



























Introduction
This blog will discuss the various approaches to solve the Longest Repeating Subsequence problem. Before jumping into the problem, let’s first recall what a subsequence is and then understand the Longest Repeating Subsequence problem.

A subsequence of a string is generated by deleting zero, one, or more characters of the original string without disturbing the relative positions of the remaining characters.
In this problem, we will be given a string. We have to find the length of the longest subsequence occurring at least two times (i.e., the subsequence is repeated in the given string) in the given string such that the two subsequences shouldn’t contain any character with the same index in the original string.
Let’s take an example to understand it further:
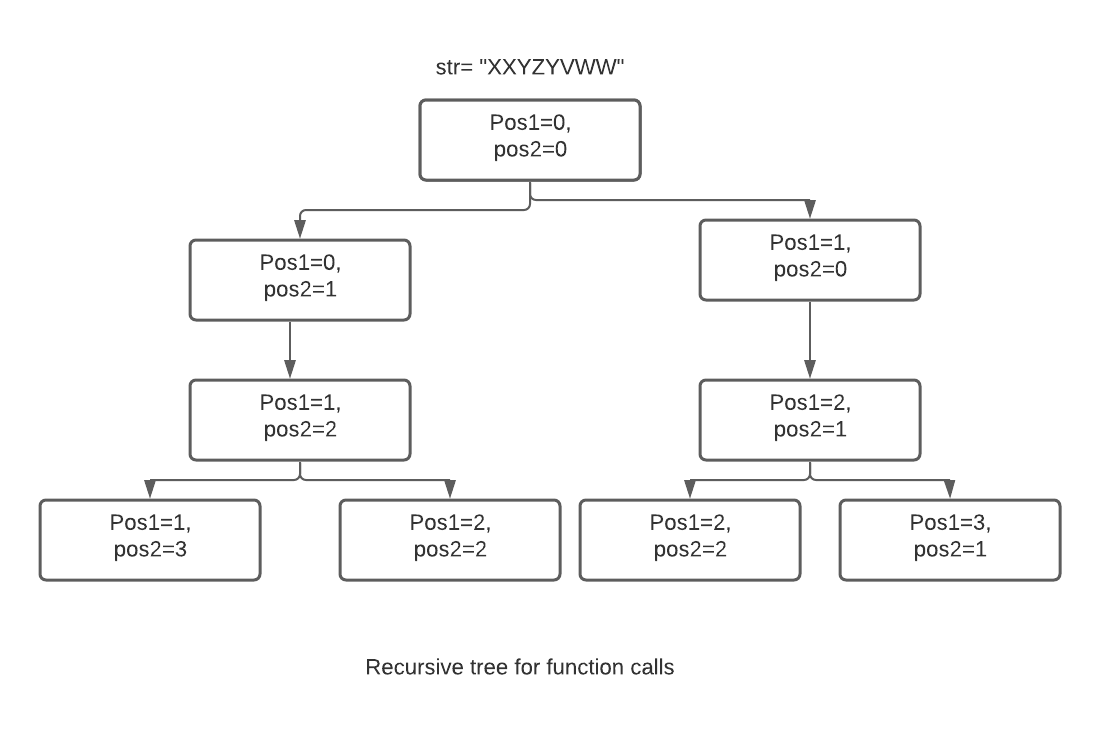
Let the given string be S= “XXYZYVWW” and assume 0-based indexing.
In the above string, we can see that the repeating subsequences are ‘X,’ ‘Y,’ and ‘W,’ “XYW.” So, the longest repeating subsequence will be “XYW,” and the length of the longest Repeating Subsequence will be 3. We can see that there are two occurrences of the subsequence “XYZ,” one will be the subsequence formed by the 0th, 2nd, and 6th characters (shown in blue color in the table below), and the other will be the subsequence formed by 1st, 4th, and 7th characters (shown in red color in the table below).
X | X | Y | Z | Y | V | W | W |
If we understand this question carefully, we can see that this question is just a variation of the Longest Common Subsequence Problem (LCS). Here, we have to find the length of the longest common subsequence of S and S where S is the given string, with the condition that while checking for the same characters in the two strings, we have to take care that the two same characters shouldn’t be at the same index in the given string.
Brute Force Approach
Let’s assume that the given string is S, and we have to find the Longest Repeating Subsequence in S. As discussed above, this problem is a modification of the Longest Common Subsequence Problem. Now this problem is reduced to find the LCS (S, S) with the condition that not any character in the resulting subsequence should be at the same index in both the S, where LCS (s1, s2) is the function to find the length of the longest common subsequence of the two strings s1 and s2.
So, longestRepeatingSubsequence(S) = LCS (S, S) with a restriction that the resulting subsequence shouldn’t contain any character with the same index in their corresponding original string.
We can understand this by taking an example:
Let S= “XXYZYVWW”
LCS(S, S) = S, as the whole string is the same but if we consider the restriction that is written above then, the two ‘X’s shown in red, two ‘Y’s shown in blue and two ‘W’s shown in orange will be in the common subsequence from the two strings. Thus the LCS(S, S) with the condition that not any character in the resulting subsequence should be at the same index in both the S, will be “XYW”. We can see that each character in “XYW” is at different indexes in both the S as shown below.
