taken is O(M * N). Also, it takes O(M) time to find the longest common prefix. Hence, the overall time complexity is O(M * N + M) = O(M * N).
Space Complexity
O(26 * N * M), where ‘N’ is the number of strings in the array, and M is the maximum length of the string present in the array.
At every node, the maximum size of the ‘CHILD’ vector would be 26 (because of 26 alphabets). Since there can be at most N * M nodes, therefore O(26 * N * M) space is required to store all strings into the trie. Hence, the overall space complexity is O(26* N * M),
Key Takeaways
I hope you have learned something new and have mastered the art of solving the problem using Trie by inserting elements and then searching them. But learning never stops, and there is a lot more to learn.
So head over to our practice platform Coding Ninjas Studio to practice top problems, attempt mock tests, read interview experiences, and much more. Till then, Happy Coding!































 8+ registered
8+ registered 