S= “XXYZYVWW”
S= “XXYZYVWW”
Thus the code for this problem will be similar to the LCS problem. We will find LCS(S, S) with the above described condition. So, we need to consider each character in the two strings one by one. (Please note that the two strings are same here)
So, on considering one by one each character in the two strings, two situations will arise:
- The two characters are identical and are not occurring at the same index in their respective strings.
- The two characters either occur at the same index in their respective strings or differ.
If the first condition arises, we will increase the longest repeating subsequence by one and move to the next character of both strings. If the second condition occurs, we will take the maximum of the two cases - one by moving to the next character in the first string and the other by moving to the next character in the second string.
Algorithm
Step 1. Create a recursive function ‘longestRepeatingSubsequence()’ that will accept the below parameters -
- ‘str’: The given string for which we have to calculate the length of the longest repeating subsequence.
- ‘n’: Length of the given string
- ‘pos1’: The variable denoting the current character of ‘str1’.
- ‘pos2’: The variable denoting the current character of ‘str2’.
Step 2. Then write the base case of the recursive function i.e., if ‘pos1’ or ‘pos2’ reaches the end of the string, then we can’t add more characters to the longest repeating subsequence, so return 0.
Step 3. Now check for the two conditions described in the brute force approach section and do accordingly.
- C++
C++
#include <bits/stdc++.h>
using namespace std;
int longestRepeatingSubsequence(string str, int pos1, int pos2, int n)
{
/*
base case
if pos1 or pos2 reaches n, it means there are no further characters
to consider, so return 0
*/
if(pos1 == n || pos2 == n) return 0;
/*
If the two characters are equal and not occurring at the same index,
then increase the length of the longest repeating subsequence by 1
*/
if(pos1 != pos2 && str[pos1] == str[pos2]) return 1+longestRepeatingSubsequence(str, pos1 + 1, pos2 + 1, n);
else return max(longestRepeatingSubsequence(str, pos1 + 1, pos2, n), longestRepeatingSubsequence(str, pos1, pos2 + 1, n));
}
int main()
{
string str="XXYZYVWW";
cout<<"The length of the Longest Repeating Subsequence in the given string is: "<<longestRepeatingSubsequence(str, 0, 0, 8)<<endl;
return 0;
}
Output:
The length of the Longest Repeating Subsequence in the given string is: 3Algorithm Complexity:
Time Complexity: O(2 ^ N)
In every recursive call ‘longestRepeatingSubsequence()’, we are making two more calls to the same function, so calls are increasing at a rate of 2 until ‘pos1’ or ‘pos2’ reaches N. There will be, at most, ‘2 ^ N’ calls in this code. Therefore the overall time complexity will be O(2 ^ N), where ‘N’ is the length of the given string.
Space Complexity: O(1)
As we are using constant space, the overall space complexity will be O(1).
Also check out - Substr C++


 9+ registered
9+ registered 

